
DeepMind 爆出无监督表示学习模型 BigBiGAN,GAN 之父点赞!
【新智元导读】今天,DeepMind爆出一篇重磅论文,引发学术圈热烈反响:基于最强图像生成器BigGAN,打造了BigBiGAN,在无监督表示学习和图像生成方面均实现了最先进的性能!Ian Goodfellow也称赞“太酷了!”
GAN在图像合成方面一次次让人们惊叹不已!
例如,被称为史上最强图像生成器的BigGAN——许多人看到BigGAN生成的图像都要感叹“太逼真了!DeepMind太秀了吧!”

BigGAN生成的逼真图像
这不是最秀的。今天,DeepMind的一篇新论文再次引发学术圈热烈反响,论文题为《大规模对抗性表示学习》。

论文链接:
https://arxiv.org/pdf/1907.02544.pdf
在这篇论文中,DeepMind基于最先进的BigGAN模型构建了BigBiGAN模型,通过添加编码器和修改鉴别器将其扩展到表示学习。
BigBiGAN表明,“图像生成质量的进步转化为了表示学习性能的显著提高”。
研究人员广泛评估了BigBiGAN模型的表示学习和生成性能,证明这些基于生成的模型在ImageNet上的无监督表示学习和无条件图像生成方面都达到了state of the art的水平。
这篇论文在Twitter上引发很大反响。GAN发明人Ian Goodfellow说:“很有趣,又回到了表示学习。我读PhD期间,我和大多数合作者都对作为样本生成的副产品的表示学习很感兴趣,而不是样本生成本身。”

Goodfellow说:“当年我们在写最初的GAN论文时,我的合著者@dwf(David Warde-Farley)试图得到一些类似于BiGAN的东西,用于表示学习。5年后看到这一成果,我觉得太酷了。”
Andrej Karpathy 也说:“无监督/自监督学习是一个非常丰富的领域,它将消除目前对大规模数据集的必要性.”

总结而言,这篇论文展示了GAN可以用于无监督表示学习,并在ImageNet上获得了最先进的结果。
下面是BigBiGAN生成的一些重建样本,可以看到,重建是倾向于强调高级语义,而不是像素级的细节。

下面,新智元带来对这篇论文的详细解读。
基于BigGAN打造BigBiGAN:学习高级语义,而非细节
近年来,我们已经看到视觉数据生成模型的快速发展。虽然这些模型以前局限于模式单一或少模式、结构简单、分辨率低的领域,但随着建模和硬件的进步,它们已经获得了令人信服地生成复杂、多模态、高分辨率图像分布的能力。
直观地说,在特定域中生成数据的能力需要高度理解所述域的语义。这一想法长期以来颇具吸引力,因为原始数据既便宜——可以从互联网等来源获得几乎无限的供应——又丰富,图像包含的信息远远超过典型的机器学习模型训练用来预测的类别标签。
然而,尽管生成模型取得的进展不可否认,但仍然存在一些令人困扰的问题:这些模型学到了什么语义,以及如何利用它们进行表示学习?
仅凭原始数据就能真正理解生成这个梦想几乎不可能实现。相反,最成功的无监督学习方法利用了监督学习领域的技术,这是一种被称为自监督学习(self-supervised learnin)的方法。
这些方法通常涉及以某种方式更改或保留数据的某些方面,并训练模型来预测或生成缺失信息的某些方面。
例如,Richard Zhang等人的研究(CVPR 2016)提出了一种非监督学习的图像着色方法,在这种方法中,模型被给予输入图像中颜色通道的子集,并经过训练来预测缺失的通道。
作为无监督学习手段的生成模型为self-supervised的任务提供了一个很有吸引力的替代方案,因为它们经过训练,可以对整个数据分布建模,而不需要修改原始数据。
GAN是一类应用于表示学习的生成模型。GAN框架中的生成器是一个从随机采样的潜在变量(也称为“噪声”)到生成数据的前馈映射,其中学习信号由经过训练的鉴别器提供,用来区分真实数据和生成的数据样本,引导生成器的输出跟随数据分布。
作为GAN框架的扩展,Vincent Dumoulin等人(ICLR 2017)提出adversarially learned inference(ALI)[7],或Jeff Donahue等人(ICLR 2017)提出 bidirectional GAN (BiGAN)[4]方法,这些方法通过编码器模块将实际数据映射到潜在数据(与生成器学习的映射相反)来增强标准GAN。
在最优判别器的极限下,[4]论文表明确定性BiGAN的行为类似于自编码器,最大限度地降低了重建成本l₀;然而,重建误差曲面的形状是由参数鉴别器决定的,而不是像误差l₂这样的简单像素级度量。
由于鉴别器通常是一个功能强大的神经网络,我们希望它能产生一个误差曲面,在重建时强调“语义”误差,而不是强调低层次的细节。

