
学习关于 2D 和 3D 姿势估计的知识
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
介绍
让我们了解一下如何将姿势估计用于 Snapchat 滤镜。你有没有想过 Snapchat 的滤镜为什么这么吸引人?Snapchat 上的滤镜种类繁多,从有趣的到化妆的滤镜。这更像是滑动滤镜并选择一个你感兴趣的滤镜来拍照。
阅读本文并不需要任何有关姿势估计的基础知识。本文从头到尾总结了有关姿态估计的所有关键点和重要主题。文章的开头包括什么是姿态估计以及为什么我们必须了解姿态估计。本文从头部、手部、人体、2D、3D 以及更多姿势估计中描述了多种姿势估计。之后,我们将使用各种公共数据集,用于使用流行算法进行姿势估计。
阅读本文后,你将获得所有与 2D 姿态估计和 3D 姿态估计相关的信息,以及一个使用 OpenPose 算法进行 2D 人体姿态估计的迷你项目。
什么是姿势估计?
姿势估计是一种在图像或视频中检测对象或人的位置和轨迹的计算机视觉技术。该过程通过查看给定对象或人的姿势方向组合来执行。根据点的方向,我们可以比较一个人或一个对象的各种时刻和姿势,并得出一些见解。
姿态估计主要是通过识别对象/人的关键点,甚至通过识别位置来完成的。
对于对象:关键点将是对象的角或边缘。
对于图像:包含人类的图像,关键点可以是肘部、手腕、手指、膝盖等。
计算机视觉中最令人兴奋的研究领域之一是各种类型的姿态估计。使用姿势估计技术有很多好处。

姿态估计的应用
如今,在市场上,有大量使用计算机视觉技术的应用程序。特别是由于有效的跟踪系统和姿态估计的测量。让我们通过示例来看看姿势估计的一些应用。
1) 增强现实元宇宙
元宇宙突破科技界,吸引了从年轻人到老年人的普遍关注。元宇宙将 3D 元素固定在现实世界中的对象/人上,使它们看起来非常真实,为人们创造了一个进入另一个宇宙的环境,并有助于体验奇妙的事物。适用于元宇宙解决方案的应用程序是姿势估计、眼动追踪、语音和面部追踪。
姿态估计的有用用例之一是在美国陆军中使用,它们可以区分敌军和友军。
2) 医疗保健和健身行业
新冠时代,健身行业高速发展,有无数消费者加入了疯狂的健身行列。健身应用的快速增长提供了高效的健康监测图表和健身计划。
此外,一些应用程序在错误检测和向消费者反馈方面提供了令人惊讶的结果。这些应用程序利用计算机视觉中的姿势估计技术来最大程度地减少锻炼时受伤的可能性。
3) 机器人
姿势估计被集成到机器人技术中。它被应用于机器人的训练中,他们学习人的动作。
为什么我们使用姿势估计?
人的检测在检测部分中起着主要作用。随着机器学习(ML)算法的最新发展,姿势检测和姿势跟踪很容易使用。
在对象检测等传统方法中,我们只能被感知为一个方形边界框。随着姿势检测和姿势跟踪的进步,机器可以轻松学习人体语言。在姿态估计的帮助下,我们可以在粒度级别跟踪对象。这些强大的技术为在现实世界中应用开辟了广泛的可能性。
为了跟踪人类的运动和活动,姿势估计具有多个应用范围,例如增强现实、医疗保健部门和机器人技术。例如,人体姿态估计可以以多种方式使用,例如通过结合人体姿态估计和距离投影启发式方法来保持银行队列中的社交距离。它将帮助人们保持银行中的卫生规则和规定,也有助于在人满为患的地方保持物理距离。
另一个可以使用姿势跟踪和姿势估计的例子是在自动驾驶汽车中。当车辆无法理解行人行为时,大多数事故都是由自动驾驶汽车引起的。在姿态估计的帮助下,模型将得到更好的训练。
多人姿态估计方法
用于姿态估计的两种常用方法:
1)自上而下的方法:
首先,我们将检测人并在每个人周围制作边界框。然后我们将估计身体的部位。之后,我们可以将每个关节分类为正确的人。这种方法被称为自上而下的方法。
2) 自下而上的方法:
首先,我们将检测图像中的所有部分,然后关联/分组属于不同人的部分。这种方法被称为自下而上的方法。
