
PyTorch数据导入机制与标准化代码模板
PyTorch
Author:louwill
Editor:louwill
PyTorch作为一款流行深度学习框架其热度大有超越TensorFlow的感觉。根据此前的统计,目前TensorFlow虽然仍然占据着工业界,但PyTorch在视觉和NLP领域的顶级会议上已呈一统之势。
这篇文章笔者将和大家聚焦于PyTorch的自定义数据读取pipeline模板和相关trciks以及如何优化数据读取的pipeline等。我们从PyTorch的数据对象类Dataset开始。Dataset在PyTorch中的模块位于utils.data下。
from torch.utils.data import Dataset本文将围绕Dataset对象分别从原始模板、torchvision的transforms模块、使用pandas来辅助读取、torch内置数据划分功能和DataLoader来展开阐述。
Dataset原始模板
PyTorch官方为我们提供了自定义数据读取的标准化代码代码模块,作为一个读取框架,我们这里称之为原始模板。其代码结构如下:
from torch.utils.data import Datasetclass CustomDataset(Dataset):def __init__(self, ...):# stuffdef __getitem__(self, index):# stuffreturn (img, label)def __len__(self):# return examples sizereturn count
根据这个标准化的代码模板,我们只需要根据自己的数据读取任务,分别往__init__()、__getitem__()和__len__()三个方法里添加读取逻辑即可。作为PyTorch范式下的数据读取以及为了后续的data loader,三个方法缺一不可。其中:
__init__()函数用于初始化数据读取逻辑,比如读取包含标签和图片地址的csv文件、定义transform组合等。
__getitem__()函数用来返回数据和标签。目的上是为了能够被后续的dataloader所调用。
__len__()函数则用于返回样本数量。
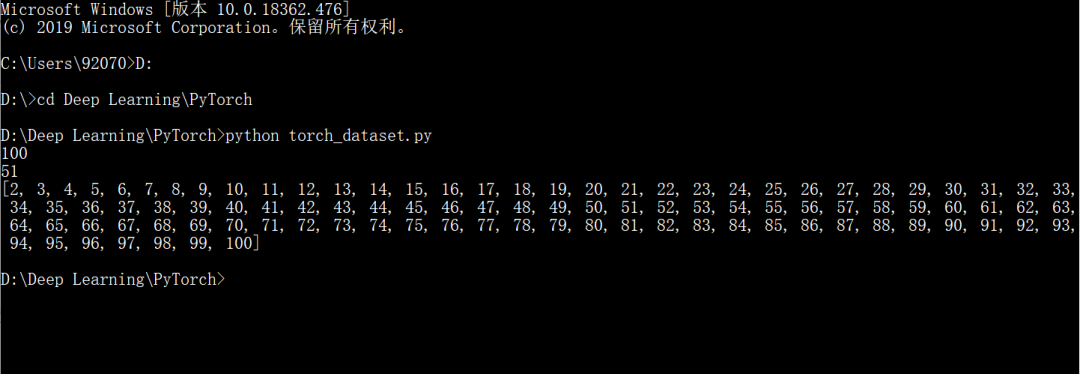
现在我们往这个框架里填几行代码来形成一个简单的数字案例。创建一个从1到100的数字例子:
from torch.utils.data import Datasetclass CustomDataset(Dataset):def __init__(self):self.samples = list(range(1, 101))def __len__(self):return len(self.samples)def __getitem__(self, idx):return self.samples[idx]if __name__ == '__main__':dataset = CustomDataset()print(len(dataset))print(dataset[50])print(dataset[1:100])
添加torchvision.transforms
然后我们来看如何从内存中读取数据以及如何在读取过程中嵌入torchvision中的transforms功能。torchvision是一个独立于torch的关于数据、模型和一些图像增强操作的辅助库。主要包括datasets默认数据集模块、models经典模型模块、transforms图像增强模块以及utils模块等。在使用torch读取数据的时候,一般会搭配上transforms模块对数据进行一些处理和增强工作。
添加了tranforms之后的读取模块可以改写为:
from torch.utils.data import Datasetfrom torchvision import transforms as Tclass CustomDataset(Dataset):def __init__(self, ...):# stuff...# compose the transforms methodsself.transform = T.Compose([T.CenterCrop(100),T.ToTensor()])def __getitem__(self, index):# stuff...data = # Some data read from a file or image# execute the transformdata = self.transform(data)return (img, label)def __len__(self):# return examples sizereturn countif __name__ == '__main__':# Call the datasetcustom_dataset = CustomDataset(...)