BigBiGAN重建的更多图像
论文证明了通过BiGAN或ALI框架学习的编码器是在ImageNet上学习下游任务的一种有效的视觉表示方法。然而,它使用了DCGAN风格的生成器,无法在这个数据集上生成高质量的图像,因此编码器能够建模的语义也相当有限。
在这项工作中,我们再次使用BigGAN作为生成器,这是一个能够捕获ImageNet图像中的许多模式和结构的先进模型。我们的贡献如下:
我们证明了BigBiGAN (BiGAN with BigGAN generator)与ImageNet上无监督表示学习的最先进技术相匹敌。
我们为BigBiGAN提出了一个更稳定的联合鉴别器。
我们对模型设计选择进行了全面的实证分析和消融研究。
我们证明,表示学习目标还有助于无条件生成图像,并展示了无条件生成ImageNet的最先进结果。
BigBiGAN框架的结构
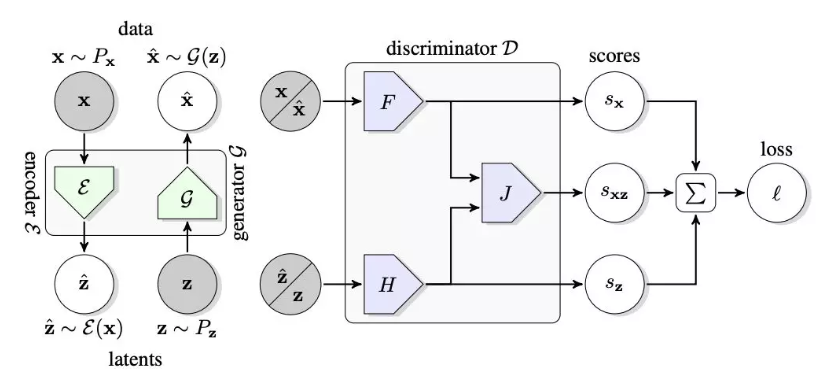
BigBiGAN框架的结构
BigBiGAN框架的结构如上图所示。

