
使用resnet, inception3进行fine-tune出现训练集准确率很高但验证集很低的问题

向AI转型的程序员都关注了这个号???
机器学习AI算法工程 公众号:datayx
最近用keras跑基于resnet50,inception3的一些迁移学习的实验,遇到一些问题。通过查看github和博客发现是由于BN层导致的,国外已经有人总结并提了一个PR(虽然并没有被merge到Keras官方库中),并写了一篇博客,也看到知乎有人翻译了一遍:Keras的BN你真的冻结对了吗
https://zhuanlan.zhihu.com/p/56225304
当保存模型后再加载模型去预测时发现与直接预测结果不一致也可能是BN层的问题。
总结:

显式设置
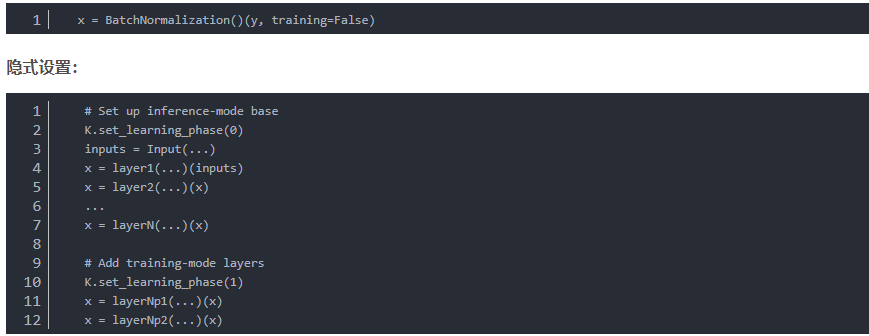
不可否认的是,默认的Frozen的BN的行为在迁移学习中确实是有training这个坑存在的,个人认为fchollet的修复方法更简单一点,并且这种方式达到的效果和使用预训练网络提取特征,单独训练分类层达到的效果是一致的,当你真的想要冻结BN层的时候,这种方式更符合冻结的这个动机;但在测试时使用新数据集的移动均值和方差一定程度上也是一种domain adaption。
译文:
虽然Keras节省了我们很多编码时间,但Keras中BN层的默认行为非常怪异,坑了我(此处及后续的“我”均指原文作者)很多次。Keras的默认行为随着时间发生过许多的变化,但仍然有很多问题以至于现在Keras的GitHub上还挂着几个相关的issue。在这篇文章中,我会构建一个案例来说明为什么Keras的BN层对迁移学习并不友好,并给出对Keras BN层的一个修复补丁,以及修复后的实验效果。
1. Introduction
这一节我会简要介绍迁移学习和BN层,以及learning_phase的工作原理,Keras BN层在各个版本中的变化。如果你已经了解过这些知识,可以直接跳到第二节(译者注:1.3和1.4跟这个问题还是比较相关的,不全是背景)。
1.1 迁移学习在深度学习中非常重要
深度学习在过去广受诟病,原因之一就是它需要太多的训练数据了。解决这个限制的方法之一就是迁移学习。
假设你现在要训练一个分类器来解决猫狗二分类问题,其实并不需要几百万张猫猫狗狗的图片。你可以只对预训练模型顶部的几层卷积层进行微调。因为预训练模型是用图像数据训练的,底层卷积层可以识别线条,边缘或者其他有用的模式作为特征使用,所以可以用预训练模型的权重作为一个很好的初始化值,或者只对模型的一部分用自己数据进行训练。
Keras包含多种预训练模型,并且很容易Fine-tune,更多细节可以查阅Keras官方文档。
1.2 Batch Normalization是个啥
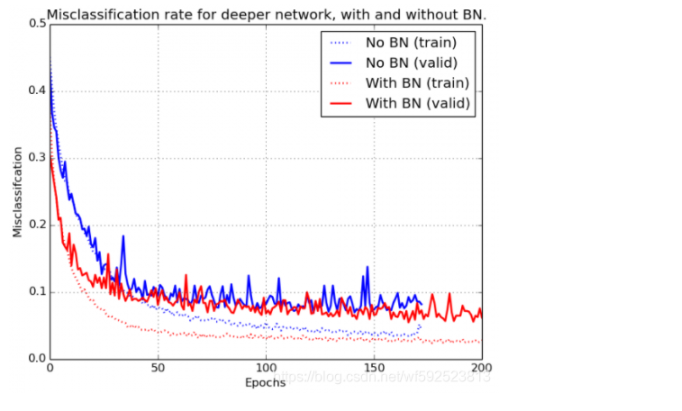
BN在2014年由Loffe和Szegedy提出,通过将前一层的输出进行标准化解决梯度消失问题,并减小了训练达到收敛所需的迭代次数,从而减少训练时间,使得训练更深的网络成为可能。具体原理请看原论文,简单来说,BN将每一层的输入减去其在Batch中的均值,除以它的标准差,得到标准化的输入,此外,BN也会为每个单元学习两个因子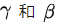 来还原输入。从下图可以看到加了BN之后Loss下降更快,最后能达到的效果也更好。
