
几十行代码爬取猫眼电影Top100榜单
基本信息
今天,手把手教你入门 Python 爬虫,爬取猫眼电影 TOP100 榜信息。
猫眼电影的网址为:http://maoyan.com/,但这不是我们此次想爬取的站点,我们爬取的站点是这个:http://maoyan.com/board/4(TOP100榜单)
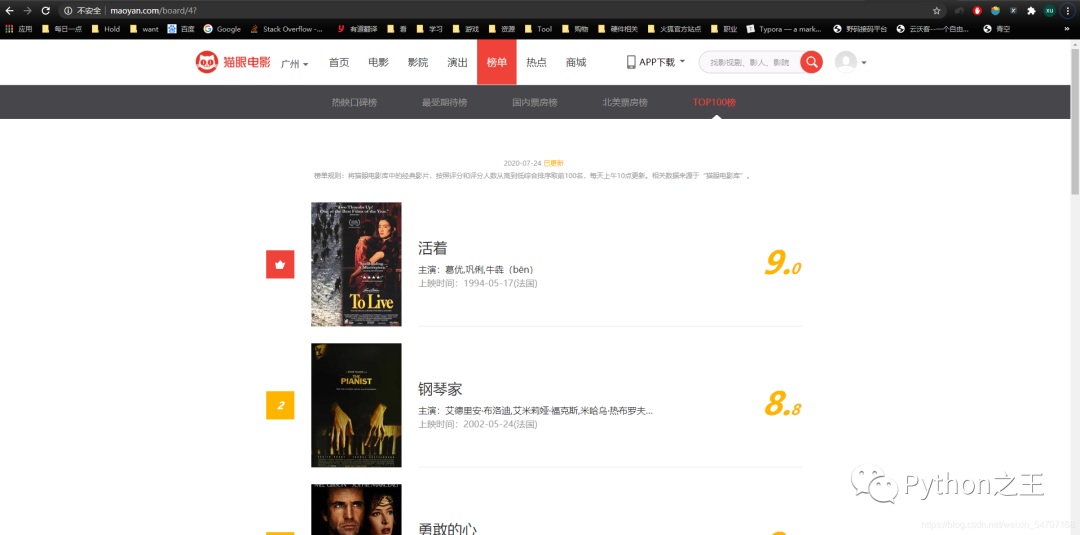
前100的电影的信息爬下来,保存起来。
下面是爬取结果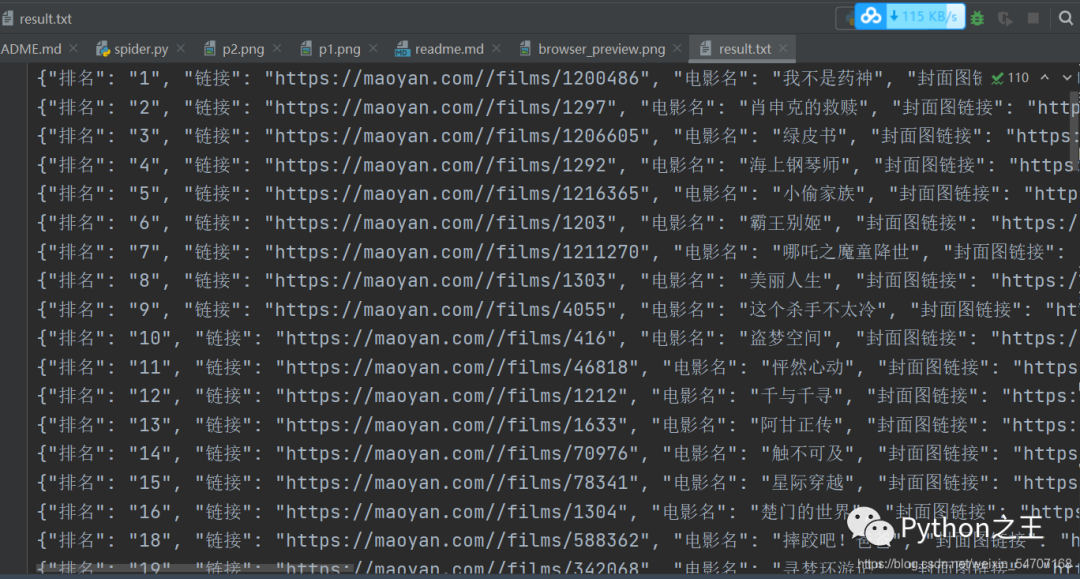
描述
静态网页,非常简单 。通过观察我们需要爬取的内容有:片名,图片,排名,主演,上映时间和评分这6部分。

使用的包/工具/技术
| 步骤 | 包/工具/技术 |
|---|---|
| 网页分析 | Chrome |
| 爬取网页 | requests |
| 解析网页 | re |
问题与对应处理
IP访问频率
懒得弄代理,选择每次爬取后等待一段时间
User-Agent限制
请求头对应项填写一下即可
分析
翻页参数


翻页的参数每一次加10而不是1
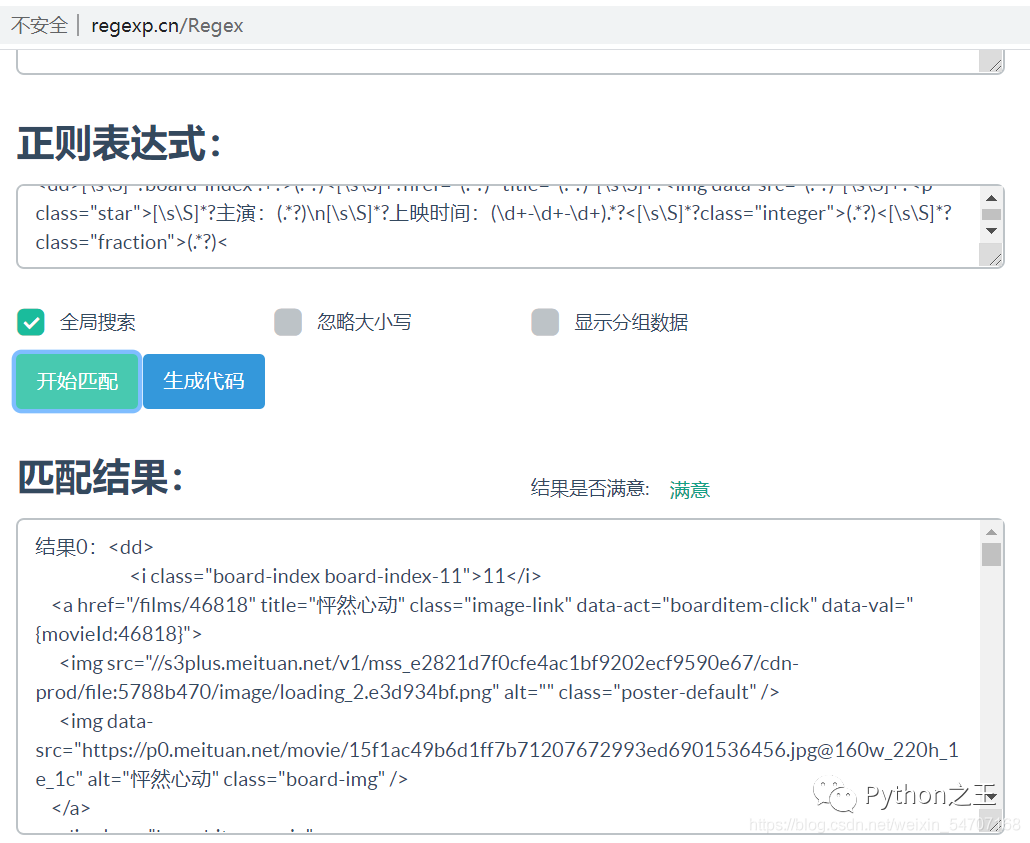
如何通过Re解析
我们先将源代码:view-source:https://maoyan.com/board/4?offset=10。
复制到:http://www.regexp.cn/Regex
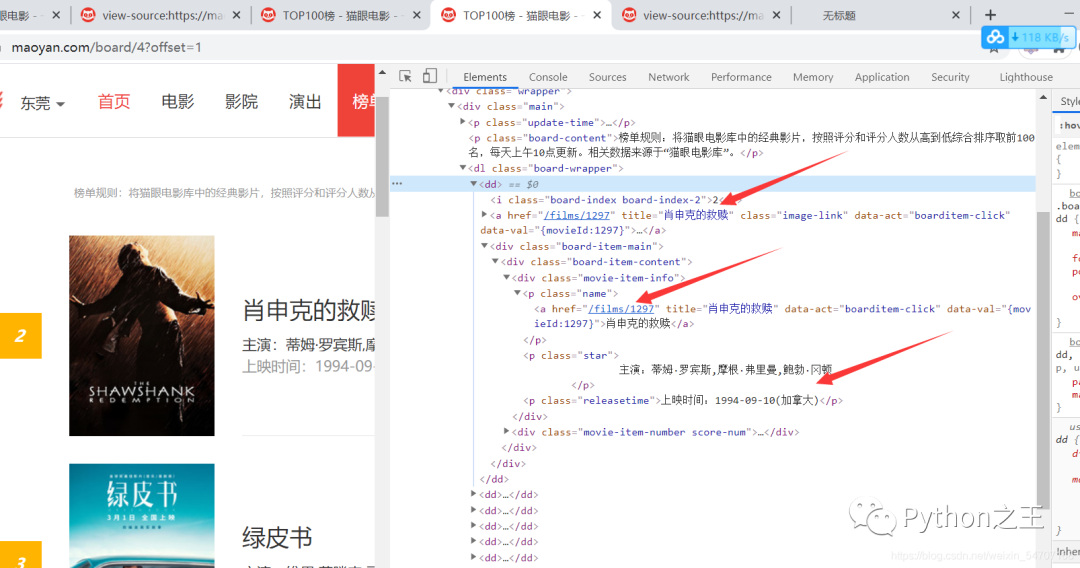
最终我们的正则表达式是这样的:
[\s\S]*?board-index-.+?>(.*?)<[\s\S]+?href="(.*?)" title="(.*?)"[\s\S]+?[\s\S]*?主演:(.*?)\n[\s\S]*?上映时间:(\d+-\d+-\d+).*?<[\s\S]*?class="integer">(.*?)<[\s\S]*?class="fraction">(.*?)<
