
干货|全面理解无监督学习基础知识
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
无监督学习的特点是,模型学习的数据没有标签,因此无监督学习的目标是通过对这些无标签样本的学习来揭示数据的内在特性及规律,其代表就是聚类。与监督学习相比,监督学习是按照给定的标准进行学习(这里的标准指标签),而无监督学习则是按照数据的相对标准进行学习(数据之间存在差异)。以分类为例,小时候你在区分猫和狗的时候,别人和你说,这是猫,那是狗,最终你遇到猫或狗你都能区别出来(而且知道它是猫还是狗),这是监督学习的结果。但如果小时候没人教你区别猫和狗,不过你发现猫和狗之间存在差异,应该是两种动物(虽然能区分但不知道猫和狗的概念),这是无监督学习的结果。
聚类正是做这样的事,按照数据的特点,将数据划分成多个没有交集的子集(每个子集被称为簇)。通过这样的划分,簇可能对应一些潜在的概念,但这些概念就需要人为的去总结和定义了。
聚类可以用来寻找数据的潜在的特点,还可以用来其他学习任务的前驱。例如在一些商业引用中需要对新用户的类型进行判别,但是“用户类型”不好去定义,因此可以通过对用户进行聚类,根据聚类结果将每个簇定义为一个类,然后基于这些类训练模型,用于判别新用户的类型。
聚类有着自己的性能度量,这和监督学习的损失函数类似,如果没有性能度量,则不能判断聚类结果的好坏了。
聚类的性能大致有两类:一类是聚类结果与某个参考模型进行比较,称为外部指标;另一种则是直接考察聚类结果而不参考其他模型,称为内部指标。
在介绍外部指标之前先作以下定义。对于样本集合,我们可以给每一个样本一个单独的编号,并且我们以表示编号为i j 的样本属于同一个簇,这里 i<j 可以避免重复。因此有
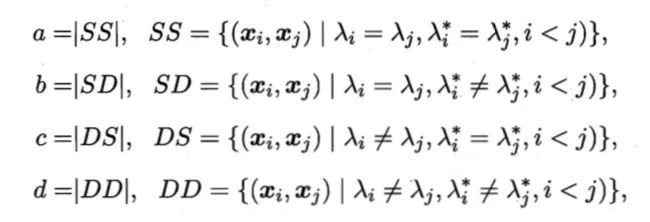
a表示在聚类结果中样本i j 属于同一个簇,而在参考模型中i j 也同属于一个簇。b表示在聚类结果中样本i j 属于同一个簇,而在参考模型中i j 不同属于一个簇。c和d同理。以上定义两两样本在聚类结果和参考模型结果可能出现的情况。
常用的外部指标如下


以上的性能度量的结果都在[0,1]区间中,并且结果越大,说明性能越好。
倘若没有可参考的模型,一个好的聚类结果应是类内的点都足够近,类间的点都足够远,这就是内部指标说要描述的。对于内部指标我们需要先做以下定义
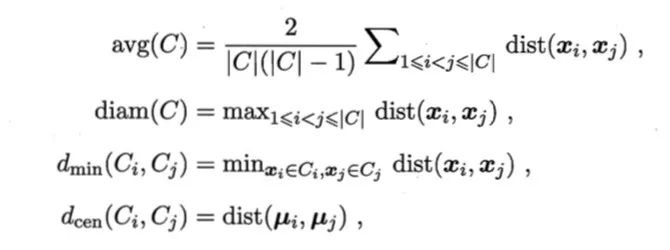