来还原输入。从下图可以看到加了BN之后Loss下降更快,最后能达到的效果也更好。
1.3 Keras中的learning_phase是啥
网络中有些层在训练时和推导时的行为是不同的。最重要的两个例子就是BN和Dropout层。对BN层,训练时我们需要用mini batch的均值和方差来缩放输入。在推导时,我们用训练时统计到的累计均值和方差对推导的mini batch进行缩放。
Keras用learning_phase机制来告诉模型当前的所处的模式。假如用户没有手工指定的话,使用fit()时,网络默认将learning_phase设为1,表示训练模式。在预测时,比如调用predict()和evaluate()方法或者在fit()的验证步骤中,网络将learning_phase设为0,表示测试模式。用户可以静态地,在model或tensor添加到一个graph中之前,将learning_phase设为某个值(虽然官方不推荐手动设置),设置后,learning_phase就不可以修改了。
1.4 不同版本中的Keras是如何实现BN的
Keras中的BN训练时统计当前Batch的均值和方差进行归一化,并且使用移动平均法累计均值和方差,给测试集用于归一化。
Keras中BN的行为变过几次,但最重要的变更发生在2.1.3这个版本。2.1.3之前,当BN被冻结时(trainable=False),它仍然会更新mini batch的移动均值和方差,并用于测试,造成用户的困扰(一副没有冻结住的样子)。
这种设计是错误的。考虑Conv1-Bn-Conv2-Conv3这样的结构,如果BN层被冻结住了,应该无事发生才对。当Conv2处于冻结状态时,如果我们部分更新了BN,那么Conv2不能适应更新过的mini-batch的移动均值和方差,导致错误率上升。
在2.1.3及之后,当BN层被设为trainable=False时,Keras中不再更新mini batch的移动均值和方差,测试时使用的是预训练模型中的移动均值和方差,从而达到冻结的效果, But is that enough? Not if you are using Transfer Learning.
2. 问题描述与解决方案
我会介绍问题的根源以及解决方案(一个Keras补丁)的技术实现。同时我也会提供一些样例来说明打补丁前后模型的准确率变化。
2.1 问题描述
2.1.3版本后,当Keras中BN层冻结时,在训练中会用mini batch的均值和方差统计值以执行归一化。我认为更好的方式应该是使用训练中得到的移动均值和方差(译者注:这样不就退回2.1.3之前的做法了)。原因和2.1.3的修复原因相同,由于冻结的BN的后续层没有得到正确的训练,使用mini batch的均值和方差统计值会导致较差的结果。
