
特征锦囊:数据归一化Normalization与标准化Standardization
特征锦囊:数据归一化Normalization与标准化Standardization
🚅 Index
理论 代码实现
🎯 理论知识
数据归一化与标准化是预处理阶段的关键步骤,但常常被遗忘。虽然存在决策树和随机森林这种是少数不需要特征缩放的机器学习算法,但对于大部分机器学习算法和优化算法来说,如果特征都在同一范围内,会获得更好的结果。你想象一下有两个特征,一个特征的取值范围是[1,10],另一个特征的取值范围是[1,100000]。很明显,如果使用kNN算法,它是用欧氏距离作为距离度量,第二维度特征也就占据了主要的话语权。
其中,数据归一化我们常用的是Min-Max方法,也就是根据数据记录中的最大和最小值进行数据的缩放,使其收缩到0-1之间,具体公式如下:
而数据标准化,更多指的是Z-Score标准化,也就是将赋予原始数据的均值(mean)和标准差(standard deviation)从而实现数据的标准化,具体就是按均值 μ = 0 ,标准差σ = 1 将数据按比例缩放,使之落入一个特定区间,具体公式如下:
下面进行了小结: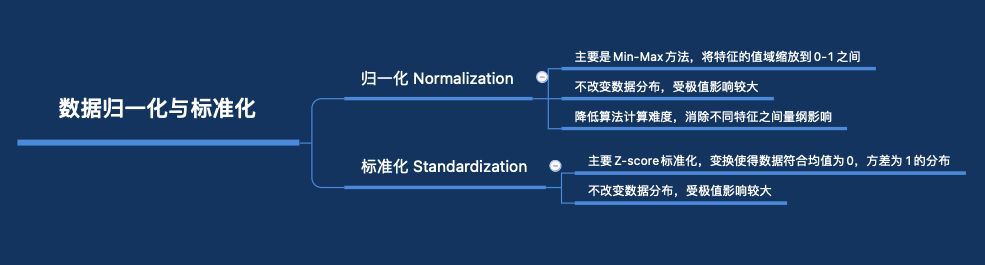
🎯 代码实现
from sklearn.datasets import load_iris
#导入IRIS数据集
iris = load_iris()
#标准化,返回值为标准化后的数据
from sklearn.preprocessing import StandardScaler
StandardScaler().fit_transform(iris.data)
#归一化,返回值为缩放到[0, 1]区间的数据
from sklearn.preprocessing import MinMaxScaler
MinMaxScaler().fit_transform(iris.data)
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑
机器学习交流qq群955171419,加入微信群请扫码
评论