常用的内部指标有

DBI值越小说明聚类效果好,DI则相反,DI值越大说明聚类效果越好。
样本点分布空间中,如果两个样本点相距很近,则认为样本点应该属于同一个簇。如果样本相距很远,则不会认为它们属于同一个簇。当然这里的远近是一种相对的概念而不是单纯的数值。我们可以使用VDM(Value Difference Metric)距离:
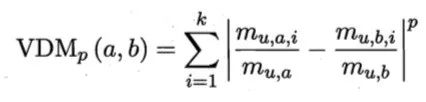
以上表示了属性u上两个离散值a与b之间的VDM距离。表示属性u上取值为a的样本数
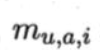 表示在第i个样本簇中属性u上取值为a的样本数,k为样本簇数。
表示在第i个样本簇中属性u上取值为a的样本数,k为样本簇数。
距离度量在聚类中非常重要,因为距离度量描述的是不同类别的相似度,距离越大相似度越小,由于不同概念之相似度的度量有所不同,在现实任务中,需要通过样本确定合适的距离计算公式,这可以通过距离度量学习实现。
k-means
k均值是常用的快速聚类方法,该方法在学习开始之初,随机设置若干个簇心,样本点隶属于离它最近的簇心。因此每个簇心会有一个隶属于它自己的样本集合。每次迭代,每个簇心找到隶属于自己的样本集合,并根据其隶属的样本集合中计算出中心位置(均值),然后簇心移动到此处。直到聚类结果不发生改变。k-means对球状簇比较高效,针对其他的效果较差。
关于聚类簇心的设置,现实中我们往往会设置不同数量的簇心,通过聚类的性能度量来选择最佳的簇心个数。
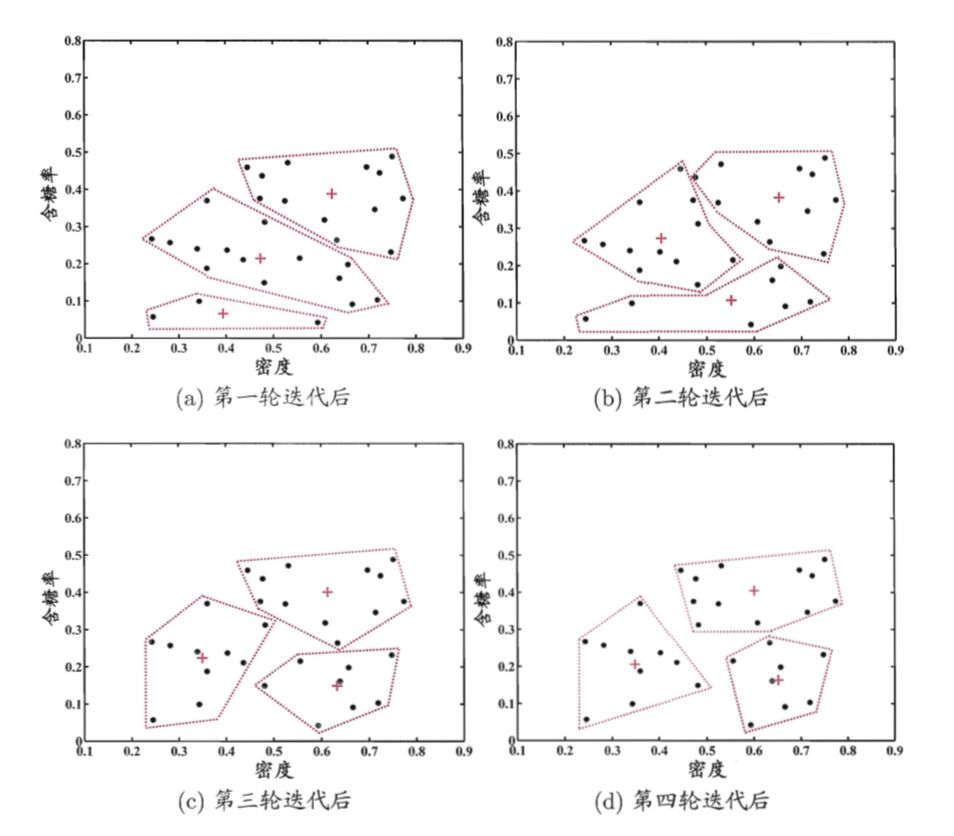
以上是西瓜数据集的聚类过程。
学习向量量化(Learin Vector Quantization)
LVQ和K均值算法很像,同样是通过移动簇心来实现聚类,不同的是LVQ假设数据样本有类别标记,通过这些监督信息辅助聚类。算法过程如下

