
结合检测、人员追踪和姿势估计的案例分析
我们生活在一个不断发展的世界,安全已成为一项基本优先事项。在这个不断变化的时代,安全问题已经成为焦点。对安全的日益关注在各种公共场所明显,包括机场、学校、购物中心等等。这种关切源于人群中广泛存在的枪支。令人震惊的是,仅在2023年初,美国就因与枪支有关的暴力事件发生了超过2万起致命案件。这些令人担忧的统计数字强调了我们社会迫切需要进行讨论和采取行动,以提高安全性并遏制枪支在我们社会中造成的毁灭性影响。
 如今,公共和私人空间的监控主要由 人工操作员进行,这带来了一些问题。其中包括操作员同时监视多个摄像头的挑战,以及可能导致在关键情况下反应不及时的潜在干扰。因此,实施能够在某种程度上自动化该过程的先进监控系统变得至关重要。
如今,公共和私人空间的监控主要由 人工操作员进行,这带来了一些问题。其中包括操作员同时监视多个摄像头的挑战,以及可能导致在关键情况下反应不及时的潜在干扰。因此,实施能够在某种程度上自动化该过程的先进监控系统变得至关重要。
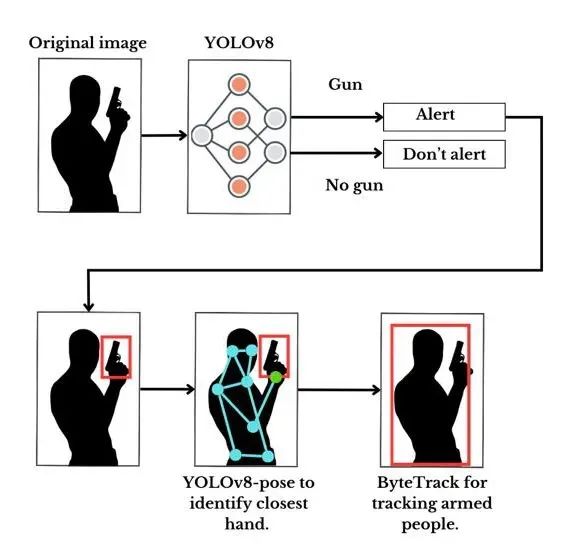
本工作提出了使用人工智能进行武器检测和个体追踪的系统的设计和开发。 本文将详细阐述使用YOLO实现目标检测、使用ByteTrack进行人员追踪以及使用OpenVINO进行模型优化的过程,旨在创建一个增强安全和监控的解决方案。
目标
该项目的目标如下:
1. 在视频中进行实时枪支检测。
2. 优化检测模型,提高视频处理效率并减少推断时间。
3. 追踪携带武器的个体,实时监控感兴趣的人。
已实施的模块
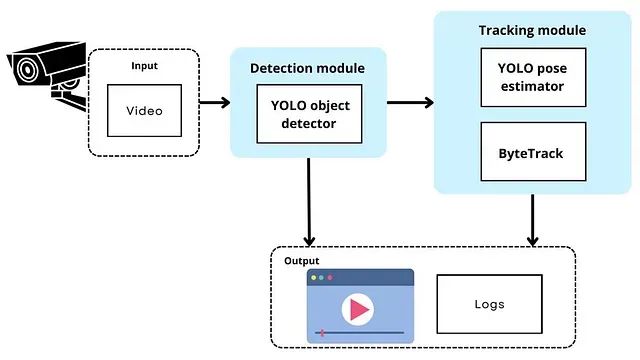
为实现这些目标,实施了两个模块:
-
检测模块:集成了一个经过预训练以识别武器并经过优化以减少推断时间的YOLO目标检测器。
-
追踪模块:负责估计个体的姿态并追踪它们。稍后将提供有关为何进行姿态估计的理由的进一步解释,这对于识别感兴趣的人物至关重要。
系统的输入是一个视频,可以是MP4、AVI或其他常见视频格式。这两个模块的联合输出结果是一个MP4视频,突出显示武器检测和人员追踪。此外,生成并存储了包含有关使用的检测方法和推断时间的详细信息的日志。
使用YOLO进行目标检测

为了检测武器,选择了速度快且在实时目标检测中效果显著的YOLO算法。YOLO代表"You Only Look Once",是一种通过将图像分成网格并预测每个网格单元内对象的边界框和类别概率来运行的目标检测算法。它在神经网络中进行一次前向传递,以其速度和实时性而闻名。YOLO能够高效地处理整个图像,同时预测多个对象,因此在各种计算机视觉任务中备受青睐。
在此项目中,进行了YOLOv5、YOLOv7和YOLOv8的测试。在初始实验阶段,YOLOv7实现了更高的准确性。然而,截至当前开发阶段,决定使用Ultralytics的YOLOv8。

使用的数据集
进行了多个数据集的实验,但最终的最佳模型是根据Ultralytics的建议达到的:
-
每类图像:每类建议≥1500张图像。
-
每类实例:每类建议≥10000个实例(标记的对象)。
-
图像多样性:必须代表已部署环境。对于实际用例,建议使用不同时间、不同季节、不同天气、不同光照、不同角度、不同来源(在线抓取、本地收集、不同相机等)的图像。
为了评估之前训练的模型,使用了不同的数据集进行测试,该数据集由安全摄像头的视频帧组成,并进行了预先标记。

使用ByteTrack追踪个体

在追踪人员方面,有各种不同的方法,但它们通常会面临一些问题,比如当人们部分隐藏或改变大小时,跟踪就会出现问题,导致路径分散和身份转变。然而,在当前技术水平上一个有希望的解决方案是ByteTrack,它旨在克服这些追踪问题。
Byte Track的运作方式

