
手把手教你实现GAN半监督学习
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文主要介绍如何在tensorflow上仅使用200个带标签的mnist图像,实现在一万张测试图片上99%的测试精度,原理在于使用GAN做半监督学习。前文主要介绍一些原理部分,后文详细介绍代码及其实现原理。前文介绍比较简单,有基础的同学请掠过直接看第二部分,文章末尾给出了代码GitHub链接。对GAN不了解的同学可以查看微信公众号:机器学习算法全栈工程师的GAN入门文章。
在正式介绍实现半监督学习之前,我在这里首先介绍一下监督学习(supervised learning),半监督学习(semi-supervised learning)和无监督学习(unsupervised learning)的区别。监督学习是指在训练集中包含训练数据的标签(label),比如类别标签,位置标签等等。最普遍使用标签学习的是分类任务,对于分类任务,输入给网络训练样本(samples)的一些特征(feature)以及此样本对应的标签(label),通过神经网络拟合的方法,神经网络可以在特征和标签之间找到一个合适的映射关系(mapping),这样当训练完成后,输入给网络没有label的样本,神经网络可以通过这一个映射关系猜出它属于哪一类。典型机器学习的监督学习的例子是KNN和SVM。目前机器视觉领域的急速发展离不开监督学习。
而无监督学习的训练事先没有训练标签,直接输入给算法一些数据,算法会努力学习数据的共同点,寻找样本之间的规律性。无监督学习是很典型的学习,人的学习有时候就是基于无监督的,比如我并不懂音乐,但是我听了上百首歌曲后,我可以根据我听的结果将音乐分为摇滚乐(记为0类)、民谣(记为1类)、纯音乐(记为2类)等等,事实上,我并不知道具体是哪一类,所以将它们记为0,1,2三类。典型的无监督学习方法是聚类算法,比如k-means。
东方快车电影里面大侦探有过一个台词,人们的话只有对与错,没有中间地带,最后经过一系列事件后他找到了对与错之间的betweeness。在监督学习和无监督学习之间,同样存在着中间地带-半监督学习。半监督学习简单来说就是将无监督学习和监督学习相结合,一部分包含了监督学习一部分包含了无监督学习,比如给一个分类任务,此分类任务的训练集中有精确标签的数据非常少,但是包含了大量的没有标注的数据,如果直接用监督学习的方法去做的话,效果不一定很好,有标注的训练数据太少很容易导致过拟合,而且大量的无标注的数据都没有充分的利用,最常见的例子是在医学图像的分析检测任务中,医学图像本身就不容易获得,要获得精标注的图像就需要有经验的医生去一个一个标注,显然他们并没有那么多的时间。这时候就是半监督学习的用武之地了,半监督学习很适合用在标签数据少,训练数据又比较多的情况。
常见的半监督学习方法主要有:
1.Self training
2.Generative model
3.S3VMs
4.Graph-Based AIgorithems
5.Multiview AIgorithems
接下来我会结合Improved Techniques for Training GANs这篇论文详细介绍如何使用目前最火的生成模型GAN去实现半监督学习,也即是半监督学习的第二种方法,并给出详细的代码解释,对理论不是很熟悉的同学可以直接看代码。另外注明:我只复现了论文半监督学习的部分,之前也有人复现了此部分,但是我感觉他对原文有很大的曲解,他使用了所有的标签去帮助生成,并不在分类上,不太符合半监督学习的本质,而且代码很复杂,感兴趣的可以看这个链接https://github.com/gitlimlab/SSGAN-Tensorflow。
GAN是无监督学习的代表,它可以不断学习模拟数据的分布进而生成和训练数据相似分布的样本,在训练过程不需要标签,GAN在无监督学习领域,生成领域,半监督学习领域以及强化学习领域都有广泛的应用。但是GAN存在很多的训练不稳定等等的问题,作者good fellow在2016年放出了Improved Techniques for Training GANs,对GAN训练不稳定的问题做了一些解释和经验上的解决方案,并给出了和半监督学习结合的方法。
从平衡点角度解释GAN的不稳定性来说,GAN的纳什均衡点是一个鞍点,并不是一个局部最小值点,基于梯度的方法主要是寻找高维空间中的极小值点,因此使用梯度训练的方法很难使GAN收敛到平衡点。为此,为了一部分缓解这个问题,goodfellow联合提出了一些改进方案,
主要有:
Feature matching,
Minibatch discrimination
weight Historical averaging (相当于一个正则化的方式)
One-sided label smoothing
Virtual batch normalization
后来发现Feature matching在半监督学习上表现良好,mini-batch discrimination表现很差。
对于一个普通的分类器来说,假设对MNIST分类,一共有10类数据,分别是0-9,分类器模型以数据x作为输入,输出一个K=10维的向量,经过soft max后计算出分类概率最大的那个类别。在监督学习领域,往往是通过最小化类别标签 y 和预测分布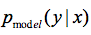 的交叉熵来实现最好的结果。
的交叉熵来实现最好的结果。
但是将GAN用在半监督学习领域的时候需要做一些改变,生成器不做改变,仍然负责从输入噪声数据中生成图像,判别器D不在是一个简单的真假分类(二分类)器,假设输入数据有K类,D就是K+1的分类器,多出的那一类是判别输入是否是生成器G生成的图像。网络的流程图见图一。
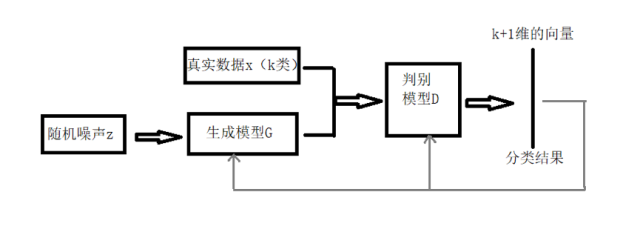
图一 网络的流程图
网络结构确定了之后就是损失函数的设计部分,借助GAN我们就可以从无标签数据中学习,只要知道输入数据是真实数据,那就可以通过最大化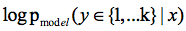 来实现,上述式子可解释为不管输入的是哪一类真的图片(不是生成器G生成的假图片),只要最大化输出它是真图像的概率就可以了,不需要具体分出是哪一类。由于GAN的生成器的参与,训练数据中有一半都是生成的假数据。
来实现,上述式子可解释为不管输入的是哪一类真的图片(不是生成器G生成的假图片),只要最大化输出它是真图像的概率就可以了,不需要具体分出是哪一类。由于GAN的生成器的参与,训练数据中有一半都是生成的假数据。
下面给出判别器D的损失函数设计,D损失函数包括两个部分,一个是监督学习损失,一个是半监督学习损失,具体公式如下:
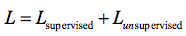
其中
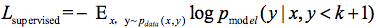
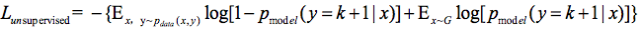
对于无监督学习来说,只需要输出真假就可以了,不需要确定是哪一类,因此我们令
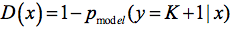
其中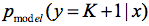 表示判别是假图像的概率,那么D(x)就代表了输出是真图像的概率,那么无监督学习的损失函数就可以表示为
表示判别是假图像的概率,那么D(x)就代表了输出是真图像的概率,那么无监督学习的损失函数就可以表示为
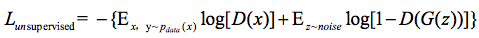
这不就是GAN的损失函数嘛!好了,到这里得出结论,在半监督学习中,判别器的分类要多分一类,多出的这一类表示的是生成器生成的假图像这一类,另外判别器的损失函数不仅包括了监督损失而且还有无监督的损失函数,在训练过程中同时最小化这两者。损失函数介绍完毕,接下来介绍代码实现部分。
注:完整代码的GitHub连接在文章底部。这里只截取关键部分做介绍。
在代码中,我使用feature matching,one side label smoothing方式,并没有使用论文中介绍的Historical averaging,而是只对判别器D使用了简单的l2正则化,防止过拟合,另外论文中介绍的Minibatch discrimination, Virtual batch normalization等等都没有使用,主要是这两者在半监督学习中表现不是很好,但是如果想获得好的生成结果还是很有用的。
1网络结构
首先介绍网络结构部分,因为是在mnist数据集比较简单,所以随便搭了一个判别器和生成器,具体如下:
判别器的网络结构如下面代码所示:
def discriminator(self, name, inputs, reuse):
l = tf.shape(inputs)[0]
inputs = tf.reshape(inputs, (l,self.img_size,self.img_size,self.dim))
with tf.variable_scope(name,reuse=reuse):
out = []
output = conv2d('d_con1',inputs,5, 64, stride=2, padding='SAME') #14*14
output1 = lrelu(self.bn('d_bn1',output))
out.append(output1)
# output1 = tf.contrib.keras.layers.GaussianNoise
output = conv2d('d_con2', output1, 3, 64*2, stride=2, padding='SAME')#7*7
output2 = lrelu(self.bn('d_bn2', output))
out.append(output2)
output = conv2d('d_con3', output2, 3, 64*4, stride=1, padding='VALID')#5*5
output3 = lrelu(self.bn('d_bn3', output))
out.append(output3)
output = conv2d('d_con4', output3, 3, 64*4, stride=2, padding='VALID')#2*2
output4 = lrelu(self.bn('d_bn4', output))
out.append(output4)
output = tf.reshape(output4, [l, 2*2*64*4])# 2*2*64*4
output = fc('d_fc', output, self.num_class)
# output = tf.nn.softmax(output)
return output, out其中conv2d()是卷积操作,参数依次是,层的名字,输入tensor,卷积核大小,输出通道数,步长,padding。判别器中每一层都加了归一化层,这里使用最简单的归一化,函数如下所示,另外每一层的激活函数使用leakrelu。判别器D最终返回两个值,第一个是计算的logits,另外一个是一个列表,列表的每一个元素代表判别器每一层的输出,为接下来实现feature matching做准备。
def bn(self, name, input):
val = tf.contrib.layers.batch_norm(input, decay=0.9,
updates_collections=None,
epsilon=1e-5,
scale=True,
is_training=True,
scope=name)
return val
def lrelu(x, leak=0.2):
return tf.maximum(x, leak * x)生成器结构如下面代码所示:其最后一层激活函数使用tanh
def generator(self,name, noise, reuse):
with tf.variable_scope(name,reuse=reuse):
l = self.batch_size
output = fc('g_dc', noise, 2*2*64)
output = tf.reshape(output, [-1, 2, 2, 64])
output = tf.nn.relu(self.bn('g_bn1',output))
output = deconv2d('g_dcon1',output,5,outshape=[l, 4, 4, 64*4])
output = tf.nn.relu(self.bn('g_bn2',output))
output = deconv2d('g_dcon2', output, 5, outshape=[l, 8, 8, 64 * 2])
output = tf.nn.relu(self.bn('g_bn3', output))
output = deconv2d('g_dcon3', output, 5, outshape=[l, 16, 16,64 * 1])
output = tf.nn.relu(self.bn('g_bn4', output))
output = deconv2d('g_dcon4', output, 5, outshape=[l, 32, 32, self.dim])
output = tf.image.resize_images(output, (28, 28))