在一般情况下,自上而下的方法比自下而上的方法消耗更多的时间。
姿势估计模型
近年来,随着深度学习解决方案的快速发展,它在姿势估计等多项任务(包括图像分割和对象检测)中的表现优于一些计算机视觉方法。
存在几种用于姿势估计的模型。模型选择取决于问题的要求。在选择模型时,我们还需要考虑无数因素,可以是运行时间、模型的大小等等。
在这里,我将列出互联网上最流行的姿势估计库。我们可以根据我们的用例轻松自定义它们。
OpenPose
High-Resolution Net (HRNet)
Blaze pose
Regional Multi-Person Pose Estimation (AlphaPose)
Deep Pose
PoseNet
Dense pose
Deep cut
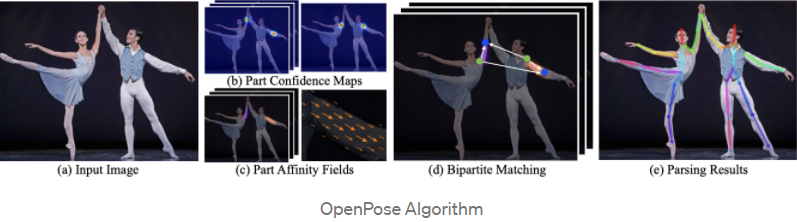
1) OpenPose
OpenPose 被称为基于开源视频的人体姿态估计。OpenpPose 架构在预测多人姿态估计方面很受欢迎。令人惊奇的事情之一是 Openpose 是其开源的实时多人检测架构。它使用自下而上的方法进行多人人体姿态估计。
OpenPose 在单张图像的总共 135 个关键点中估计身体、脚、手和面部关键点的姿势时具有很高的准确性。OpenPose 的主要优点是 API 可以让用户控制选择图像源并提供多个选项。我们还可以从摄像头、网络摄像头和嵌入式系统(CCTV 摄像头和系统)中选择图像。
OpenPose 的优点之一是它的精度高,不会影响执行性能。它在速度和准确性之间具有轻微的平衡(即 R-CNN 运行得更快)
OpenPose 论文:https://cmu-perceptual-computing-lab.github.io/openpose/web/html/doc/index.html
OpenPose 文档 :https://www.arxiv-vanity.com/papers/1611.08050/)
代码的 Github 链接:https://github.com/CMU-Perceptual-Computing-Lab/openpose
2) High-Resolution Net (HRNet)
HRNet 被称为高分辨率网络。对于人体姿态估计,我们使用 HRNet 神经网络。HRNet 是人体姿态估计领域最先进的算法。HRNet 在电视体育运动中的人体姿势检测中得到了广泛应用。
HRNet 使用卷积神经网络 (CNN),它类似于神经网络,但主要区别在于模型的架构。普通神经网络不能很好地使用图像数据集进行扩展,而卷积神经网络提供了很好的输出。
即使是普通的神经网络工作也非常缓慢,因为所有隐藏层都相互连接,这导致模型运行速度变慢。例如,如果我们的图像大小为 32 *32* 3,那么我们将有 3072 个权重,这太大了。在输入这些数据时,它会减慢神经网络的速度。
HRNet 论文:https://jingdongwang2017.github.io/Projects/HRNet/PoseEstimation.html
代码的 Github 链接:https://github.com/leoxiaobin/deep-high-resolution-net.pytorch
3) Blaze pose
BlazePose 是一种机器学习 (ML) 模型,可与 ailia SDK 一起使用。BlazePose 由 Google 开发,最多可计算 33 个骨架关键点,主要用于健身应用。BlazePose 根据下面的图表排序约定将 33 个关键点作为模型的输出。这使我们能够仅从与面部和手部模型一致的姿势预测中确定身体语义。我们可以通过 ailia SDK(https://ailia.jp/en/) 轻松地使用 BlazePose 模型,创建 AI 应用程序。