假设你没有足够的数据训练一个视觉模型,你准备用一个预训练Keras模型来Fine-tune。但你没法保证新数据集在每一层的均值和方差与旧数据集的统计值的相似性。注意哦,在当前的版本中,不管你的BN有没有冻结,训练时都会用mini-batch的均值和方差统计值进行批归一化,而在测试时你也会用移动均值方差进行归一化。因此,如果你冻结了底层并微调顶层,顶层均值和方差会偏向新数据集,而推导时,底层会使用旧数据集的统计值进行归一化,导致顶层接收到不同程度的归一化的数据。
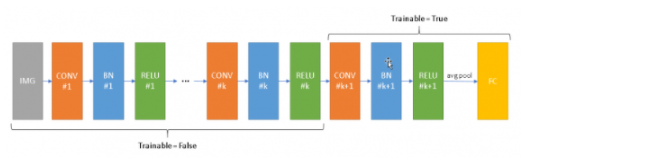
如上图所示,假设我们从Conv K+1层开始微调模型,冻结左边1到k层。训练中,1到K层中的BN层会用训练集的mini batch统计值来做归一化,然而,由于每个BN的均值和方差与旧数据集不一定接近,在Relu处的丢弃的数据量与旧数据集会有很大区别,导致后续K+1层接收到的输入和旧数据集的输入范围差别很大,后续K+1层的初始权重不能恰当处理这种输入,导致精度下降。尽管网络在训练中可以通过对K+1层的权重调节来适应这种变化,但在测试模式下,Keras会用预训练数据集的均值和方差,改变K+1层的输入分布,导致较差的结果。
2.2 如何检查你是否受到了这个问题的影响
分别将learning_phase这个变量设置为1或0进行预测,如果结果有显著的差别,说明你中招了。不过learning_phase这个参数通常不建议手工指定,learning_phase不会改变已经编译后的模型的状态,所以最好是新建一个干净的session,在定义graph中的变量之前指定learning_phase。
检查AUC和ACC,如果acc只有50%但auc接近1(并且测试和训练表现有明显不同),很可能是BN迷之缩放的锅。类似的,在回归问题上你可以比较MSE和Spearman‘s correlation来检查。
2.3 如何修复
如果BN在测试时真的锁住了,这个问题就能真正解决。实现上,需要用trainable这个标签来真正控制BN的行为,而不仅是用learning_phase来控制。具体实现在GitHub上。
主要是通过安装补丁:作者提供了三个版本的补丁,安装自己需要的版本就可以

用了这个补丁之后,BN冻结后,在训练时它不会使用mini batch均值方差统计值进行归一化,而会使用在训练中学习到的统计值,避免归一化的突变导致准确率的下降**。如果BN没有冻结,它也会继续使用训练集中得到的统计值。**
原文:
By applying the above fix, when a BN layer is frozen it will no longer use the mini-batch statistics but instead use the ones learned during training. As a result, there will be no discrepancy between training and test modes which leads to increased accuracy. Obviously when the BN layer is not frozen, it will continue using the mini-batch statistics during training.