下面就是正则解析的代码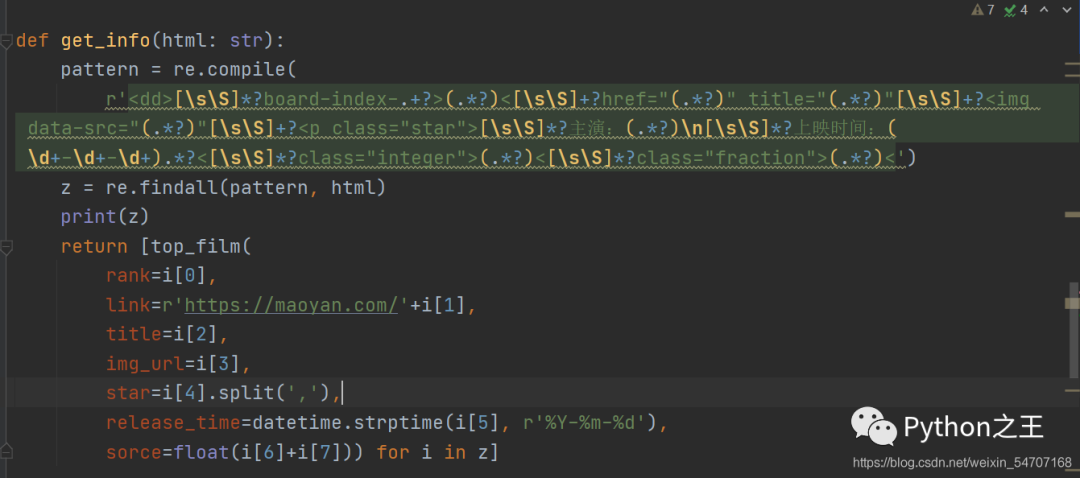

最后就是封装代码,实现整套爬虫的代码
import requests
from requests.exceptions import RequestException
import re
from datetime import datetime
import json
import time
class top_film(object):
def __init__(self, rank: int, link: str, title: str, img_url: str, star: list, release_time: datetime, sorce: float):
self.rank = rank
self.link = link
self.title = title
self.img_url = img_url
self.star = star
self.release_time = release_time
self.sorce = sorce
def to_dict(self):
return {
'排名': self.rank,
'链接': self.link,
'电影名': self.title,
'封面图链接': self.img_url,
'主演:': str(self.star),
'上映时间': self.release_time.strftime(r'%Y-%m-%d'),
'猫眼评分': str(self.sorce)
}
def get_a_page(page_num):
url = 'https://maoyan.com/board/4?offset=' + str(page_num*10)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
}
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
except RequestException as e:
time.sleep(3)
print(e)
return None
def get_info(html: str):
pattern = re.compile(
r'[\s\S]*?board-index-.+?>(.*?)<[\s\S]+?href="(.*?)" title="(.*?)"[\s\S]+?[\s\S]*?主演:(.*?)\n[\s\S]*?上映时间:(\d+-\d+-\d+).*?<[\s\S]*?class="integer">(.*?)<[\s\S]*?class="fraction">(.*?)<' )
z = re.findall(pattern, html)
print(z)
return [top_film(
rank=i[0],
link=r'https://maoyan.com/'+i[1],
title=i[2],
img_url=i[3],
star=i[4].split(','),
release_time=datetime.strptime(i[5], r'%Y-%m-%d'),
sorce=float(i[6]+i[7])) for i in z]
def crawl_maoyan_top_100():
result = []
for page_num in range(0, 10):
html = get_a_page(page_num)
print(get_info(html))
result.extend(get_info(html))
print(page_num)
return result
if __name__ == "__main__":
result = crawl_maoyan_top_100()
print(result)
with open('result.txt', 'w', encoding='utf-8')as f:
for film in result:
f.write(json.dumps(film.to_dict(), ensure_ascii=False) + '\n')
评论