通常,为了追踪多个对象,会使用得分高于某个阈值(如0.5)的检测框。 然后,追踪器与这些检测框相关联,基于它们的相似性进行配对。
例如,在上面的图像中,初始化了三个不同的轨迹,因为它们的得分都高于0.5。然而,在遮挡期间,与红色轨迹相关联的检测置信度从0.8降到0.4,然后从0.4降到0.1。由于这些检测框低于阈值,它们被移除,导致红色轨迹消失。
ByteTrack保留所有检测框并将它们分类为两组:得分高和得分低。这种方法分两个阶段进行。在第一阶段,根据运动的相似性(使用交并比)或预测框之间的外观与重新识别功能,将高得分的检测框与轨迹进行匹配。在第二阶段,再次使用运动相似性作为标准,在未配对的轨迹和得分低的检测框之间进行第二次匹配过程。
因此,使用ByteTrack解决了追踪的“如何”问题…但“追踪谁”呢?嗯,最初的想法是追踪离武器最近的人。如果有人靠近武器,他们被视为嫌疑人。但是出现了一个问题,如果武器离受害者很近,追踪会集中在受害者而不是感兴趣的人。
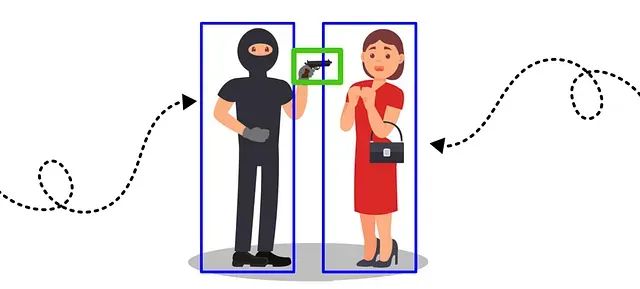
因此,提出的解决方案是识别每个人的手 的位置并追踪手最靠近武器的人,即实际持有武器的人。此时,就用到了姿势估计。
姿势估计
为了实现手的识别,使用了一种称为姿势估计的东西。姿势估计是一项计算机视觉任务,涉及在图像和视频中检测人体形象并理解其身体姿态。
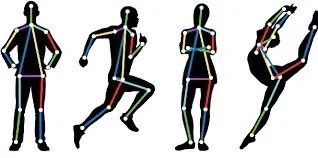
有两种方法:自下而上和自上而下。自下而上的方法首先估计每个身体关节,然后将它们组合成一个单一的姿势。另一方面,自上而下的方法首先运行一个人体检测器,然后在检测到的边界框内估计身体关键点。为此,使用了一个名为“yolov8-pose”的Ultralytics模型。这是一个为人体姿势估计训练的自上而下模型。该模型识别一个人体上的17个关键点,其中两个点对应于手。
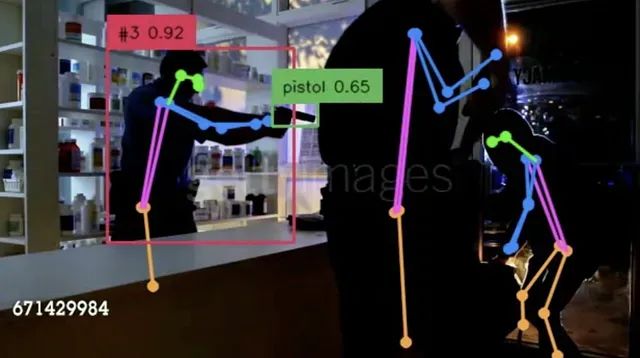
因此,将一切结合在一起就是:检测人和他们的姿势,并计算手和检测到的武器的边界框之间的距离。
下面,我们提供了一个清晰的例子,展示了有和没有姿势估计的追踪。
模型优化
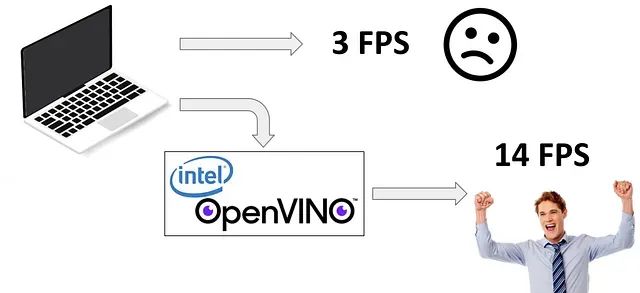
我们遇到了特定的硬件限制,但幸运的是,我们有OpenVINO等工具显著提高了推断时间。OpenVINO是由英特尔开发的,旨在与图形卡竞争。它通过将浮点数量子化为仅使用8或16位的32或64位,通过舍入值来实现这一点。它在资源有限的设备上特别有用,例如移动设备或嵌入式系统。在下图中,有一些有和没有优化的检测的例子。
有趣的一点是,在优化过程中,通过牺牲一些精度来获得更好的速度。然而,在某些情况下,精度的损失并不显著,如下图中的(C)和(D)所示,它允许对感兴趣的人进行准确的追踪。在图(B)中,您可以看到优化模型失去精度的一个例子,检测到不存在的武器,导致对戴帽子的男子和收银台的女子进行错误的追踪。

挑战
这 个项目中的挑战包括:
-
找到一个准确代表现实情景的数据集。
-
当武器部分遮挡或模糊时,检测准确性下降。
-
由于文档中的差异,使用OpenVINO进行模型优化带来了挑战。
最后的想法
总之,在解决追踪、检测和优化方面的挑战时,演示了ByteTrack和OpenVINO等工具的潜力,并且姿势估计的整合为该过程添加了一层准确性。希望这次探索为现代人工智能解决方案的复杂性提供了有价值的见解。