2.4 评估这个补丁的影响
虽然这个补丁是最近才写好的,但其中的思想已经在各种各样的workaround中验证过了。这些workaround包括:将模型分成两部分,一部分冻结,一部分不冻结,冻结部分只过一遍提取特征,训练时只训练不冻结的部分。为了增加说服力,我会给出一些例子来展示这个补丁的真实影响。
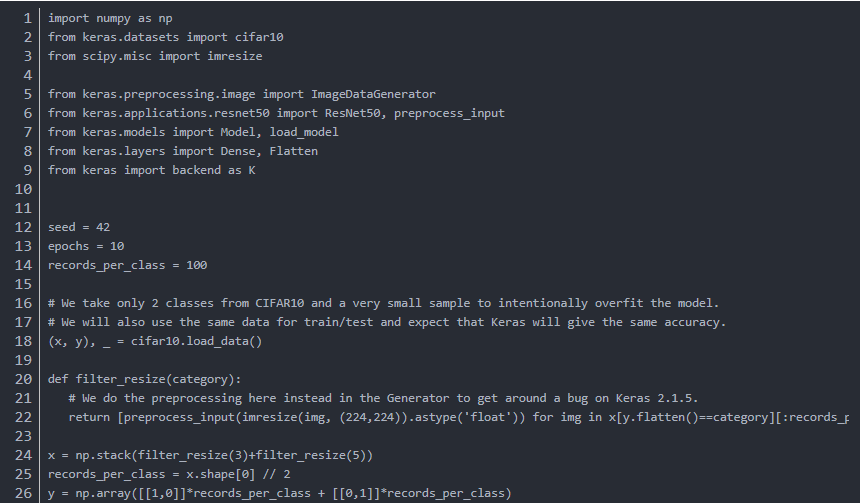
我会用一小块数据来刻意过拟合模型,用相同的数据来训练和验证模型,那么在训练集和验证集上都应该达到接近100%的准确率。
如果验证的准确率低于训练准确率,说明当前的BN实现在推导中是有问题的。
预处理在generator之外进行,因为keras2.1.5中有一个相关的bug,在2.1.6中修复了。
在推导时使用不同的learning_phase设置,如果两种设置下准确率不同,说明确实中招了。
代码如下:

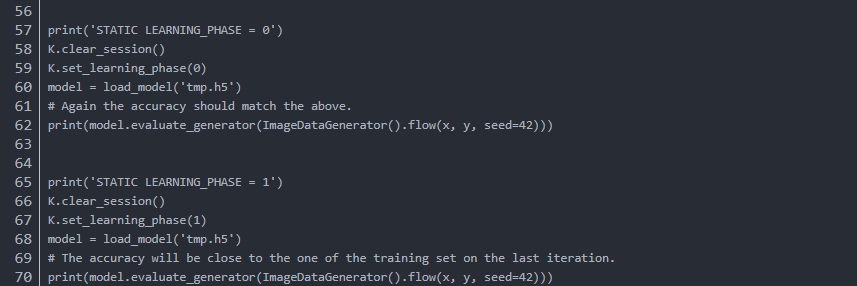
输出如下:
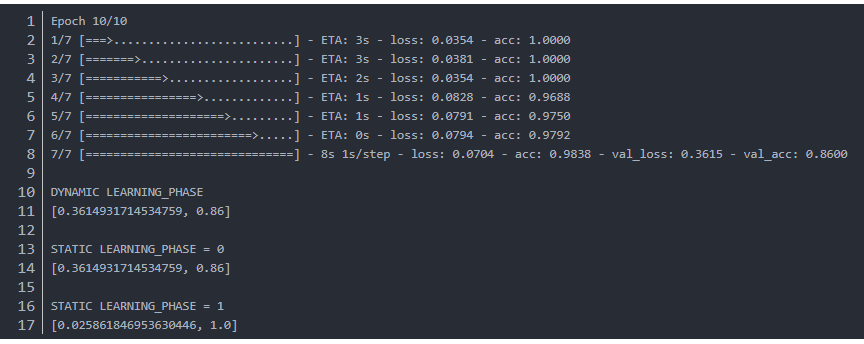
如上文所述,验证集准确率确实要差一些。
训练完成后,我们做了三个实验,DYNAMIC LEARNING_PHASE是默认操作,由Keras内部机制动态决定learning_phase,static两种是手工指定learning_phase,分为设为0和1.当learning_phase设为1时,验证集的效果提升了,因为模型正是使用训练集的均值和方差统计值来训练的,而这些统计值与冻结的BN中存储的值不同,冻结的BN中存储的是预训练数据集的均值和方差,不会在训练中更新,会在测试中使用。这种BN的行为不一致性导致了推导时准确率下降。
加了补丁后的效果:
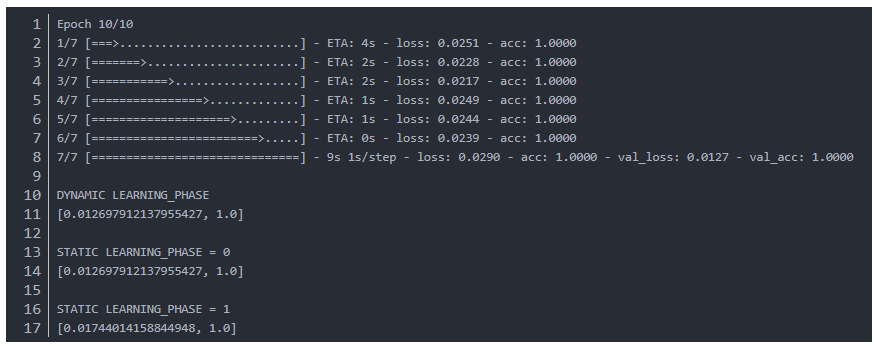
模型收敛得更快,改变learning_phase也不再影响模型的准确率了,因为现在BN都会使用训练集的均值和方差进行归一化。
2.5 这个修复在真实数据集上表现如何
我们用Keras预训练的ResNet50,在CIFAR10上开展实验,只训练分类层10个epoch,以及139层以后5个epoch。没有用补丁的时候准确率为87.44%,用了之后准确率为92.36%,提升了5个点。
2.6 其他层是否也要做类似的修复呢?
Dropout在训练时和测试时的表现也不同,但Dropout是用来避免过拟合的,如果在训练时也将其冻结在测试模式,Dropout就没用了,所以Dropout被frozen时,我们还是让它保持能够随机丢弃单元的现状吧。
参考文献:
https://zhuanlan.zhihu.com/p/56225304
http://blog.datumbox.com/the-batch-normalization-layer-of-keras-is-broken/
https://blog.csdn.net/wf592523813
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx
机大数据技术与机器学习工程
搜索公众号添加: datanlp
长按图片,识别二维码