
电影荒吗?教你爬取豆瓣电影top250
点击上方蓝字关注我们

点击上方“印象python”,选择“星标”公众号
重磅干货,第一时间送达!
爬虫目标
爬取豆瓣电影top250,获取的信息有电影名称、简介、导演、评分、观看人数和电影语录等信息。
项目准备
软件:Pycharm
第三方库:requests,parsel,pandas,lxml,os
网站地址:https://movie.douban.com/top250?start=
网站分析
网站首页如下:
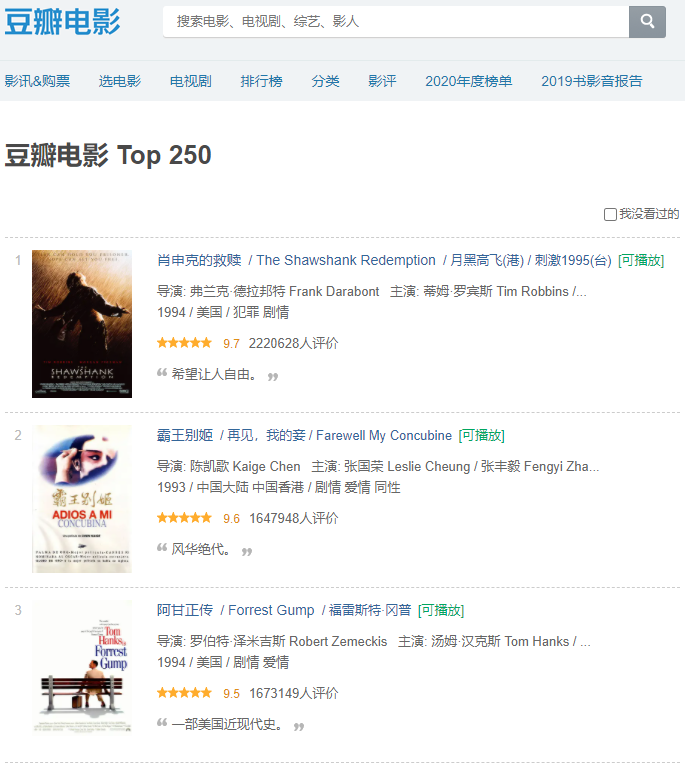
1.首先判断其是动态加载还是静态加载。
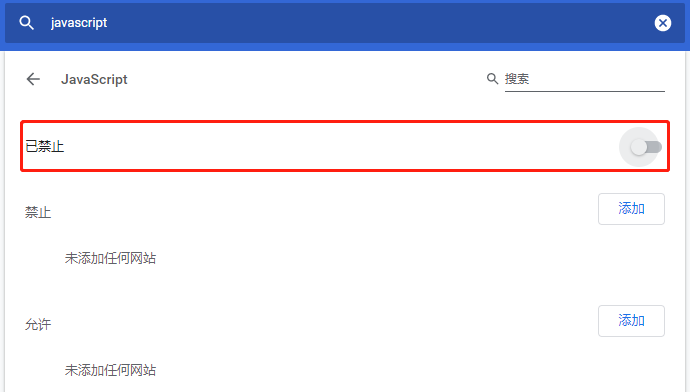
打开浏览器设置,关闭javascript。刷新页面没有任何影响即可理解为静态加载
