
小伙爬取CSDN博客TOP100榜单,发现高玩博主的秘密...
周末闲来无事,爬了爬CSDN榜单数据。
一、数据获取
我们需要爬取的数据为CSDN周榜单,如下:
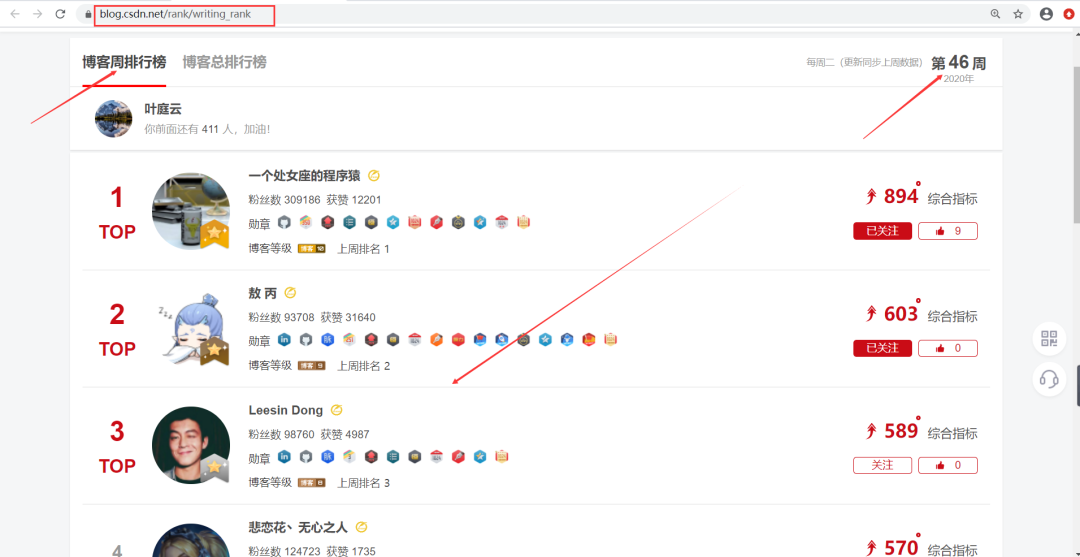
URL:https://blog.csdn.net/rank/writing_rank
检查可以发现,只需要简单的构造URL去请求,抓取json数据,再从中提取出我们想要的数据保存到Excecl。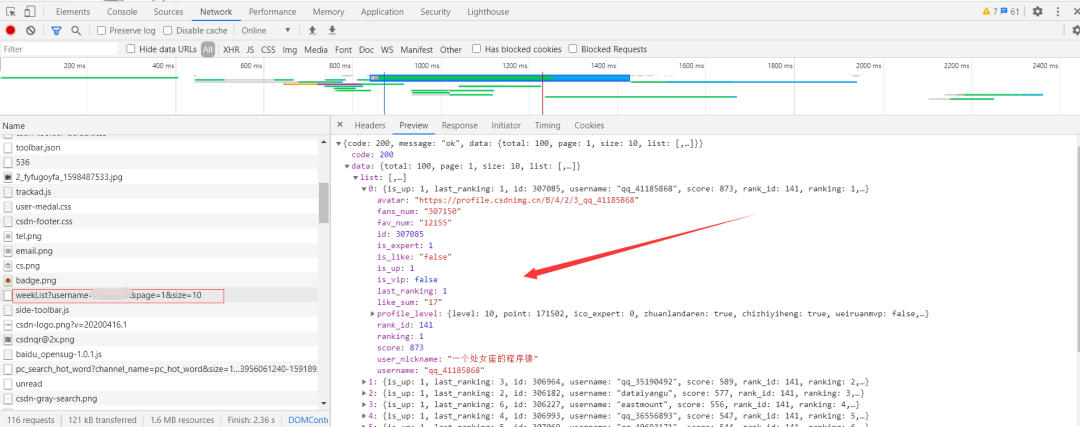
代码如下
# -*- coding: UTF-8 -*-
"""
@File :demo.py
@Author :叶庭云
@CSDN :https://yetingyun.blog.csdn.net/
"""
import requests
import json
import logging
import openpyxl
wb = openpyxl.Workbook()
sheet = wb.active
sheet.append(['博主昵称', '排名', '综合得分', '粉丝数', '获赞数', '博客等级', '是否认证为博客专家'])
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'
}
for i in range(1, 11):
# username={改成你的username}
url = f'https://blog.csdn.net/api/WritingRank/weekList?username={改成你的username}&page={i}&size=10'
rep = requests.get(url, headers=headers)
data = json.loads(rep.text)
datas = data['data']['list']
for item in datas:
score = item['score'] # 综合得分
ranking = item['ranking'] # 排名
user_nickname = item['user_nickname'] # 博主昵称
fans_num = item['fans_num'] # 粉丝数
fav_num = item['fav_num'] # 获赞数
level = item['profile_level']['level'] # 博客等级
is_expert = item['is_expert'] # 是否认证为博客专家
sheet.append([user_nickname, ranking, score, fans_num, fav_num, level, is_expert])
logging.info([user_nickname, ranking, score, fans_num, fav_num, level, is_expert])
wb.save('rank_datas.xlsx')
二、查看数据
随机抽取8行数据查看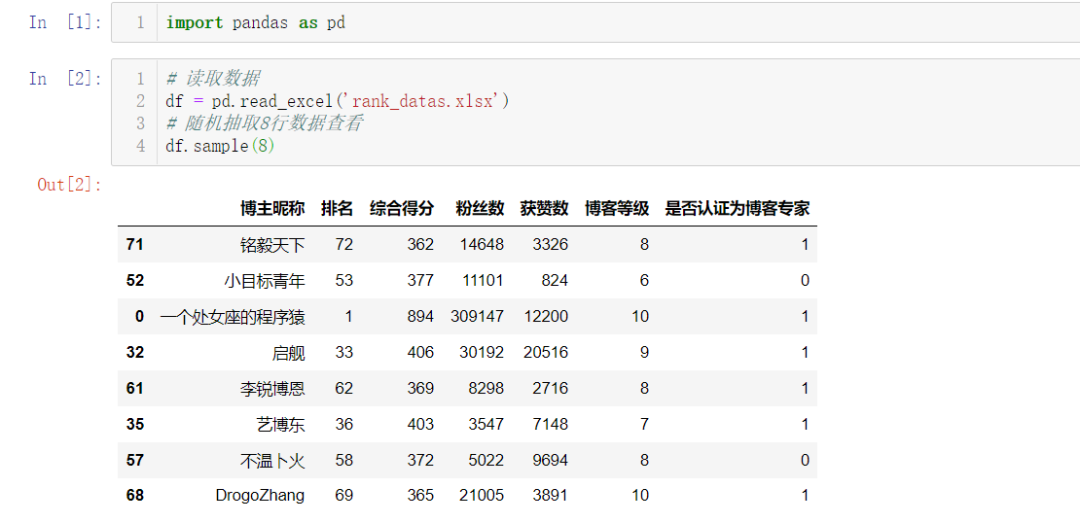
查看数据类型、内存、索引、列名信息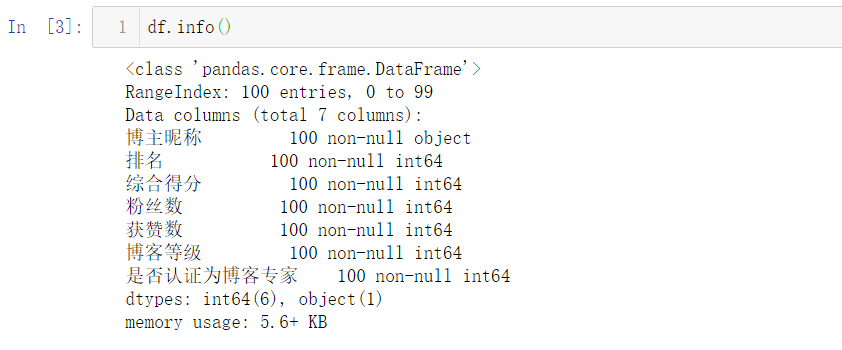
数值列的统计信息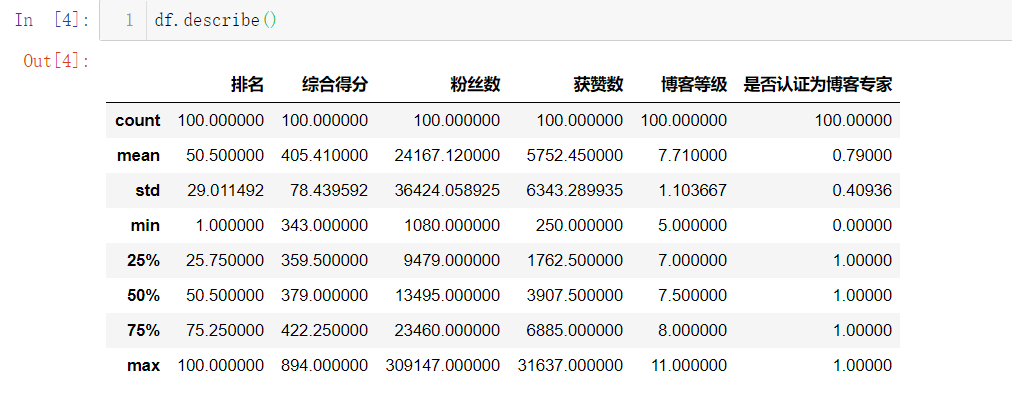
各列的相关系数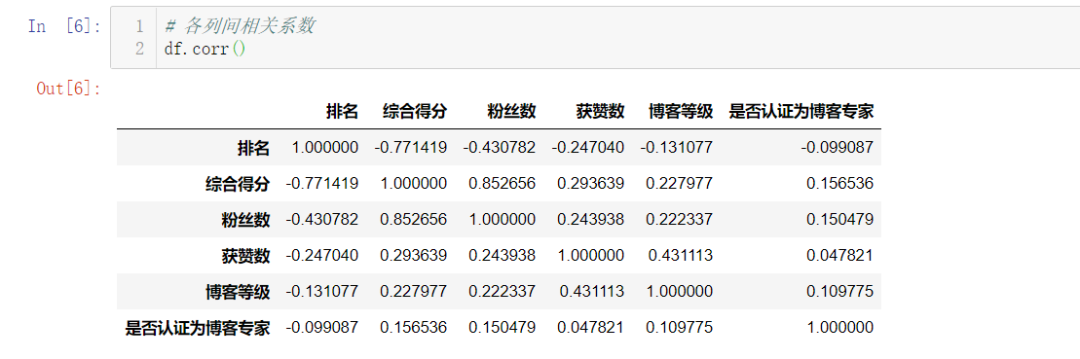
三、pyecharts数据可视化
1. pyecharts简介和安装
Echarts 是一个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可。而 Python 是一门富有表达力的语言,很适合用于数据处理。当数据分析遇上数据可视化时,pyecharts 诞生了。
简洁的 API 设计,使用如丝滑般流畅,支持链式调用 囊括了 30+ 种常见图表,应有尽有 支持主流 Notebook 环境,Jupyter Notebook 和 JupyterLab 可轻松集成至 Flask,Sanic,Django 等主流 Web 框架 高度灵活的配置项,可轻松搭配出精美的图表 详细的文档和示例,帮助开发者更快的上手项目 多达 400+ 地图文件,并且支持原生百度地图,为地理数据可视化提供强有力的支持
pyecharts版本v0.5.x 和 v1 间不兼容,v1 是一个全新的版本,语法也有很大不同。
# 安装pyecharts
pip install pyecharts -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
import pyecharts
print(pyecharts.__version__) # 查看pyecharts版本
2. 数据可视化
首先,来看一看Top10的大佬博主都是哪些人
# -*- coding: UTF-8 -*-
"""
@File :漏斗图_top10.py
@Author :叶庭云
@CSDN :https://yetingyun.blog.csdn.net/
"""
import pandas as pd
import pyecharts.options as opts
from pyecharts.charts import Funnel
from pyecharts.globals import CurrentConfig, ThemeType
# 引用本地 js 资源
CurrentConfig.ONLINE_HOST = 'D:/python/pyecharts-assets-master/assets/'
# 读取数据
df = pd.read_excel('rank_datas.xlsx')
# 取博主昵称 综合得分两列数据
df1 = df[['博主昵称', '综合得分']]
# print(df1)
# 取Top10博主数据
labels = list(df1['博主昵称'][:10])
values = list(df1['综合得分'][:10])
data = [[labels[x], int(values[x])] for x in range(len(labels))]
# 漏斗图可视化
c = (
Funnel(init_opts=opts.InitOpts(width="1200px", height="600px", theme=ThemeType.LIGHT))
.add(
series_name='', # 系列名称,用于 tooltip 的显示,legend 的图例筛选。
data_pair=data, # 系列数据项,格式为 [(key1, value1), (key2, value2)]
gap=3, # 数据图形间距
label_opts=opts.LabelOpts(is_show=True, position="inside"), # 标签配置项,参考 `series_options.LabelOpts`
)
.set_global_opts(
title_opts=opts.TitleOpts(title="CSDN周排Top10博主一览"), # 标题
legend_opts=opts.LegendOpts(type_="scroll", pos_top='50%', pos_left="80%", orient="vertical"), # 调整图例位置
)
.render('funnel_chart.html')
)
运行效果如下: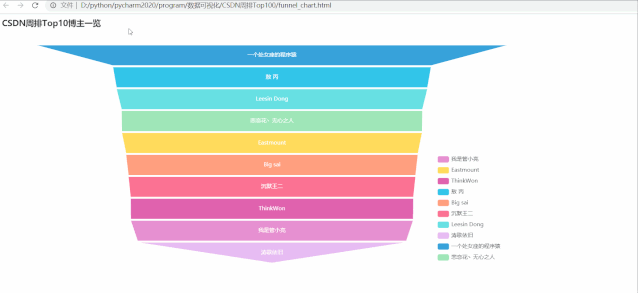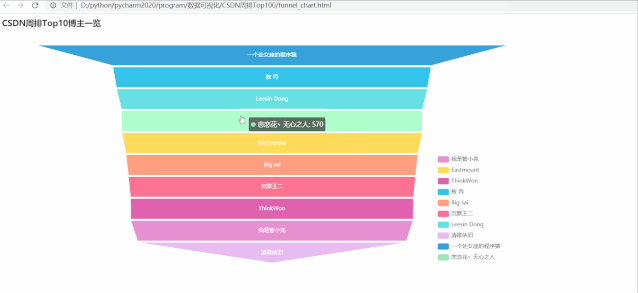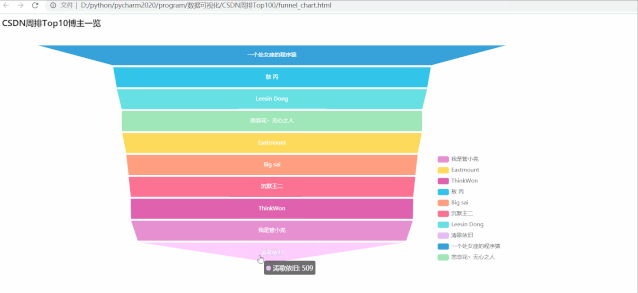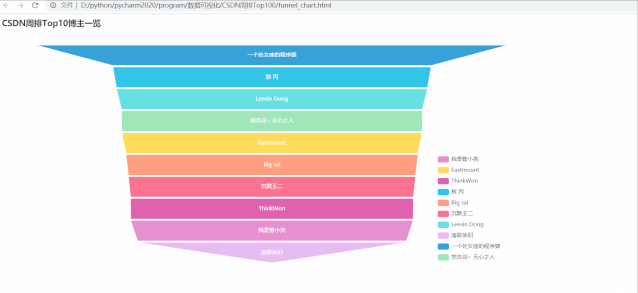
排在第一的大佬博主是:一个处女座的程序猿,综合指标:894,远高于之后的其他博主,而从漏斗图也容易看出,后面 9 位博主综合指标差距不大。
再来看看周排 Top100 博主里,已认证博客专家的比例
# -*- coding: UTF-8 -*-
"""
@File :博客专家占比.py
@Author :叶庭云
@CSDN :https://yetingyun.blog.csdn.net/
"""
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.globals import CurrentConfig
# 引用本地 js 资源
CurrentConfig.ONLINE_HOST = 'D:/python/pyecharts-assets-master/assets/'
# 读取数据 统计认证了博客专家和没有认证的数量
df = pd.read_excel('rank_datas.xlsx')
datas = df['是否认证为博客专家'].value_counts()
print(datas)
labels = ['已认证博客专家', '未认证博客专家']
value = datas.values
data = [[i, int(j)] for i, j in zip(labels, value)]
c = (
Pie()
.add(
series_name="", # 系列名称,用于 tooltip 的显示,legend 的图例筛选。
data_pair=data, # 系列数据项,格式为 [(key1, value1), (key2, value2)]
radius=["40%", "60%"], # 饼图的半径,数组的第一项是内半径,第二项是外半径
# 富文本设置
label_opts=opts.LabelOpts(
position="outside",
formatter="{a|{a}}{abg|}\n{hr|}\n {b|{b}: }{c} {per|{d}%} ",
background_color="#eee",
border_color="#aaa",
border_width=1,
border_radius=4,
rich={
"a": {"color": "#999", "lineHeight": 22, "align": "center"},
"abg": {
"backgroundColor": "#e3e3e3",
"width": "100%",
"align": "right",
"height": 22,
"borderRadius": [4, 4, 0, 0],
},
"hr": {
"borderColor": "#aaa",
"width": "100%",
"borderWidth": 0.5,
"height": 0,
},
"b": {"fontSize": 16, "lineHeight": 33},
"per": {
"color": "#eee",
"backgroundColor": "#334455",
"padding": [2, 4],
"borderRadius": 2,
},
},
),
)
.set_colors(['#FF1493', '#BA55D3'])
.set_global_opts(title_opts=opts.TitleOpts(title="周排Top100中博客专家占比"))
.render("pie_rich_label.html")
)
运行效果如下:
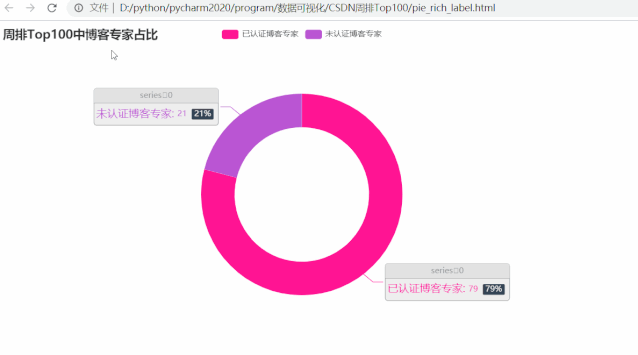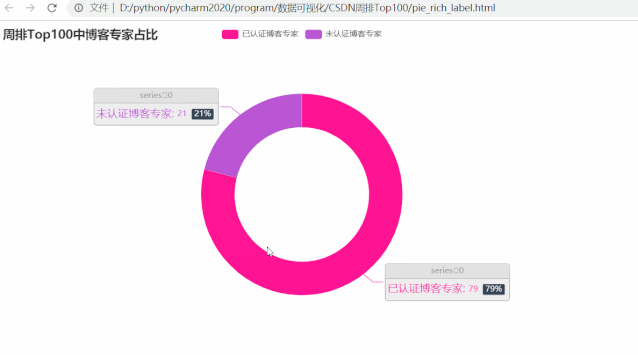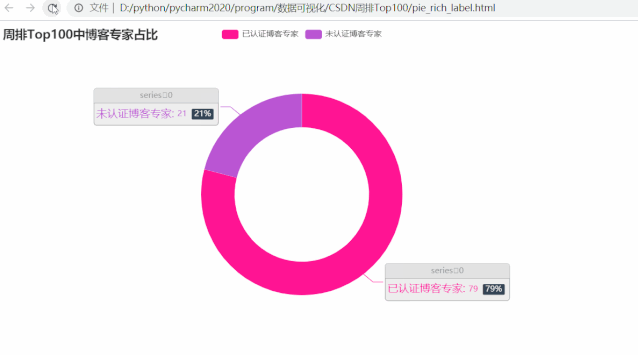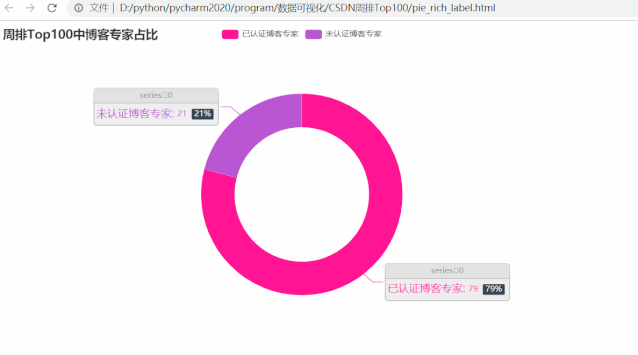
可以发现,在周排 Top100 的博主里,近 8 成都已认证博客专家,那这些 Top100 博主的等级分布呢?
# -*- coding: UTF-8 -*-
"""
@File :博客等级分布.py
@Author :叶庭云
@CSDN :https://yetingyun.blog.csdn.net/
"""
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.globals import CurrentConfig
# 引用本地 js 资源
CurrentConfig.ONLINE_HOST = 'D:/python/pyecharts-assets-master/assets/'
# 读取数据 统计各博客等级博主的数量
df = pd.read_excel('rank_datas.xlsx')
datas = df['博客等级'].value_counts()
# print(datas)
labels = [f'等级{i}' for i in datas.index]
nums = [int(j) for j in datas]
data = [[i, j] for i, j in zip(labels, nums)]
print(data)
c = (
# 宽 高 背景颜色
Pie(init_opts=opts.InitOpts(width="1000px", height="600px", bg_color="#2c343c"))
.add(
series_name="博客等级", # 系列名称
data_pair=data, # 系列数据项,格式为 [(key1, value1), (key2, value2)]
rosetype="radius", # radius:扇区圆心角展现数据的百分比,半径展现数据的大小
radius="55%", # 饼图的半径
center=["50%", "50%"], # 饼图的中心(圆心)坐标,数组的第一项是横坐标,第二项是纵坐标
label_opts=opts.LabelOpts(is_show=False, position="center"), # 标签配置项
)
.set_global_opts(
title_opts=opts.TitleOpts(
title="博客等级分布",
pos_left="center",
pos_top="20",
title_textstyle_opts=opts.TextStyleOpts(color="#fff"),
),
legend_opts=opts.LegendOpts(is_show=False),
)
.set_series_opts(
tooltip_opts=opts.TooltipOpts(
trigger="item", formatter="{a}
{b}: {c} ({d}%)" # 'item': 数据项图形触发,主要在散点图,饼图等无类目轴的图表中使用
),
label_opts=opts.LabelOpts(color="#fff"),
)
.render("customized_pie.html")
)
运行效果如下: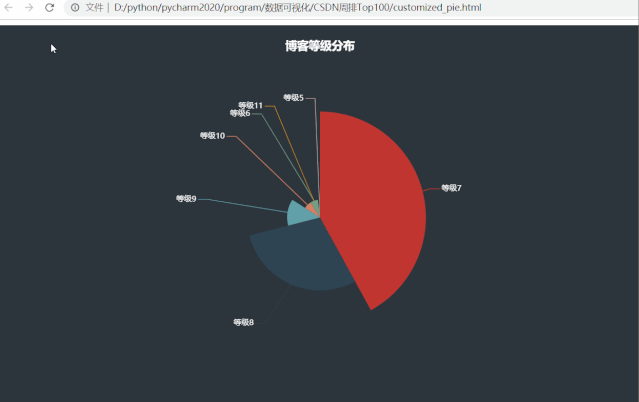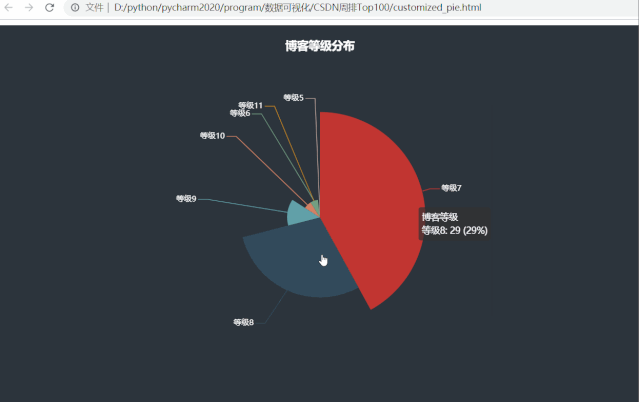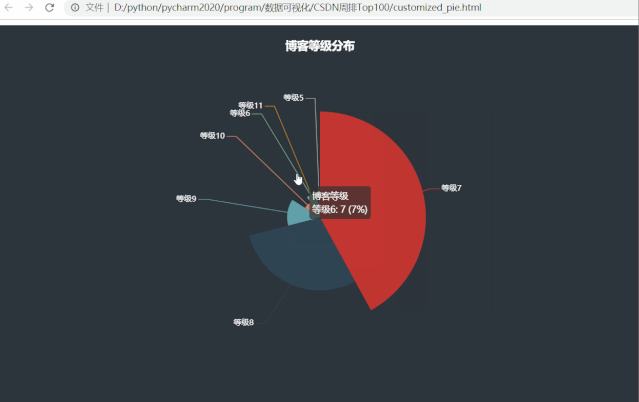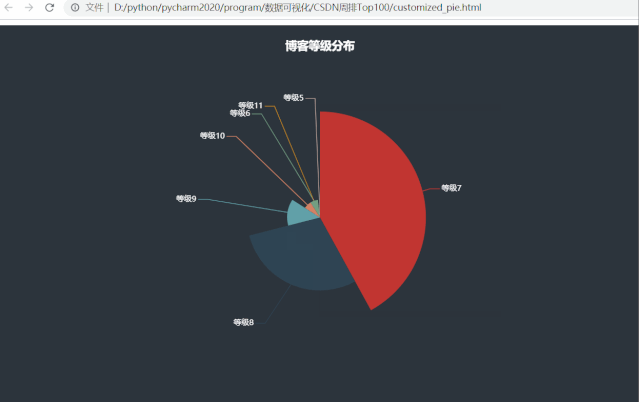
发现了一些有意思的事情,周排 Top100 的博主们博客等级大都分布在等级7、等级8,分别占比42%、29%,等级5和等级11的博主都仅有一位,看看他俩是谁
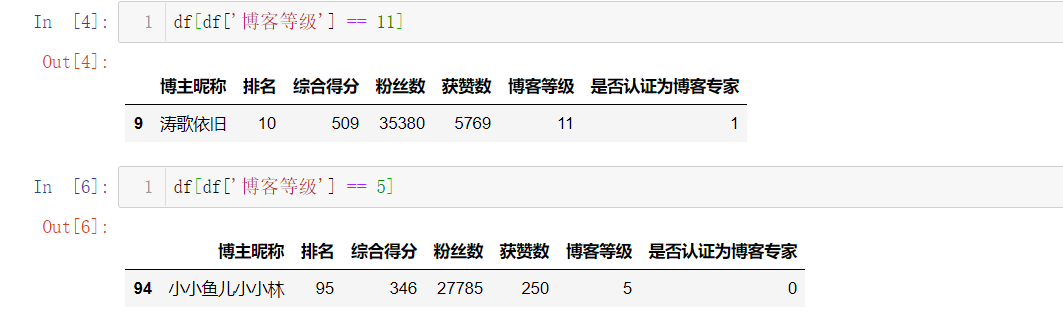
最后来看看这些博主粉丝数和获赞数对比
# -*- coding: UTF-8 -*-
"""
@File :粉丝数量对比.py
@Author :叶庭云
@CSDN :https://yetingyun.blog.csdn.net/
"""
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.globals import CurrentConfig, ThemeType
# 引用本地 js 资源
CurrentConfig.ONLINE_HOST = 'D:/python/pyecharts-assets-master/assets/'
# 读取数据 统计各博客等级博主的数量
df = pd.read_excel('rank_datas.xlsx')
nums = [int(x) for x in df['粉丝数']]
rank = [int(y) for y in df['排名']]
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.MACARONS))
.add_xaxis(xaxis_data=rank)
.add_yaxis(
series_name='粉丝数', yaxis_data=nums,
label_opts=opts.LabelOpts(is_show=False)
)
.set_global_opts(
xaxis_opts=opts.AxisOpts(name='排名'),
yaxis_opts=opts.AxisOpts(
name='粉丝数', min_=0, max_=320000, # y轴刻度的最小值 最大值
),
title_opts=opts.TitleOpts(
title="Top100博主的粉丝数对比",
title_textstyle_opts=opts.TextStyleOpts(
font_family="KaiTi", font_size=20, color="black"
)
)
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False),
markpoint_opts=opts.MarkPointOpts(
data=[
opts.MarkPointItem(type_="min", name="最小值"),
opts.MarkPointItem(type_="average", name="平均值")]),
markline_opts=opts.MarkLineOpts(
data=[
opts.MarkLineItem(type_="average", name="平均值")]))
.render('bar_chart.html')
)
运行效果如下: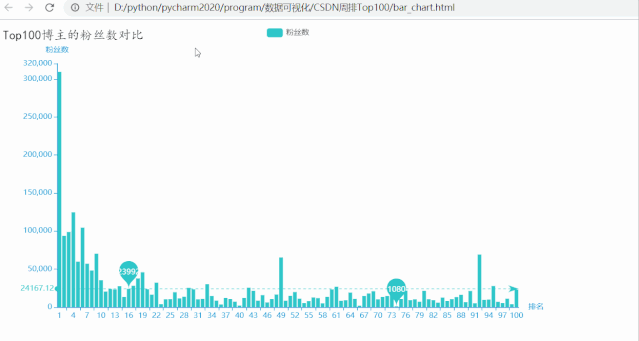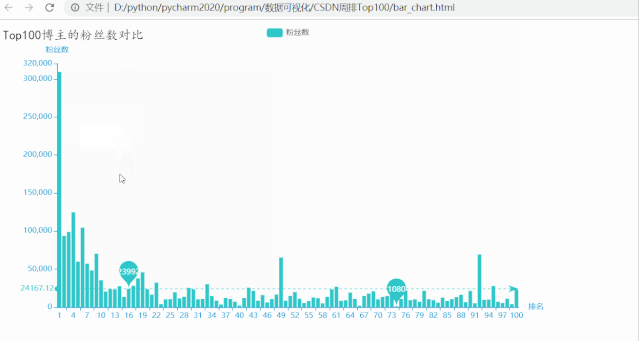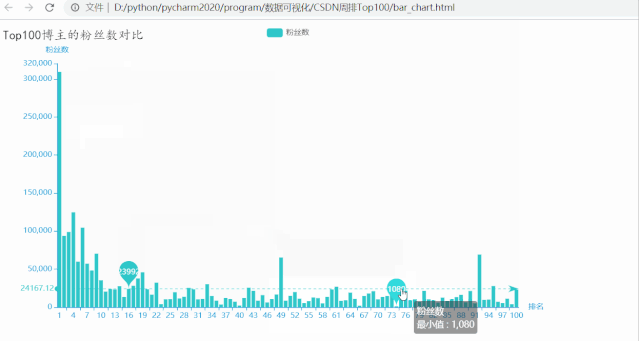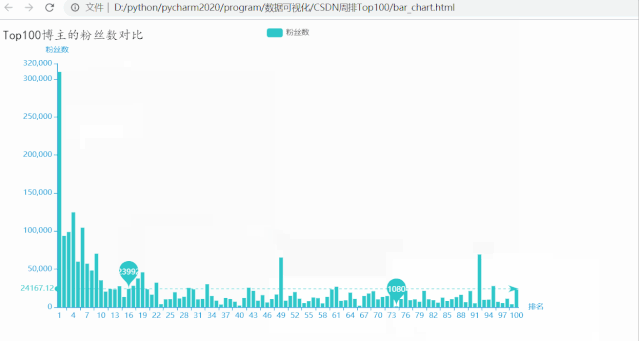
排名第一的博主粉丝数量超多,有309147位粉丝,远高于其他博主,粉丝数量最少的也有1080
# -*- coding: UTF-8 -*-
"""
@File :点赞数对比.py
@Author :叶庭云
@CSDN :https://yetingyun.blog.csdn.net/
"""
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.globals import CurrentConfig, ThemeType
# 引用本地 js 资源
CurrentConfig.ONLINE_HOST = 'D:/python/pyecharts-assets-master/assets/'
# 读取数据 统计各博客等级博主的数量
df = pd.read_excel('rank_datas.xlsx')
nums = [int(x) for x in df['获赞数']]
rank = [int(y) for y in df['排名']]
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.DARK))
.add_xaxis(xaxis_data=rank)
.add_yaxis(
series_name='获赞数', yaxis_data=nums,
label_opts=opts.LabelOpts(is_show=False)
)
.set_global_opts(
xaxis_opts=opts.AxisOpts(name='排名'),
yaxis_opts=opts.AxisOpts(
name='获赞数', min_=0, max_=40000, # y轴刻度的最小值 最大值
),
title_opts=opts.TitleOpts(
title="Top100博主的获赞数对比",
title_textstyle_opts=opts.TextStyleOpts(
font_family="KaiTi", font_size=20, color="#fff"
)
)
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False),
markpoint_opts=opts.MarkPointOpts(
data=[
opts.MarkPointItem(type_="max", name="最小值"),
opts.MarkPointItem(type_="min", name="最小值"),
opts.MarkPointItem(type_="average", name="平均值")]),
markline_opts=opts.MarkLineOpts(
data=[
opts.MarkLineItem(type_="average", name="平均值")]))
.render('bar_chart1.html')
)
运行效果如下:
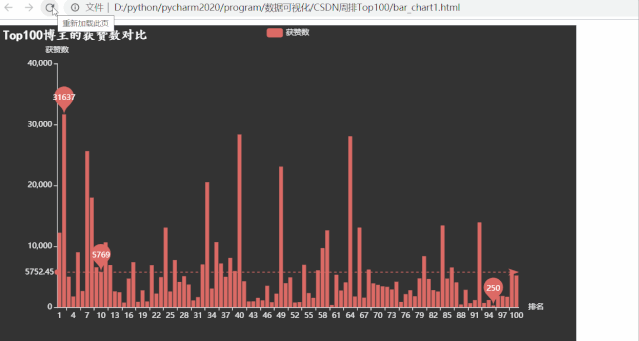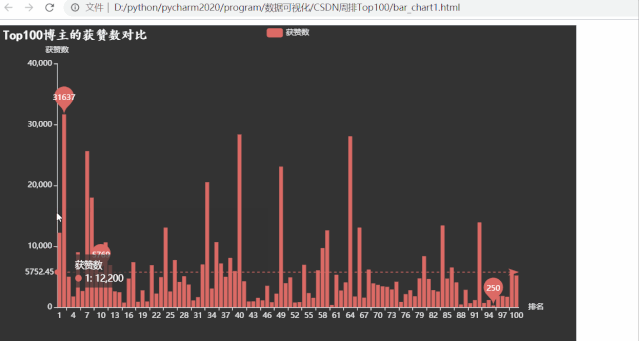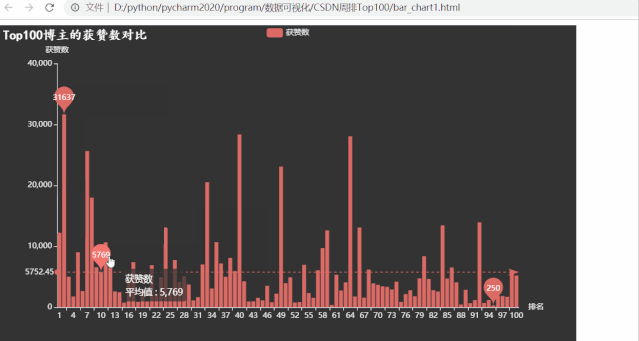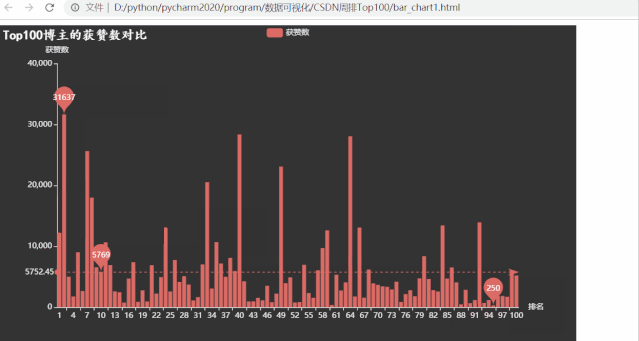
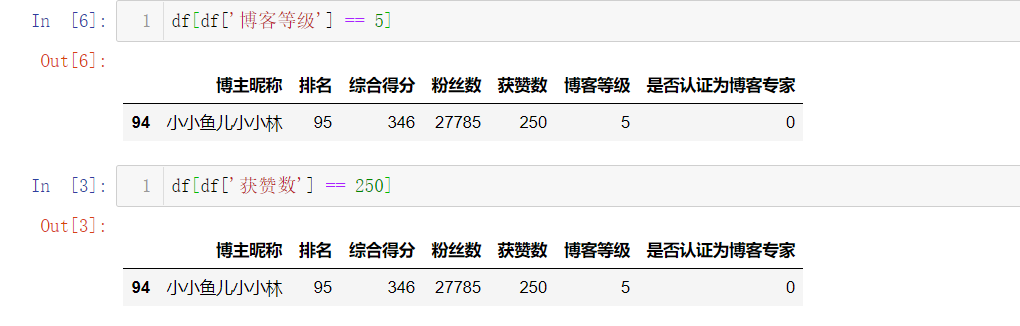
意想不到的事情发生了,粉丝数和综合评价都遥遥领先的 Top1 博主,获赞数不再领先,有很多位博主拥有的获赞数都比他多。而获赞数数量最少的仅有250,很是惊讶,写程序查看发现跟之前博客等级为5的是同一个博主,但这位博主粉丝数却不少。
庭云回到主页看着自己的博客数据,陷入了沉思~~
PS:公号内回复「Python」即可进入Python 新手学习交流群,一起 100 天计划!
老规矩,兄弟们还记得么,右下角的 “在看” 点一下,如果感觉文章内容不错的话,记得分享朋友圈让更多的人知道!


【神秘礼包获取方式】