Blaze Pose 论文:https://cmu-perceptual-computing-lab.github.io/openpose/web/html/doc/index.html
此处找到文档 :https://www.arxiv-vanity.com/papers/1611.08050/
用于检查代码的 Github 链接:https://github.com/CMU-Perceptual-Computing-Lab/openpose
要了解有关 BlazePose 的更多信息,请关注此博客:https://ai.googleblog.com/2020/08/on-device-real-time-body-pose-tracking.html
4)Regional Multi-Person Pose Estimation (AlphaPose)
AlphaPose 是一个实时多人人体姿态估计系统。一种流行的自顶向下方法,使用 AplhaPose 数据集进行人体姿态估计。当有不准确的人体边界框时,Aplhapose 就会出现,并且非常准确。
我们可以在 AplhaPose 的帮助下从图像或视频或图像列表中检测单个人或多个人。它是被称为 PoseFlow 的姿势跟踪器,它也是开源的。AlphaPose 是在 PoseTrack Challenge 数据集上同时满足 60+ mAP (66.5 mAP) 和 50+ MOTA (58.3 MOTA) 的跟踪器。

姿势估计的分类
通常,姿态估计分为两组:
单姿势估计:从图像或视频中检测单个对象或人
多姿势估计:从图像或视频中检测多个对象或人
姿态估计有多种类型
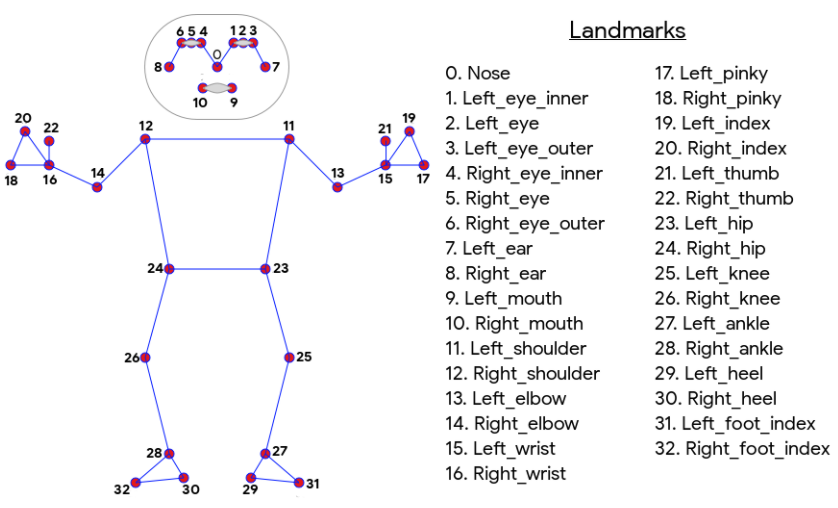
人体姿态估计
刚性姿态估计
2D 姿态估计
3D 姿态估计
头部姿势估计
手部姿势估计
1) 人体姿态估计
处理人体图像或视频时的关键点估计,其中关键点可以是肘部、手指、膝盖等。这称为人体姿势估计。
2)刚性姿势估计
不属于柔性对象类别的对象是刚性对象。例如,无论砖块的方向如何,砖块的边缘总是处于相同的距离,因此预测这些对象的位置被称为刚性姿势估计。
3) 2D 姿态估计
它根据像素级别从图像中预测关键点估计。在 2D 估计中,我们简单地估计与输入数据相关的 2D 空间中位置的关键点。关键点的位置用 X 和 Y 表示。
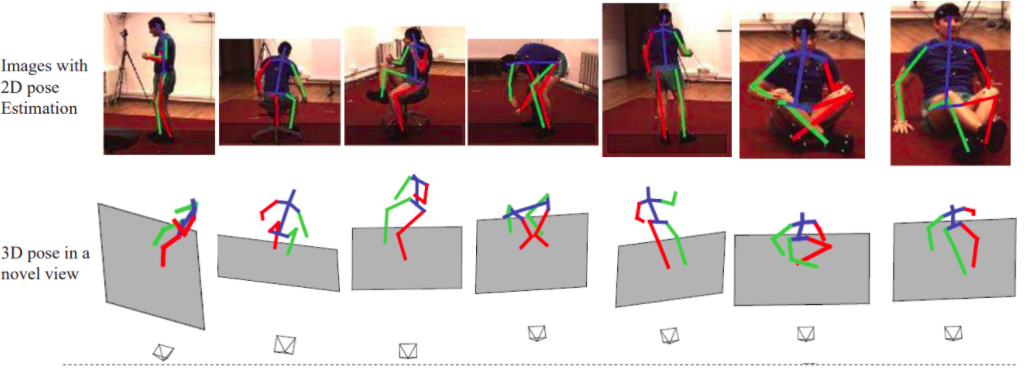
4) 3D 姿态估计
它预测所有对象/人的三维空间排列作为其最终输出。首先,通过附加的 z 轴将对象从 2D 图像转换为 3D 图像以预测输出。
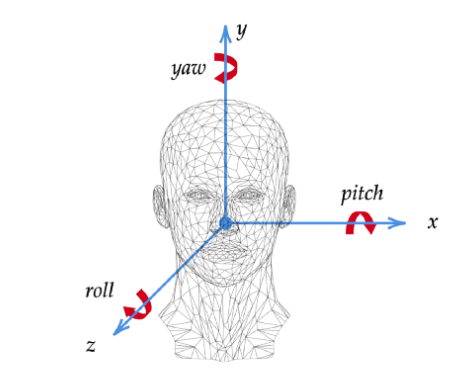
5)头部姿势估计
寻找一个人的头部姿势的位置正在成为计算机视觉中的一个流行用例。头部姿势估计的最佳应用之一是 Snapchat,我们在脸上使用各种滤镜让我们看起来很有趣。此外,我们在 Instagram 滤镜和 Snapchat 中使用头部姿势估计,我们还可以在自动驾驶汽车中使用它来跟踪驾驶员在驾驶时的活动。
头部姿势估计有多种应用,例如在 3D 游戏中建模注意力和执行面部对齐。为了在 3D 姿势中进行头部姿势估计,我们需要借助深度学习模型从 2D 图像姿势中找到面部关键点。
阅读有关头部姿势估计的信息:https://medium.com/towards-data-science/head-pose-estimation-with-hopenet-5e62ace254d5
6) 手部姿势估计
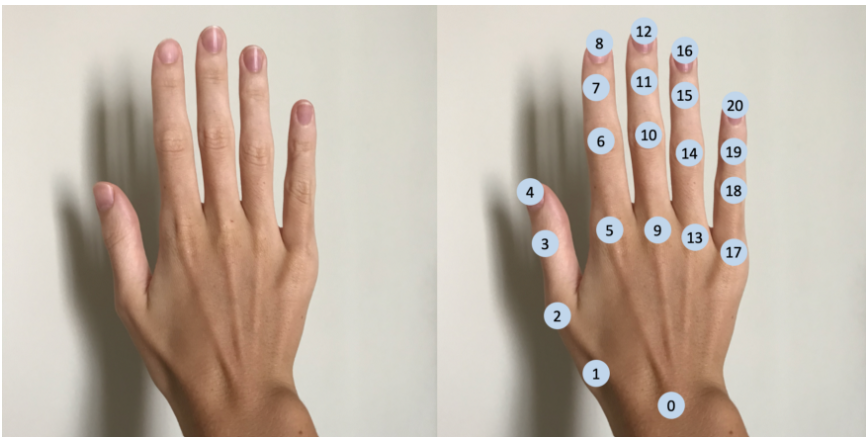
手部姿势估计旨在从图像中预测手部关节的位置,并且由于 VR/AR/MR 技术的出现而变得流行。在手部姿态估计中,关键点是手部关节的位置。手总共有21个关键点,其中包括手腕,5个手指用于关键点的位置。
人体姿态估计数据集
各种数据集可用于人体图像和视频的姿态估计。在这里,我列出了一些数据集供你制作模型和探索。我将根据图像和视频的类别来解释数据集包含的内容。此外,将提供有关数据集及其性能的一些基本信息。
MPII
COCO
HumanEva
Human3.6M
SURREAL – Synthetic hUmans foR REAL tasks
1)MPII
MPII 人体姿势数据集包含大量人体姿势的数据,其中包括大约 25K 图像,其中 包含超过 40K 个带有注释的身体关节的人。MPII 人体姿态数据集是用于评估关节式人体姿态估计的最先进的基准。
2014 年第一个发起 2D 姿势估计挑战的数据集是 MPII 人体姿势,它也是第一个包含如此多样化姿势的数据集。这些数据包含从 Youtube 视频中收集的人类活动图像。总共有 410 个人类活动图像,上面有活动标签。每个图像都是从 YouTube 视频中提取的,并提供了前后未注释的帧。此外,对于测试集,我们获得了更丰富的注释,包括身体部位遮挡、 3D 躯干和头部方向。
你可以在此处找到 MPII 人体姿势数据集:http://human-pose.mpi-inf.mpg.de/

2) COCO
COCO 是一个用于对象检测、分割和字幕数据的大规模数据集,也是一个从 Flickr 收集的图像的多人 2D 姿态估计数据集。COCO 数据集有 80 个对象类别和 91 个东西类别。
迄今为止最大的 2D 姿态估计数据集之一是 COCO,它正在考虑测试 2D 姿态估计算法的基准。
COCO 数据集:https://cocodataset.org/#home

3) HumanEva
HumanEva 数据集由人类 3D 姿势估计的视频序列组成,这些视频序列是使用不同的摄像机(例如多个 RGB 和灰度摄像机)记录的。HumanEva 是第一个相当大的 3D 姿势估计数据集。
HumanEva-I 数据集包含 7 个视频序列,分别是:4 个灰度和 3 个颜色。令人惊奇的是,它们与从动作捕捉系统获得的 3D 身体姿势同步。HumanEva 数据库包含 4 名受试者执行 6 种常见动作(例如步行、慢跑、手势等)。向参与者提供计算 2D 和 3D 姿势误差的误差度量。数据集包含训练、验证和测试集。
HumanEva 数据集:http://humaneva.is.tue.mpg.de/
4) SURREAL
SURREAL 这个名字来源于Synthetic hUmans for RREAL tasks。SURREAL 包含 2D/3D 姿势估计数据中的单人虚拟视频动画。它是使用实验室记录的动作捕捉数据创建的。第一个为 RGB 视频输入生成深度、身体部位、光流、2D/3D 姿势、表面法线地面实况的大型人物数据集。
该数据集包含600 万帧合成人。这些图像是人物在形状、纹理、视点和姿势的巨大变化下的照片般逼真的渲染。为确保真实感,合成体是使用 SMPL 模型创建的,其参数通过 MoSh 方法拟合给定原始 3D MoCap 标记数据。
SMPL模型:http://smpl.is.tue.mpg.de/
MoSh方法:https://ps.is.tuebingen.mpg.de/research_projects/mosh

3d 人体姿态估计 SURREAL 数据集:https://www.di.ens.fr/willow/research/surreal/data/
机器学习中的人体姿势估计代码
让我们开始人体姿势估计的实现
第一步是创建一个用于存储项目的新文件夹。最好做一个虚拟环境,然后加载 OpenPose 算法,而不是下载到你的正常环境中。
为姿势估计创建 Anaconda 环境。在 ' myenv ' 中为环境输入任何名称。
conda create --name myenv
现在让我们在这个环境中工作,我们将为其激活环境
conda activate myenv
安装最新版本的python
conda create -n myenv python=3.9
人体姿态估计的代码受到 OpenPose 算法的 OpenCV 示例的启发。
现在我们将编写人体姿态估计的代码。我们从此链接(https://github.com/quanhua92/human-pose-estimation-opencv)下载 zip 文件。
首先,我们导入所有库。
import cv2 as cv
import matplotlib.pyplot as plt
现在,我们将加载权重。权重存储在graph_opt.pb文件中,并将权重存储到net变量中。
net = cv.dnn.readNetFromTensorflow(r"graph_opt.pb")
初始化图像的高度、宽度和阈值。
inWidth = 368
inHeight = 368
thr = 0.2
我们将使用 18 点模型进行人体姿态估计。该模型在 COCO 数据集上进行训练,其中关键点的编号以以下格式完成。
BODY_PARTS = { "Nose": 0, "Neck": 1, "RShoulder": 2, "RElbow": 3, "RWrist": 4,
"LShoulder": 5, "LElbow": 6, "LWrist": 7, "RHip": 8, "RKnee": 9,
"RAnkle": 10, "LHip": 11, "LKnee": 12, "LAnkle": 13, "REye": 14,
"LEye": 15, "REar": 16, "LEar": 17, "Background": 18 }
定义用于创建连接所有关键点的肢体的姿势对。
POSE_PAIRS = [ ["Neck", "RShoulder"], ["Neck", "LShoulder"], ["RShoulder", "RElbow"],
["RElbow", "RWrist"], ["LShoulder", "LElbow"], ["LElbow", "LWrist"],
["Neck", "RHip"], ["RHip", "RKnee"], ["RKnee", "RAnkle"], ["Neck", "LHip"],
["LHip", "LKnee"], ["LKnee", "LAnkle"], ["Neck", "Nose"], ["Nose", "REye"],
["REye", "REar"], ["Nose", "LEye"], ["LEye", "LEar"] ]
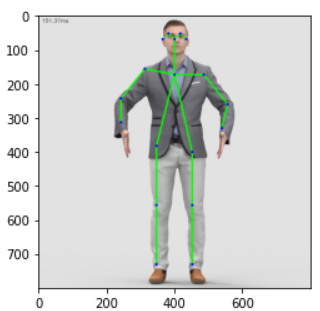
让我们看看原图是什么样子的。
img = plt.imread("image.jpg")
plt.imshow(img)
为了为每个关键点生成置信度图,我们将在原始输入图像上调用 forward 函数。
net.setInput(cv.dnn.blobFromImage(frame, 1.0, (inWidth, inHeight), (127.5, 127.5, 127.5), swapRB=True, crop=False))
这是完成人体姿态估计预测的主要代码。
def pose_estimation(frame):
frameWidth = frame.shape[1]
frameHeight = frame.shape[0]