可以看到,我们使用了Compose方法来把各种数据处理方法聚合到一起进行定义数据转换方法。通常作为初始化方法放在__init__()函数下。我们以猫狗图像数据为例进行说明。

定义数据读取方法如下:
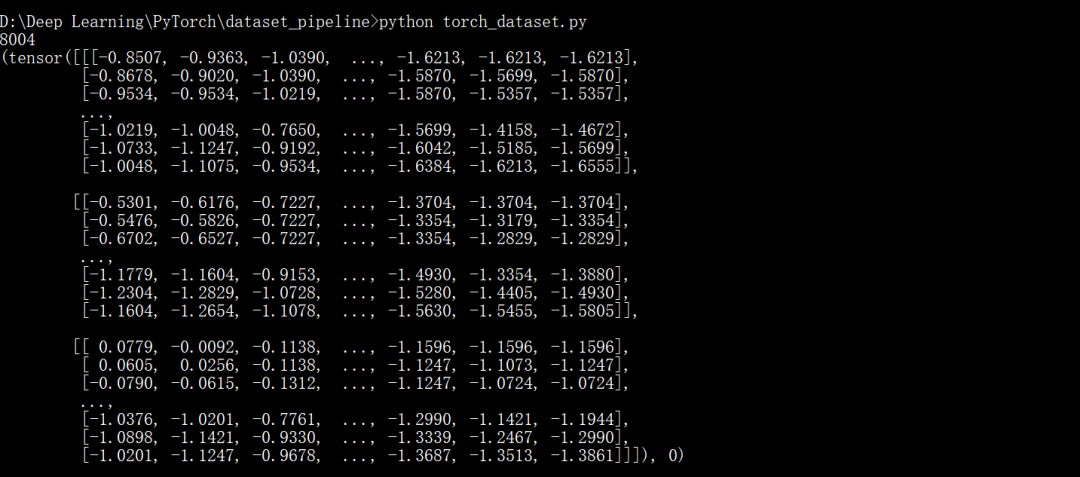
class DogCat(Dataset):def __init__(self, root, transforms=None, train=True, val=False):"""get images and execute transforms."""self.val = valimgs = [os.path.join(root, img) for img in os.listdir(root)]# train: Cats_Dogs/trainset/cat.1.jpg# val: Cats_Dogs/valset/cat.10004.jpgimgs = sorted(imgs, key=lambda x: x.split('.')[-2])self.imgs = imgsif transforms is None:# normalizenormalize = T.Normalize(mean = [0.485, 0.456, 0.406],std = [0.229, 0.224, 0.225])# trainset and valset have different data transform# trainset need data augmentation but valset don't.# valsetif self.val:self.transforms = T.Compose([T.Resize(224),T.CenterCrop(224),T.ToTensor(),normalize])# trainsetelse:self.transforms = T.Compose([T.Resize(256),T.RandomResizedCrop(224),T.RandomHorizontalFlip(),T.ToTensor(),normalize])def __getitem__(self, index):"""return data and label"""img_path = self.imgs[index]label = 1 if 'dog' in img_path.split('/')[-1] else 0data = Image.open(img_path)data = self.transforms(data)return data, labeldef __len__(self):"""return images size."""return len(self.imgs)if __name__ == "__main__":train_dataset = DogCat('./Cats_Dogs/trainset/', train=True)print(len(train_dataset))print(train_dataset[0])
因为这个数据集已经分好了训练集和验证集,所以在读取和transforms的时候需要进行区分。运行示例如下:
与pandas一起使用
很多时候数据的目录地址和标签都是通过csv文件给出的。如下所示:
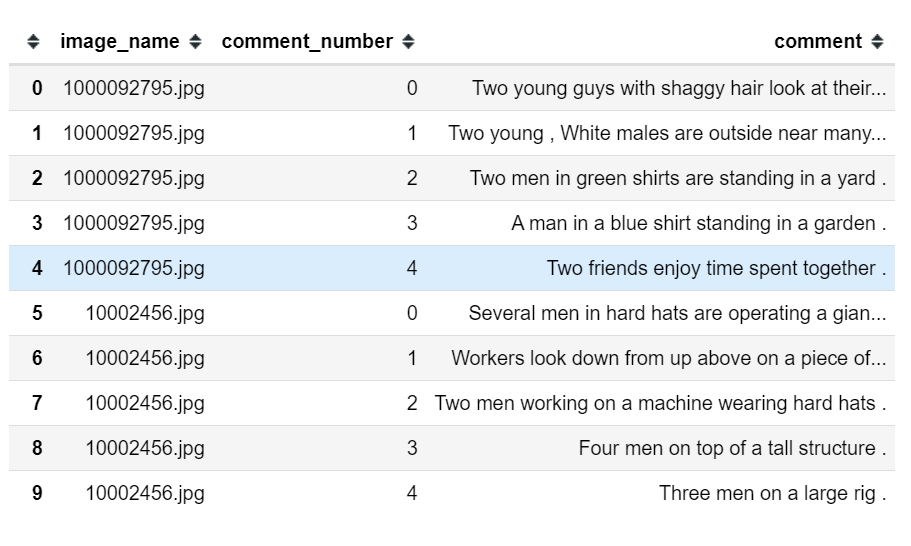
此时在数据读取的pipeline中我们需要在__init__()方法中利用pandas把csv文件中包含的图片地址和标签融合进去。相应的数据读取pipeline模板可以改写为:
class CustomDatasetFromCSV(Dataset):def __init__(self, csv_path):"""Args:csv_path (string): path to csv filetransform: pytorch transforms for transforms and tensor conversion"""# Transformsself.to_tensor = transforms.ToTensor()# Read the csv fileself.data_info = pd.read_csv(csv_path, header=None)# First column contains the image pathsself.image_arr = np.asarray(self.data_info.iloc[:, 0])# Second column is the