
基于Scrapy框架的微博评论爬虫实战

之前写过的微博爬虫是基于Requests的,今天来跟大家分享一下,基于Scrapy的微博爬虫应该怎么写。
01
Scrapy简介
首先,我们需要对Scrapy框架有一个简单的了解,不然在你书写代码的时候会非常的麻烦。
01
安装
使用pip对Scrapy进行安装,代码如下:
pip install scrapy
02
创建项目
安装好Scrapy框架之后,我们需要通过终端,来创建一个Scrapy项目,命令如下:
scrapy startproject weibo创建好后的项目结构,如下图:
这里我们来简单介绍一下结构中我们用到的部分的作用,有助于我们后面书写代码。
spiders是存放爬虫程序的文件夹,将写好的爬虫程序放到该文件夹中。items用来定义数据,类似于字典的功能。settings是设置文件,包含爬虫项目的设置信息。pipelines用来对items中的数据进行进一步处理,如:清洗、存储等。
02
数据采集
经过上面的简单介绍,我们现在对Scrapy框架有了简单的了解,下面我们开始写数据采集部分的代码。
01
定义数据
首先,我们对数据存储的网页进行观察,方便我们对获取数据进行定义
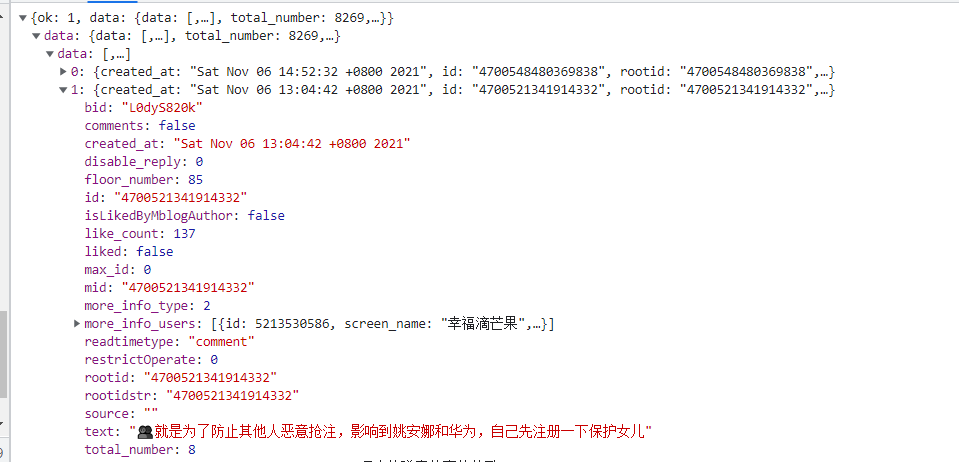
通过对网页中数据存储的形式进行观察后,items.py中对数据的定义方式为:
data = scrapy.Field()
02
编辑爬虫
接下来我们在spiders文件夹里面创建一个weibo.py爬虫程序用以书写请求的爬虫代码
代码如下:
import scrapy
class WeiboSpider(scrapy.Spider):
name = 'weibo' #用于启动微博程序
allowed_domains = ['m.weibo.cn'] #定义爬虫爬取网站的域名
start_urls = ['https://m.weibo.cn/comments/hotflow?id=4700480024348767&mid=4700480024348767&max_id_type=0'] #定义起始网页的网址
for i in res['data']['data']:
weibo_item = WeiboItem()
weibo_item['data'] = re.sub(r'<[^>]*>', '', i['text'])
# start_url = ['https://m.weibo.cn/comments/hotflow?id=4700480024348767&mid=4700480024348767&'+str(max_id)+'&max_id_type=0']
yield weibo_item #将数据回传给items
03
遍历爬取
学过Requests对微博评论进行爬虫的朋友应该知道,微博评论的URL构造方式,这里我直接展示构造代码:
max_id_type = res['data']['max_id_type']
if int(max_id_type) == 1:
new_url = 'https://m.weibo.cn/comments/hotflow?id=4700480024348767&mid=4700480024348767&max_id=' + str(
max_id) + '&max_id_type=1'
else:
new_url = 'https://m.weibo.cn/comments/hotflow?id=4700480024348767&mid=4700480024348767&max_id=' + str(
max_id) + '&max_id_type=0'
02
数据存储
光爬取下来数据是不行的,我们还需要对数据进行存储,这里我采用的是csv文件,来对评论数据进行存储,代码如下:
class CsvItemExporterPipeline(object):
def __init__(self):
# 创建接收文件,初始化exporter属性
self.file = open('text.csv','ab')
self.exporter = CsvItemExporter(self.file,fields_to_export=['data'])
self.exporter.start_exporting()
03
程序配置
光写上面的代码是无法爬取到评论的,因为我们还没有对整个程序进行有效的配置,下面我们就在settings.py里面进行配置。
01
不遵循robots协议
需要对robts协议的遵守进行修改,如果我们遵循网页的robots协议的话,那无法进行爬取,代码如下:
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
02
使用自定义cookie
我们知道,想要爬取微博评论,需要带上自己的cookie用以信息校验,因为我们的cookie是在headers中包裹着的,所以我们需要将COOKIES_ENABLED改为False,代码如下:
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
03
打开管道
想要进行数据存储,还需要在配置中,打开通道,用以数据传输,代码如下:
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'weibo.pipelines.CsvItemExporterPipeline': 1,
'weibo.pipelines.WeiboPipeline': 300,
}
04
启动程序
我们在spiders同级的的目录下创建一个wb_main.py文件,便于我们在编辑器中启动程序,代码如下:
from scrapy import cmdline
#导入cmdline模块,可以实现控制终端命令行。
cmdline.execute(['scrapy','crawl','weibo'])
#用execute()方法,输入运行scrapy的命令。
05
总结
1. 本文详细的介绍了,如何用Scrapy框架来对微博评论进行爬取,建议大家动手实操一下,便于理解。
2. 本文仅供学习参考,不做它用。
推荐阅读:
入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径
干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影
趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!
AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影
小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|
年度爆款文案
点阅读原文,看200个Python案例!