net.setInput(cv.dnn.blobFromImage(frame, 1.0, (inWidth, inHeight), (127.5, 127.5, 127.5), swapRB=True, crop=False))
out = net.forward()
out = out[:, :19, :, :]
assert(len(BODY_PARTS) == out.shape[1])
points = []
for i in range(len(BODY_PARTS)):
# Slice heatmap of corresponging body's part.
heatMap = out[0, i, :, :]
_, conf, _, point = cv.minMaxLoc(heatMap)
x = (frameWidth * point[0]) / out.shape[3]
y = (frameHeight * point[1]) / out.shape[2]
# Add a point if it's confidence is higher than threshold.
# combining all the key points.
points.append((int(x), int(y)) if conf > thr else None)
for pair in POSE_PAIRS:
partFrom = pair[0]
partTo = pair[1]
assert(partFrom in BODY_PARTS)
assert(partTo in BODY_PARTS)
idFrom = BODY_PARTS[partFrom]
idTo = BODY_PARTS[partTo]
if points[idFrom] and points[idTo]:
cv.line(frame, points[idFrom], points[idTo], (0, 255, 0), 3)
cv.ellipse(frame, points[idFrom], (3, 3), 0, 0, 360, (0, 0, 255), cv.FILLED)
cv.ellipse(frame, points[idTo], (3, 3), 0, 0, 360, (0, 0, 255), cv.FILLED)
t, _ = net.getPerfProfile()
freq = cv.getTickFrequency() / 1000
cv.putText(frame, '%.2fms' % (t / freq), (10, 20), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0))
return frame
调用 main 函数在原始未编辑图像上生成关键点。
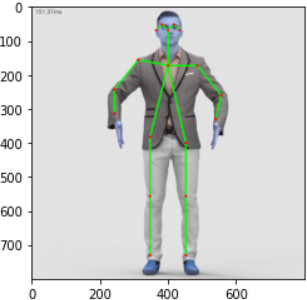
estimated_image = pose_estimation(img)
让我们看看图片看起来如何
plt.imshow(img)
如果我们想在关键点上看到 RGB 格式的图像。
plt.imshow(cv.cvtColor(estimated_image, cv.COLOR_BGR2RGB))
结论
通过本文,我们了解了姿势估计的概念,为什么对姿态估计的需求猛增?姿态估计的应用是什么?我们已经使用姿势估计的地方等内容。
我们将看到有多少种姿态估计,例如人体姿态估计、刚性姿态估计、2D 姿态估计、3D 姿态估计、头部姿态估计、手姿态估计,我们如何在使用这些类型的姿态估计的同时使用一些用于 2D 和 3D 姿态估计的流行算法。
最后,我们了解了如何使用 Openpose 估计对人体全身图像进行姿态估计。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