labelsself.label_arr = np.asarray(self.data_info.iloc[:, 1])# Calculate lenself.data_len = len(self.data_info.index)def __getitem__(self, index):# Get image name from the pandas dfsingle_image_name = self.image_arr[index]# Open imageimg_as_img = Image.open(single_image_name)# Transform image to tensorimg_as_tensor = self.to_tensor(img_as_img)# Get label of the image based on the cropped pandas columnsingle_image_label = self.label_arr[index]return (img_as_tensor, single_image_label)def __len__(self):return self.data_lenif __name__ == "__main__":# Call datasetdataset = CustomDatasetFromCSV('./labels.csv')
以mnist_label.csv文件为示例:
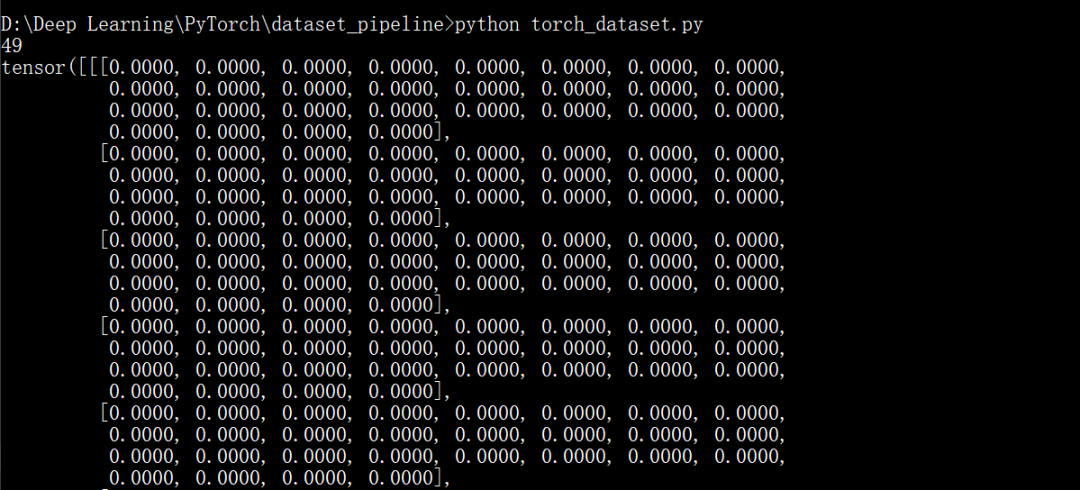
from torch.utils.data import Datasetfrom torch.utils.data import DataLoaderfrom torchvision import transforms as Tfrom PIL import Imageimport osimport numpy as npimport pandas as pdclass CustomDatasetFromCSV(Dataset):def __init__(self, csv_path):"""Args:csv_path (string): path to csv filetransform: pytorch transforms for transforms and tensor conversion"""# Transformsself.to_tensor = T.ToTensor()# Read the csv fileself.data_info = pd.read_csv(csv_path, header=None)# First column contains the image pathsself.image_arr = np.asarray(self.data_info.iloc[:, 0])# Second column is the labelsself.label_arr = np.asarray(self.data_info.iloc[:, 1])# Third column is for an operation indicatorself.operation_arr = np.asarray(self.data_info.iloc[:, 2])# Calculate lenself.data_len = len(self.data_info.index)def __getitem__(self, index):# Get image name from the pandas dfsingle_image_name = self.image_arr[index]# Open imageimg_as_img = Image.open(single_image_name)# Check if there is an operationsome_operation = self.operation_arr[index]# If there is an operationif some_operation:# Do some operation on image# ...# ...pass# Transform image to tensorimg_as_tensor = self.to_tensor(img_as_img)# Get label of the image based on the cropped pandas columnsingle_image_label = self.label_arr[index]return (img_as_tensor, single_image_label)def __len__(self):return self.data_lenif __name__ == "__main__":transform = T.Compose([T.ToTensor()])dataset = CustomDatasetFromCSV('./mnist_labels.csv')print(len(dataset))print(dataset[5])