评估和结果:表示学习、图像生成实现最优性能
表示学习
我们现在从上述简化学习结果中获取基于train-val分类精度的最优模型,在官方ImageNet验证集上得出结果,并与最近的无监督学习研究文献中的现有技术水平进行比较。
为了进行这些比较,我们还提供了基于规模较小的ResNet-50的最佳性能GAN变种的分类结果。详细比较结果在表2中给出。
与当前许多自监督学习方法相比,本文中采用的纯基于生成模型的BigBiGAN方法在表示学习方面表现良好,在最近的无监督学习任务上的表现达到了SOTA 水平,最近公布的结果显示,本文中的方法在使用表2的AvePool相同的表示学习架构和特征的旋转预测预训练任务中,将top-1精度由55.4%提高到60.8%。
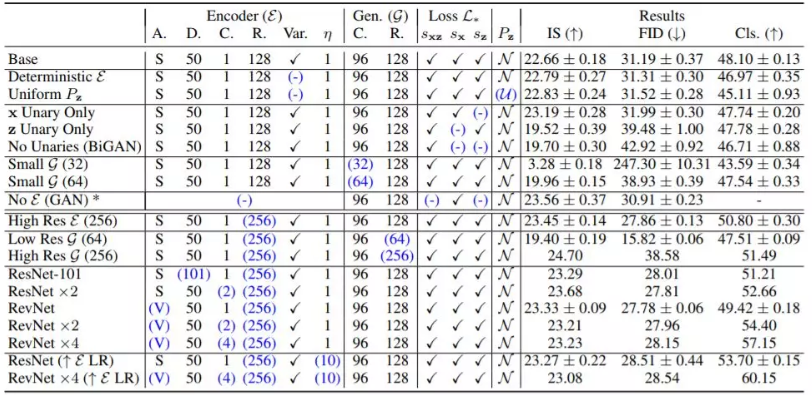
表1:多个BigBiGAN变体的性能结果,在生成图像的初始分数(IS)和Fréchet初始距离(FID),监督式逻辑回归分类器ImageNet top-1精度百分比(Cls。)由编码器特征训练,并基于从训练集中随机抽样的10K图像进行分割计算,我们将其称为“train-val”分割。
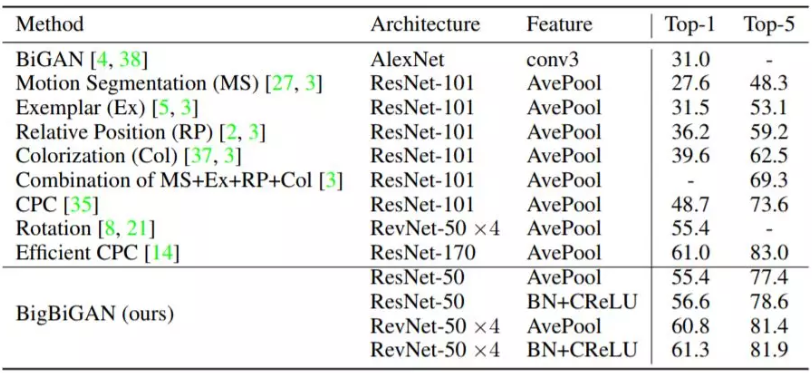
表2:在官方ImageNet验证集上对BigBiGAN模型与最近的基于监督式逻辑回归分类器的其他方法的对比。

表3:我们的BigBiGAN与无监督(无条件)生成方法、以及之前报告的无监督BigGAN的性能结果对比。
无监督式图像生成
表3所示为BigBiGAN进行无监督生成的结果,与基于BigGAN的无监督生成结果做比较。请注意,这些结果与表1中的结果不同,因为使用的是数据增强方法(而非表1中的用于所有结果的ResNet样式预处理方法)。
这些结果表明,BigBiGAN显著提升了以IS和FID为量度的基线无条件BigGAN生成结果的性能。

图2:从无监督的BigBiGAN模型中选择的图像重建结果。上面一行的图像是真实图像(x~Px),下面一行图像是由G(E(x))计算出的这些图像的重建结果。与大多数显式重建成本(例如像素数量)不同,由(Big)BiGAN 实现隐式最小化的重建成本更多倾向于强调图像的语义及其他更高级的细节。
图像重建:更偏重高级语义,而非像素细节
图2中所示的图像重建在像素上远达不到完美,可能部分原因是目标没有明确强制执行重建成本,在训练时甚至对重建模型进行计算。然而,它们可以为编码器 ε 学习建模的特征提供一些帮助。
比如,当输入图像中包含狗、人或食物时,重建结果通常是姿势、位置和纹理等相同特征“类别”的不同实例。例如,脸朝同一方向的另一只类似的狗。重建结果倾向于保留输入的高级语义,而不是低级细节,这表明BigBiGAN的训练在鼓励编码器对前者进行建模,而不是后者。