
抓取用户发布的所有微博的评论
点击上方 月小水长 并 设为星标,第一时间接收干货推送
根据微博话题爬虫或者微博用户爬虫抓取保存的微博 csv 文件,里面保存的是一条条微博,批量爬取评论就是根据这些微博的 ID,抓取这些他们的评论。
之前根据话题爬虫结果,批量抓取话题微博的评论,在【B 站视频教程】抓取用户微博和批量抓取评论 已经有详细说明,今天说的是根据用户爬虫的保存结果,批量抓取保存用户微博的评论。
如果不知道如何抓取指定用户的微博,可以参见 一个爬取用户所有微博的爬虫,还能断网续爬那种,具体操作流程可以看 B 站配套视频教程。
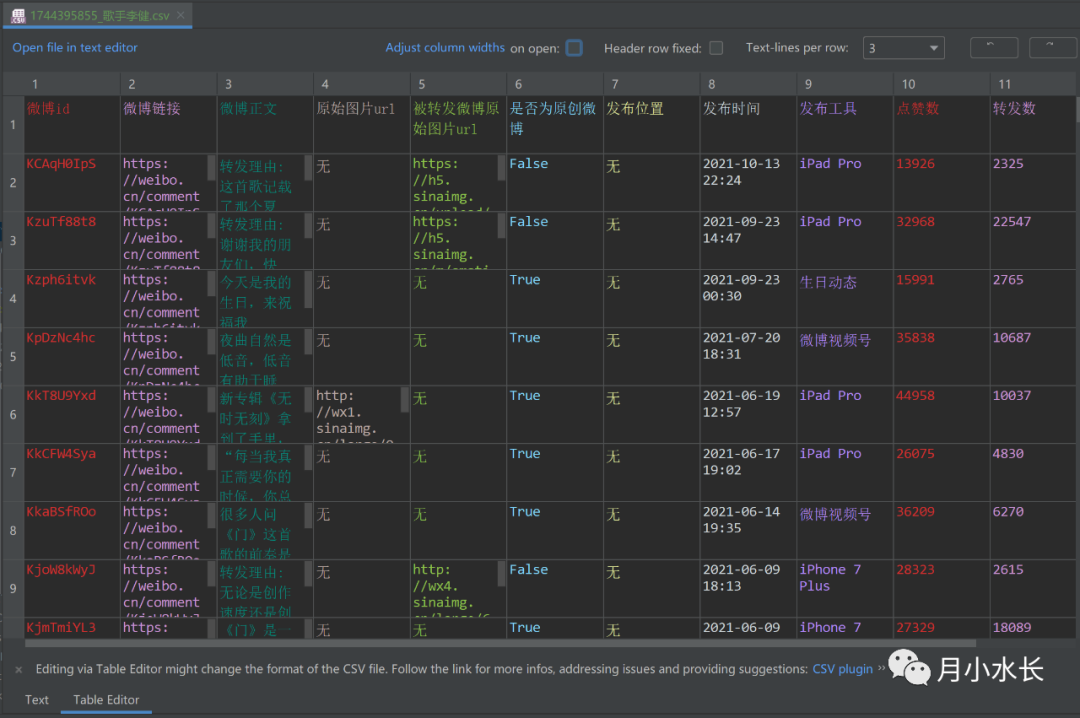
假如我们上一步抓取的是歌手李健的微博,其保存的 csv 内容如下:
在发布微博评论爬虫一文 2021 新版微博评论及其子评论爬虫发布 我们可以知道,它需要一个类似下面的配置文件。
{"cookie": "更换成你的 cookie","comments": [{"mid": "KCAqH0IpS","uid": "1744395855","limit": 10000,"desc": "转发理由:这首歌记载了那个夏天,也将开始记载你今后的日子,祝愿你永远拥有那股与生俱来的内在力量"}]}
uid 是指李健的用户 id,mid 是李健发的某一条微博的 id,limit 指的是这条微博最多要爬多少条评论,默认 1w,desc 是描述这条微博的信息,这里默认是微博正文了,主要是 mid, uid 重要。
上面这个配置文件描述了只抓取 mid=KCAqH0IpS 这 1 条微博的评论,如果要批量抓取,则需要给 comments 列表 append 包含 mid、uid、limit、desc 这四个字段的字典,之前的话题爬虫批量评论抓取配置文件有自动生成的脚本,这次批量抓取用户微博的评论,同样有。
# -*- coding: utf-8 -*-# author: inspurer(月小水长)# create_time: 2021/10/17 10:31# 运行环境 Python3.6+# github https://github.com/inspurer# 微信公众号 月小水长import jsonimport pandas as pdlimit = 10000config_path = 'mac_comment_config.json'input_file = './1744395855_歌手李健.csv'if '/' in input_file:user_id = input_file[input_file.rindex('/')+1:input_file.rindex('_')]else:user_id = input_file[:input_file.rindex('_')]user_name = input_file[input_file.rindex('_')+1:input_file.rindex('.')]def drop_duplicate(path, col_index=0):df = pd.read_csv(path)first_column = df.columns.tolist()[col_index]# 去除重复行数据df.drop_duplicates(keep='first', inplace=True, subset=[first_column])# 可能还剩下重复 headerdf = df[-df[first_column].isin([first_column])]df.to_csv(path, encoding='utf-8-sig', index=False)drop_duplicate(input_file)with open(config_path, 'r', encoding='utf-8-sig') as f:config_json = json.loads(f.read())df = pd.read_csv(input_file)# 清除原有的 comments 配置,如不需要可注释config_json['comments'].clear()for index, row in df.iterrows():print(f'{index + 1}/{df.shape[0]}')mid = row['微博id']config_json['comments'].append({'mid': mid,'uid': user_id,'limit': limit,'desc': row['微博正文']})with open(config_path, 'w', encoding='utf-8-sig') as f:f.write(json.dumps(config_json, indent=2, ensure_ascii=False))
然后运行评论爬虫就行,上述具体操作流程可以参考 B 站下面这个视频。
评论