运行示例如下:
训练集验证集划分
一般来说,为了模型训练的稳定,我们需要对数据划分训练集和验证集。torch的Dataset对象也提供了random_split函数作为数据划分工具,且划分结果可直接供后续的DataLoader使用。
以kaggle的花朵数据为例:
from torch.utils.data import DataLoaderfrom torchvision.datasets import ImageFolderfrom torchvision import transforms as Tfrom torch.utils.data import random_splittransform = T.Compose([T.Resize((224, 224)),T.RandomHorizontalFlip(),T.ToTensor()])dataset = ImageFolder('./flowers_photos', transform=transform)print(dataset.class_to_idx)trainset, valset = random_split(dataset,[int(len(dataset)*0.7), len(dataset)-int(len(dataset)*0.7)])trainloader = DataLoader(dataset=trainset, batch_size=32, shuffle=True, num_workers=1)for i, (img, label) in enumerate(trainloader):img, label = img.numpy(), label.numpy()print(img, label)valloader = DataLoader(dataset=valset, batch_size=32, shuffle=True, num_workers=1)for i, (img, label) in enumerate(trainloader):img, label = img.numpy(), label.numpy()print(img.shape, label)
这里使用了ImageFolder模块,可以直接读取各标签对应的文件夹,部分运行示例如下:
使用DataLoader
dataset方法写好之后,我们还需要使用DataLoader将其逐个喂给模型。上一节的数据划分我们已经用到了DataLoader函数。从本质上来讲,DataLoader只是调用了__getitem__()方法并按批次返回数据和标签。使用方法如下:
from torch.utils.data import DataLoaderfrom torchvision import transforms as Tif __name__ == "__main__":# Define transformstransformations = T.Compose([T.ToTensor()])# Define custom datasetdataset = CustomDatasetFromCSV('./labels.csv')# Define data loaderdata_loader = DataLoader(dataset=dataset, batch_size=10, shuffle=True)for images, labels in data_loader:# Feed the data to the model
以上就是PyTorch读取数据的Pipeline主要方法和流程。基于Dataset对象的基本框架不变,具体细节可自定义化调整。
参考资料:
https://pytorch.org/docs/stable/data.html
https://towardsdatascience.com/building-efficient-custom-datasets-in-pytorch-2563b946fd9f
https://github.com/utkuozbulak/pytorch-custom-dataset-examples
往期精彩: