
Deepsort + Yolo 实现行人检测和轨迹追踪

极市导读
本项目通过采用深度学习方法实现YOLO算法行人检测和deepsort算法对人员定位的和轨迹跟踪。>>加入极市CV技术交流群,走在计算机视觉的最前沿
引言
行人检测是近年来计算机视觉领域的研究热点,同时也是目标检测领域中的难点。其目的是识别和定位图像中存在的行人,在许多领域中都有广泛的应用。交通安全方面,无人驾驶汽车通过提前检测到行人及时避让来避免交通事故的发生;安防保护方面,通过行人检测来防止可疑人员进入;公共场所管理方面,通过行人检测统计人流量数据,优化人力物力等资源的分配。
对于目标检测的方法,从2013年Ross Girshick提出R-CNN开始,人们在短短几年内相继提出Fast R-CNN、Faster R-CNN、Mask R-CNN、SSD、YOLO等算法,其中两步检测的目标检测方法(R-CNN系列算法)需要先产生大量候选框之后再用卷积神经网络对候选框进行分类和回归处理;单步检测的方法(SSD、YOLO系列算法)则直接在卷积神经网络中使用回归的方法一步就预测出目标的位置以及目标的类别。虽然两步检测的目标检测方法在大多数的场景下精确率更高,但是它需要分两个步骤进行,因此,这种方法将耗费大量的时间成本和昂贵的硬件成本,不适合对视频文件进行实时的检测。而YOLO系列的网络速度更快,可以适应实时视频的检测,泛化能力更强。
对于人员跟踪,2016年Alex Bewley提出了简单在线实时跟踪算法,这种算法把传统的卡尔曼滤波和匈牙利算法结合到一起, 能在视频帧序列中很好地进行跨检测结果的关联, 而且它的速度比传统的算法快20倍左右,可以快速地对目标检测反馈的数据进行处理。
故本项目通过采用深度学习方法实现YOLO算法行人检测和deepsort算法对人员定位的和轨迹跟踪。其最终实现效果如下图可见:

基本介绍
1.1 环境要求
本次环境使用的是python3.6.5+windows平台。主要用的库有:
opencv模块。在计算机视觉项目的开发中,opencv作为较大众的开源库,拥有了丰富的常用图像处理函数库,采用C/C++语言编写,可以运行在Linux/Windows/Mac等操作系统上,能够快速的实现一些图像处理和识别的任务。
pillow模块。PIL是理想的图像存档和批处理应用程序。您可以使用库创建缩略图,在文件格式、打印图像等之间进行转换。它提供了广泛的文件格式支持、高效的内部表示和相当强大的图像处理功能。核心图像库是为快速访问以几种基本像素格式存储的数据而设计的。为通用图像处理工具提供了坚实的基础。
Scipy库。Scipy是一个用于数学、科学、工程领域的常用软件包,可以处理插值、积分、优化、图像处理、常微分方程数值解的求解、信号处理等问题。它用于有效计算Numpy矩阵,使Numpy和Scipy协同工作,高效解决问题。
keras模块。Keras是一个由Python编写的开源人工神经网络库,可以作为Tensorflow、Microsoft-CNTK和Theano的高阶应用程序接口,进行深度学习模型的设计、调试、评估、应用和可视化。
1.2 算法设计
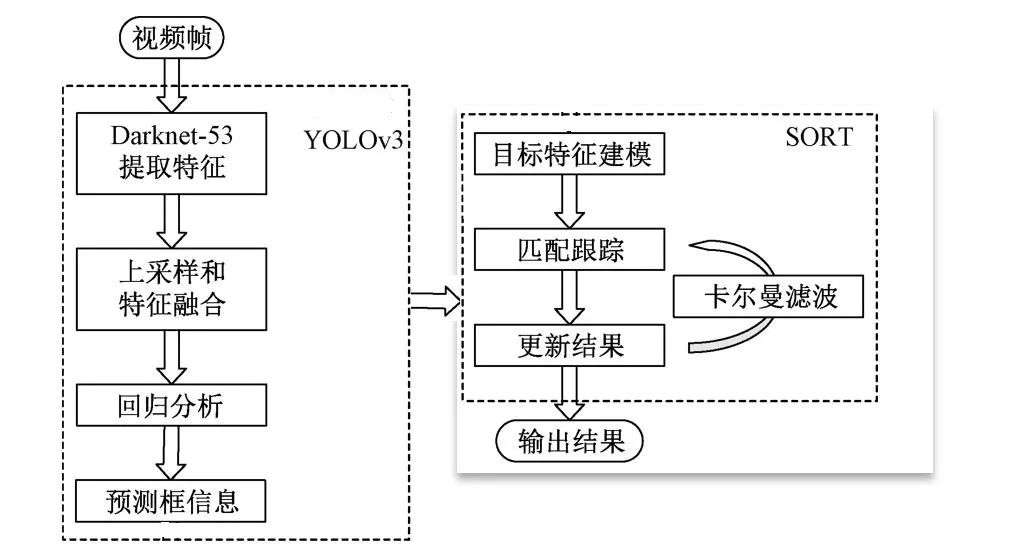
使用卷积神经网络对视频中的行人进行检测和跟踪。视频帧输入之后首先进入YOLOv3目标检测的网络,经过Darknet-53提取特征;其次,进行上采样和特征融合,再进行回归分析;再次,把得出的预测框信息输入SORT算法进行目标特征建模,匹配和跟踪;最后,输出结果。下图为算法流程设计图:
行人检测
2.1 YOLO行人检测
常见的两阶段检测首先是使用候选区域生成器生成的候选区集合,并从每个候选区中提取特征,然后使用区域分类器预测候选区域的类别。而YOLO作为单阶段检测器,则不用生成候选区域,直接对特征图的每个位置上的对象进行分类预测,效率更高。
在这里使用labelme标注行人数据集,然后通过搭建好的YOLO算法产生模型并进行训练即可。
def yolo_body(inputs, num_anchors, num_classes):
"""Create YOLO_V3 model CNN body in Keras."""
darknet = Model(inputs, darknet_body(inputs))
x, y1 = make_last_layers(darknet.output, 512, num_anchors*(num_classes+5))
x = compose(
DarknetConv2D_BN_Leaky(256, (1,1)),
UpSampling2D(2))(x)
x = Concatenate()([x,darknet.layers[152].output])
x, y2 = make_last_layers(x, 256, num_anchors*(num_classes+5))
x = compose(
DarknetConv2D_BN_Leaky(128, (1,1)),
UpSampling2D(2))(x)
x = Concatenate()([x,darknet.layers[92].output])
x, y3 = make_last_layers(x, 128, num_anchors*(num_classes+5))
return Model(inputs, [y1,y2,y3])

2.2 Deepsort行人跟踪
行人多目标跟踪算法设计的步骤如下:
(1) 检测阶段:目标检测算法会分析每一个输入帧,并识别属于特定类别的对象,给出分类和坐标。
(2) 特征提取/运动轨迹预测阶段:采用一种或者多种特征提取算法用来提取表观特征,运动或者交互特征。此外,还可以使用轨迹预测器预测该目标的下一个位置。
(3) 相似度计算阶段:表观特征和运动特征可以用来计算两个目标之间的相似性。
(4) 关联阶段:使用计算得到的相似性作为依据,将属于同一目标的检测对象和轨迹关联起来,并给检测对象分配和轨迹相同的 ID。
使用卡尔曼滤波类跟踪的估计状态系统和估计的方差或不确定性。用于预测。
这里dist_thresh为距离阈值。当超过阈值时,轨道将被删除,并创建新的轨道;Max_frames_to_skip为允许跳过的最大帧数对于跟踪对象未被检测到;max_trace_length为跟踪路径历史长度;trackIdCount为每个轨道对象的标识。
def Update\(self, detections\):
if \(len\(self.tracks\) == 0\):
for i in range\(len\(detections\)\):
track = Track\(detections\[i\], self.trackIdCount\)
self.trackIdCount += 1
self.tracks.append\(track\)
N = len\(self.tracks\)
M = len\(detections\)
cost = np.zeros\(shape=\(N, M\)\)
for i in range\(len\(self.tracks\)\):
for j in range\(len\(detections\)\):
try:
diff = self.tracks\[i\].prediction - detections\[j\]
distance = np.sqrt\(diff\[0\]\[0\]\*diff\[0\]\[0\] +
diff\[1\]\[0\]\*diff\[1\]\[0\]\)
cost\[i\]\[j\] = distance
except:
pass
cost = \(0.5\) \* cost
assignment = \[\]
for \_ in range\(N\):
assignment.append\(-1\)
row\_ind, col\_ind = linear\_sum\_assignment\(cost\)
for i in range\(len\(row\_ind\)\):
assignment\[row\_ind\[i\]\] = col\_ind\[i\]
un\_assigned\_tracks = \[\]
for i in range\(len\(assignment\)\):
if \(assignment\[i\] \!= -1\):
if \(cost\[i\]\[assignment\[i\]\] > self.dist\_thresh\):
assignment\[i\] = -1
un\_assigned\_tracks.append\(i\)
pass
else:
self.tracks\[i\].skipped\_frames += 1
del\_tracks = \[\]