以上算法的过程可以简单概括为,如果随机选择的点与簇心的类别不对应则令簇心远离该样本点,否则靠近该样本点。迭代结束后对于任意样本x,它将被划入与其距离最近的原型向量所代表的簇中。
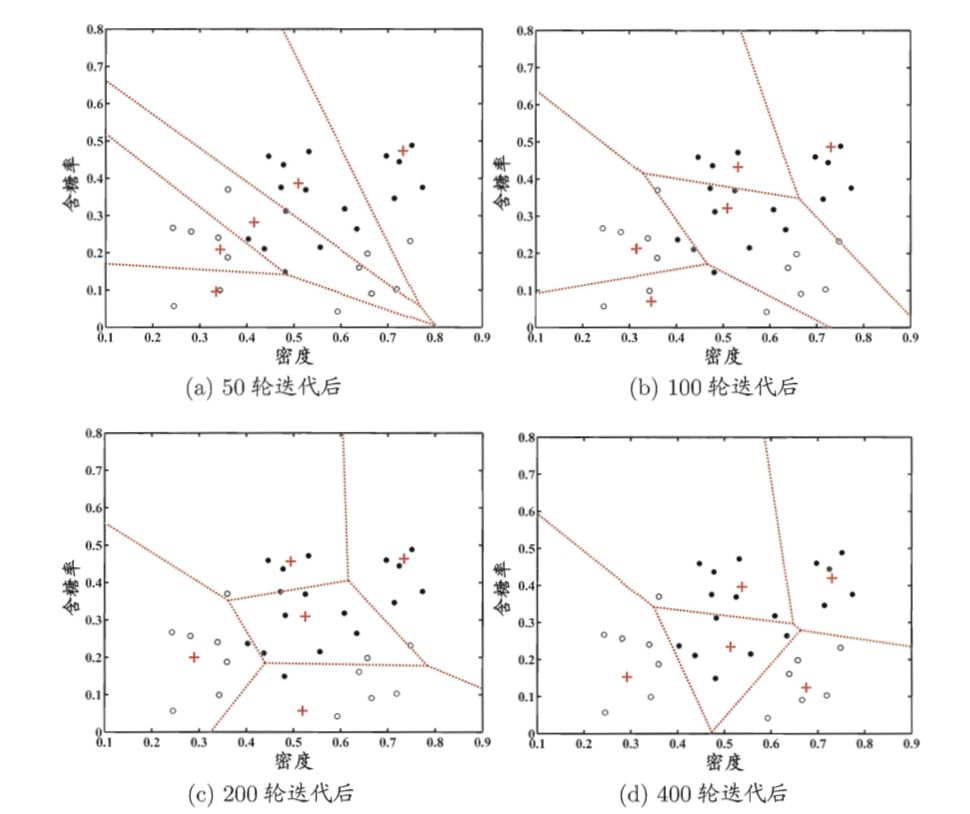
以上是LVQ在西瓜数据集聚类的过程。
高斯混合聚类
高斯混合聚类才用概率模型来表达聚类原型,我们可以定义高斯混合分布为
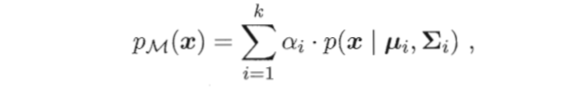
其中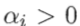 为混合系数且
为混合系数且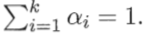 。使用高斯混合聚类其实是假设样本是在高斯混合分布中采样的结果。对于样本我们可以通过计算
。使用高斯混合聚类其实是假设样本是在高斯混合分布中采样的结果。对于样本我们可以通过计算
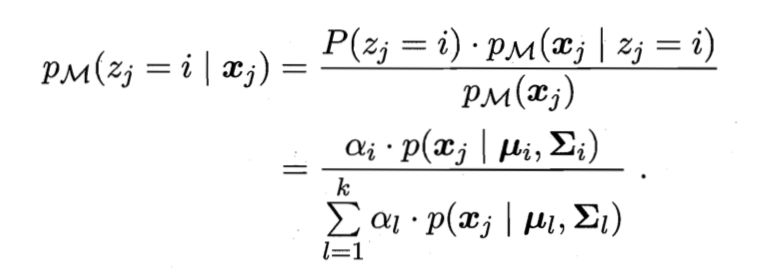
得出某样本由第i个高斯分布生成的后验概率,该样本的类别为使得该概率最大的分布的类别。有关于高斯混合模型的具体介绍,将会与EM算法一起介绍。
密度聚类
顾名思义,密度聚类从样本密度的角度来考察样本之间的关联性,其经典算法为DBSCAN,该算法通过设置的邻域和样本邻域内最少样本点数为标准设置核心对象,倘若核心对象密度相连则将它们合并到同一簇,因此DBSCAN的聚类结果的一个簇为最大的密度相连的样本集合。以下是DBSCAN的一些概念的定义:


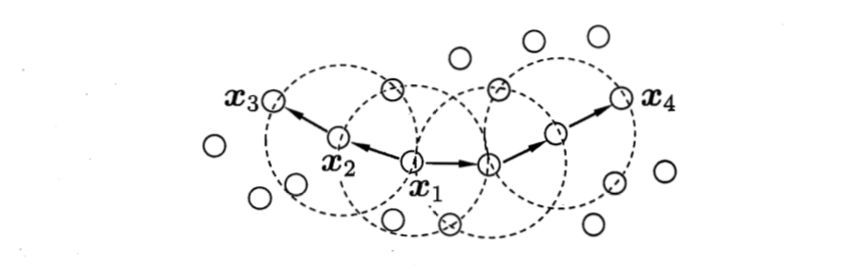
上面MinPts = 3,虚线表示核心对象的邻域。X1与X2密度直达,X1与X3密度可达X3与X4密度相连。
DBSCAN能够将足够高密度的区域划分成簇,并能在具有噪声的空间数据库中发现任意形状的簇。
层次聚类
层次聚类开始时把所有的样本归为一类,然后计算出各个类之间的距离,然后合并距离最小的两个类。从上面的描述来看,层次聚类就像是在用克鲁斯卡尔算法建立最小生成树一样,不过当层次聚类当前类别数下降到给定的类别数是就会终止。这里层次聚类所使用的聚类是不同类别之间的平均距离。
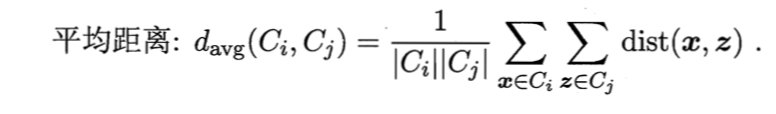
因为层次聚类所需要计算的距离很多,因此层次聚类并不适合在大的数据集中的使用。
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~