2.F12打开浏览器开发者模式,找到电影信息源码所在位置。
如图一部电影的完整信息都存在于一个li标签之内。所以我们想要获取电影详情首先就要获取到li标签。可以发现该页面25部电影信息所在的li标签都在一个class='grid_view'的ol标签之内。所以我们可以通过此属性获取到25部电影所在的li。

反爬分析
为了防止在爬虫过程中反爬而抓取不到数据,我们一般只需加上user-agent和refer即可
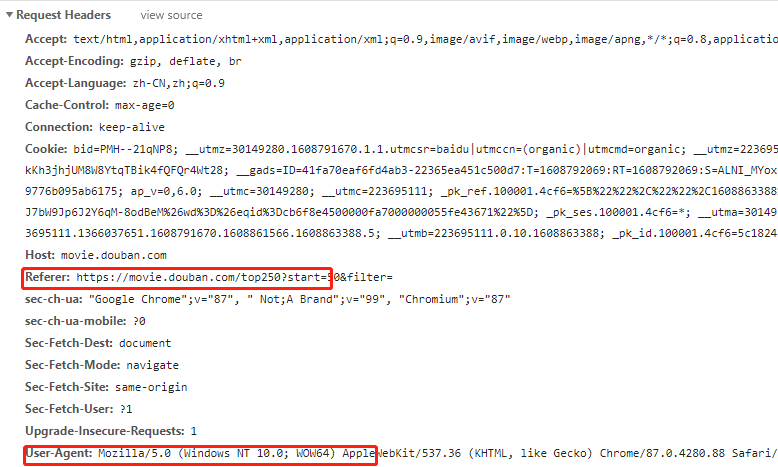
链接分析
第一页:https://movie.douban.com/top250?start=第二页:https://movie.douban.com/top250?start=25&filter=第三页:https://movie.douban.com/top250?start=50&filter=
可以发现,每页的电影信息会随着网站链接末尾数字变化而变化。
代码实现
1.获取网页源码信息
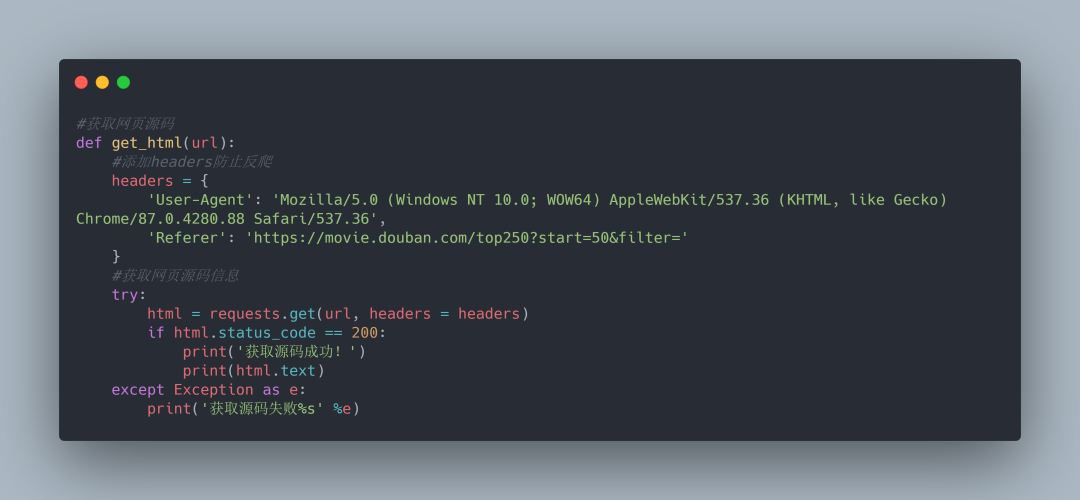
2.源码信息成功获取到之后接下来就要通过我们上面分析来定位li标签的位置
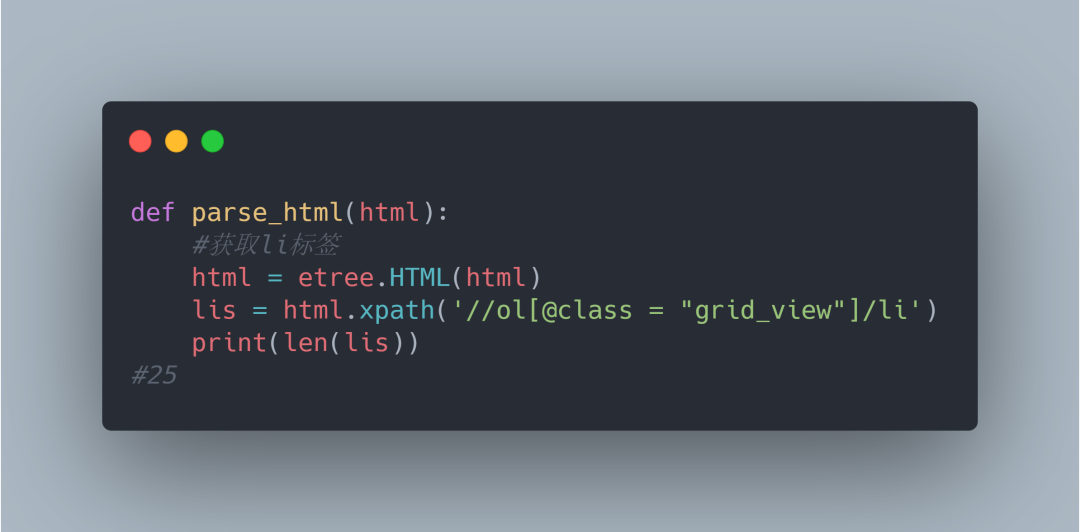
打印结果为25代表获取到了25个li标签,也就是说在当前页面有25部电影。这和页面展示的也是一模一样的
3.获取电影详情
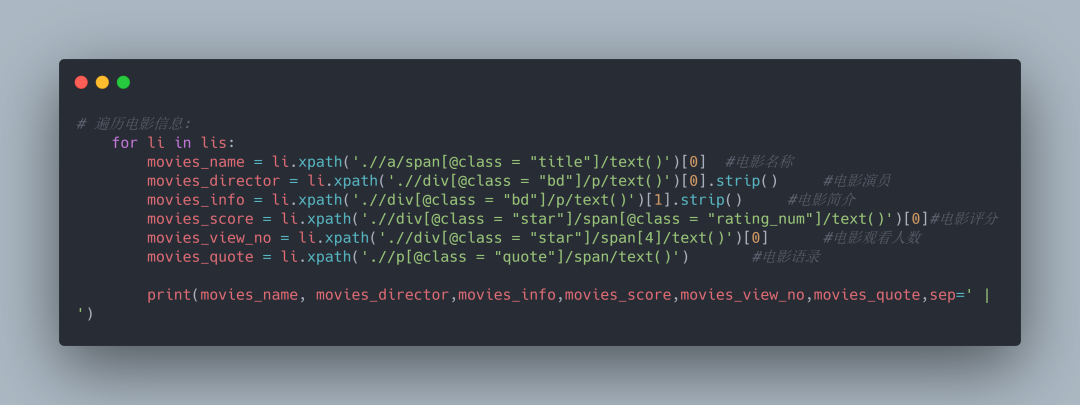
25部电影信息打印如下:

可以看到已经成功获取到我们所要信息了。
数据保存
数据保存我们需要用到pandas,首先我们导入
import pandas as pd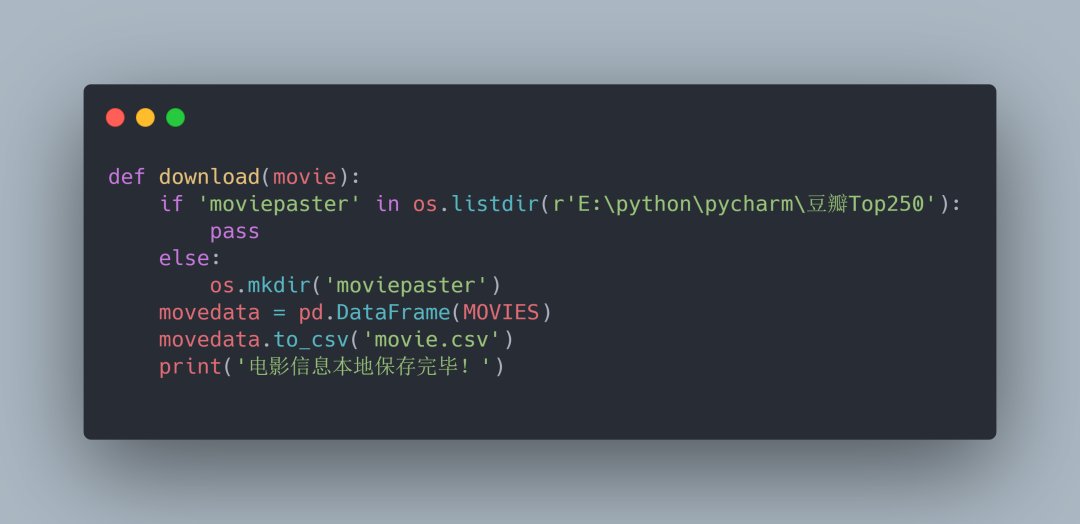
现在第一页的数据已经成功保存到本地csv文件中了,接下来就是10页的问题了,很简单。只需加上一个循环即可。在此就不多赘述了。有兴趣的小伙伴可参考源码一探究竟。
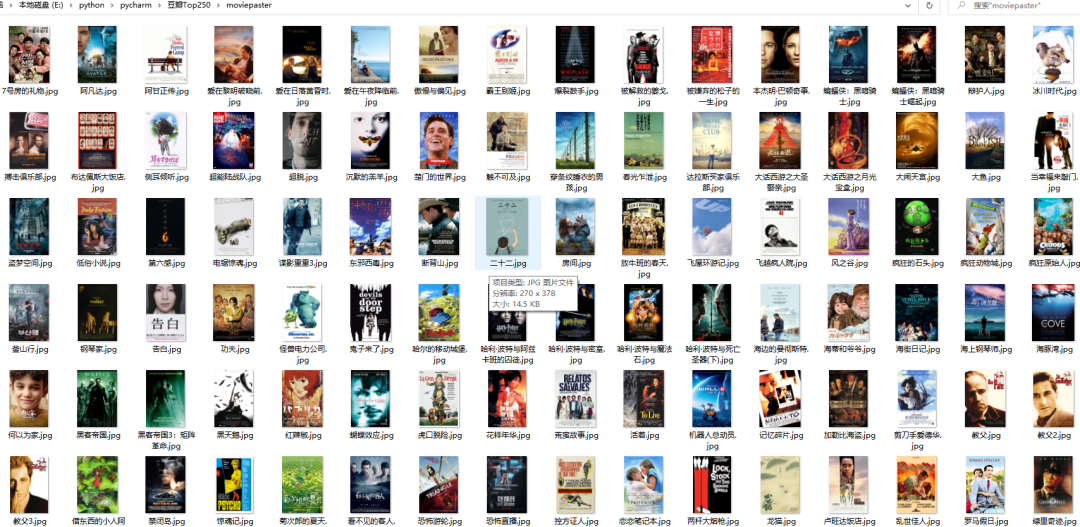
效果展示

csv文件如下:
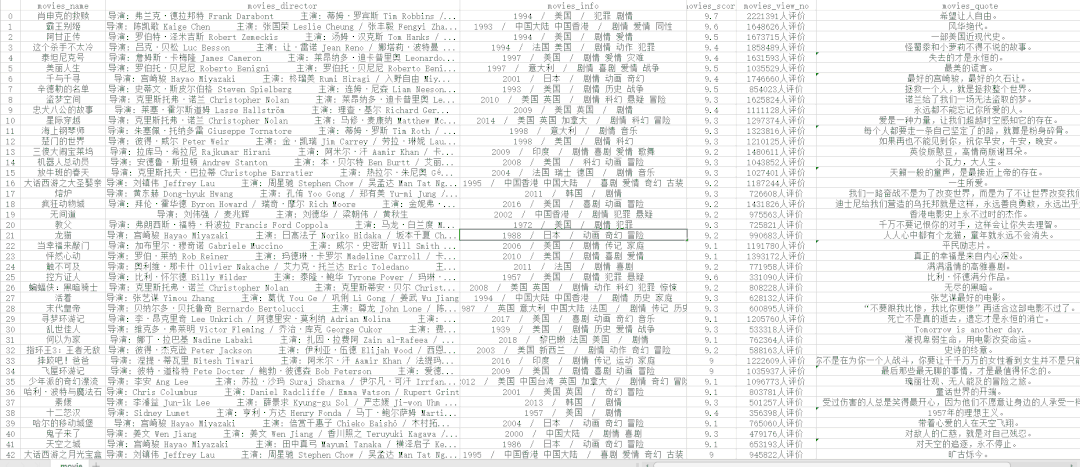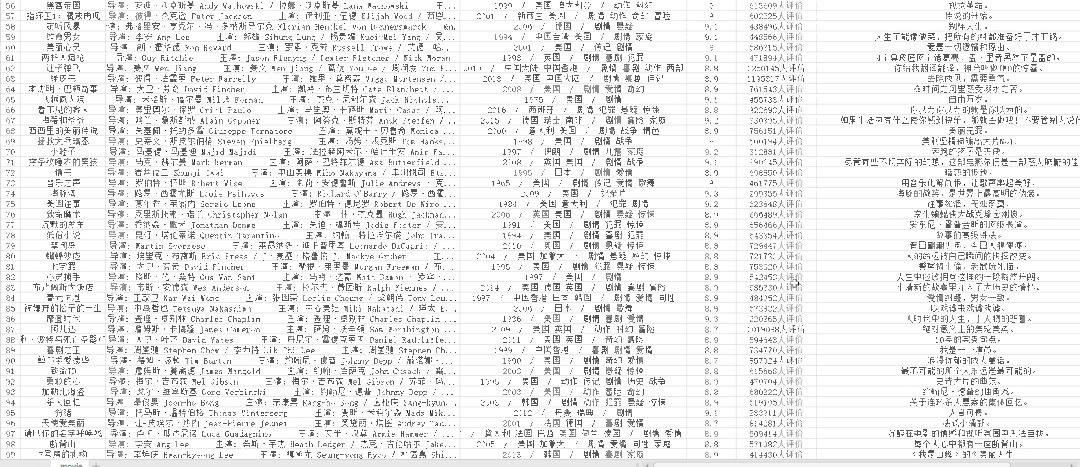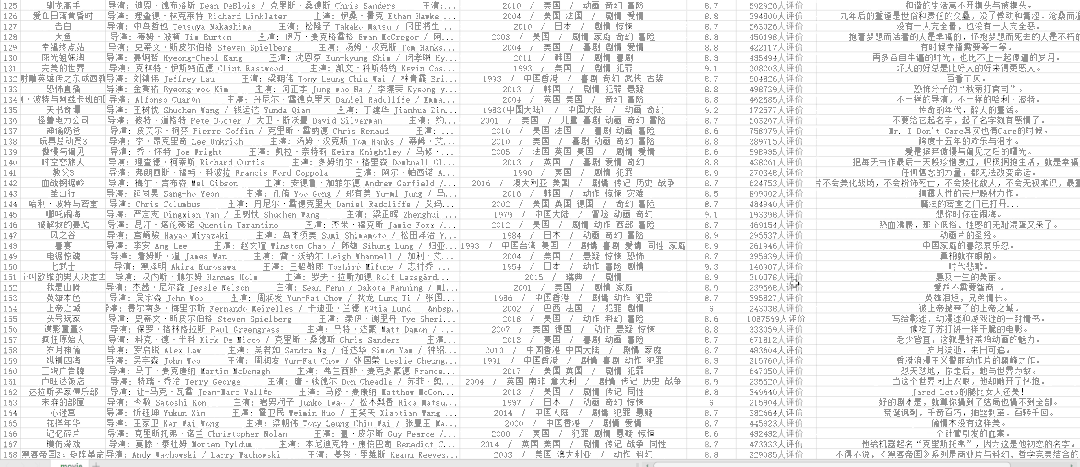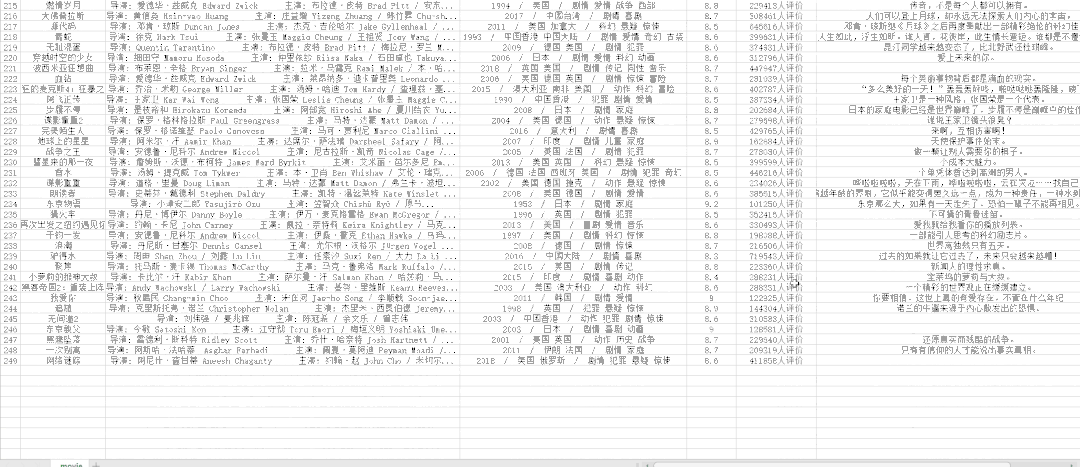
图片文件如下:
想要学习或者对源码有兴趣的小伙伴扫码回复'电影'即可
扫描二维码
获取更多精彩
python学前班
回复下方 「关键词」,获取优质资源
回复关键词 「linux」,即可获取 185 页 Linux 工具快速教程手册和154页的Linux笔记。
回复关键词 「Python进阶」,即可获取 106 页 Python 进阶文档 PDF
回复关键词 「Python面试题」,即可获取最新 100道 面试题 PDF
回复关键词 「python数据分析」,即可获取47页python数据分析与自然语言处理的 PDF
回复关键词 「python爬虫」,满满五份PPT爬虫教程和70多个案例
回复关键词 「Python最强基础学习文档」,即可获取 168 页 Python 最强基础学习文档 PDF,让你快速入门Python
推荐我的微信号
来围观我的朋友圈,我的经验分享,技术更新,不定期送书,坑位有限,速速扫码添加!
备注:开发方向_昵称_城市,另送你10本Python电子书。
点个在看你最好看




评论