综合结果显示
将YOLO行人检测和deepsort算法结合,并通过设置基本阈值参数控制轨迹预测的欧式距离。通过搭建本项目可应用于城市商业街道、人行道、校园道路场景,使用其得出的人员流动数据,帮助公共交通和安全管理。最终得到的使用效果如下:
track\_colors = get\_colors\_for\_classes\(max\_colors\)
result = np.asarray\(image\)
font = cv2.FONT\_HERSHEY\_SIMPLEX
result0 = result.copy\(\)
result1=result.copy\(\)
img\_position=np.zeros\(\[result.shape\[0\],result.shape\[1\],3\]\)
if \(len\(centers\) > 0\):
tracker.Update\(centers\)
for i in range\(len\(tracker.tracks\)\):
if \(len\(tracker.tracks\[i\].trace\) > 1\):
x0, y0 = tracker.tracks\[i\].trace\[\-1\]\[0\]\[0\], tracker.tracks\[i\].trace\[\-1\]\[1\]\[0\]
cv2.putText\(result0, "ID: "+str\(tracker.tracks\[i\].track\_id-99\), \(int\(x0\), int\(y0\)\), font, track\_id\_size,
\(255, 255, 255\), 2\)
cv2.putText\(result1, "ID: " + str\(tracker.tracks\[i\].track\_id - 99\), \(int\(x0\), int\(y0\)\), font,
track\_id\_size,
\(255, 255, 255\), 2\)
color\_random = tracker.tracks\[i\].track\_id \% 9
cv2.circle\(img\_position, \(int\(x0\), int\(y0\)\), 1, track\_colors\[color\_random\], 8\)
cv2.putText\(img\_position, str\(tracker.tracks\[i\].track\_id - 99\), \(int\(x0\), int\(y0\)\), font,
track\_id\_size,
\(255, 255, 255\), 2\)
result0=result0.copy\(\)
for j in range\(len\(tracker.tracks\[i\].trace\) - 1\):
x1 = tracker.tracks\[i\].trace\[j\]\[0\]\[0\]
y1 = tracker.tracks\[i\].trace\[j\]\[1\]\[0\]
x2 = tracker.tracks\[i\].trace\[j + 1\]\[0\]\[0\]
y2 = tracker.tracks\[i\].trace\[j + 1\]\[1\]\[0\]
clr = tracker.tracks\[i\].track\_id \% 9
distance = \(\(x2 - x1\) \*\* 2 + \(y2 - y1\) \*\* 2\) \*\* 0.5
if distance \< max\_point\_distance:
cv2.line\(result1, \(int\(x1\), int\(y1\)\), \(int\(x2\), int\(y2\)\),
track\_colors\[clr\], 4\)
result1\=result1.copy\(\)

完整代码:
https://pan.baidu.com/s/1KHEbPwCrjsS_3wBdUrtdtQ提取码:pe5m
作者简介:
李秋键,CSDN博客专家,CSDN达人课作者。硕士在读于中国矿业大学,开发有taptap竞赛获奖等。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