# output = tf.nn.relu(self.bn('g_bn4', output))
return tf.nn.tanh(output)网络结构是根据DCGAN的结构改的,所以网络简要介绍到这里。
2网络初始化
接下来介绍网络初始化方面:
首先在train.py里建立一个Train的类,并做一些初始化
class Train(object):
def __init__(self, sess, args):
#sess=tf.Session()
self.sess = sess
self.img_size = 28 # the size of image
self.trainable = True
self.batch_size = 100 # must be even number
self.lr = 0.0002
self.mm = 0.5 # momentum term for adam
self.z_dim = 128 # the dimension of noise z
self.EPOCH = 50 # the number of max epoch
self.LAMBDA = 0.1 # parameter of WGAN-GP
self.model = args.model # 'DCGAN' or 'WGAN'
self.dim = 1 # RGB is different with gray pic
self.num_class = 11
self.load_model = args.load_model
self.build_model() # initializerargs是传进来的参数,主要包括三个,一个是args.model,选择DCGAN模式还是WGAN-GP模式,二者的不同主要在于损失函数不同和优化器的学习率不同,其他都一样。第二个参数是args.trainable,训练还是测试,训练时为True,测试是False。Loadmodel表示是否选择加载训练好的权重。
import argparse
parser.add_argument('--model', type=str, default='DCGAN', help='DCGAN or WGAN-GP')
parser.add_argument('--trainable', type=bool, default=False,help='True for train and False for test')
parser.add_argument('--load_model', type=bool, default=True, help='True for load ckpt model and False for otherwise')
parser.add_argument('--label_num', type=int, default=2, help='the num of labled images we use, 2*100=200,batchsize:100')3Build_model函数
Build_model函数里面主要包括了网络训练前的准备工作,主要包括损失函数的设计和优化器的设计。以下代码连在一起正好是build_model函数的全部内容,下文将详细做出介绍,尤其是损失函数部分。
def build_model(self):
# build placeholders
self.x = tf.placeholder(tf.float32, shape=[self.batch_size, self.img_size*self.img_size*self.dim], name='real_img')
self.z = tf.placeholder(tf.float32, shape=[self.batch_size, self.z_dim], name='noise')
self.label = tf.placeholder(tf.float32, shape=[self.batch_size, self.num_class-1], name='label')
self.flag = tf.placeholder(tf.float32, shape=[], name='flag')
self.flag2 = tf.placeholder(tf.float32, shape=[], name='flag2')
# define the network
self.G_img = self.generator('gen', self.z, reuse=False)
ximg = tf.reshape(self.x, (self.batch_size, self.img_size, self.img_size, self.dim))
d_in = tf.concat([ximg, self.G_img], axis=0)
self.D_logits_, self.D_out_ = self.discriminator('dis', d_in, reuse=False)
self.D_logits, self.D_logits_f = tf.split(self.D_logits_, [self.batch_size, self.batch_size], axis=0)
d_regular = tf.add_n(tf.get_collection('regularizer', 'dis'), 'loss')
#caculate the supervised loss
batch_gl = tf.zeros_like(self.label, dtype=tf.float32)
batchl_ = tf.concat([self.label, tf.zeros([self.batch_size, 1])], axis=1)
batch_gl = tf.concat([batch_gl, tf.ones([self.batch_size, 1])], axis=1)
batchl = tf.concat([batchl_, batch_gl], axis=0)*0.9 # one side label smoothing
s_l = tf.losses.softmax_cross_entropy(onehot_labels=batchl, logits=self.D_logits_, label_smoothing=None)
s_logits_ = tf.nn.softmax(self.D_logits_)
un_s = tf.reduce_sum(s_logits_[:self.batch_size, -1])/(tf.reduce_sum(s_logits_[:self.batch_size,:])) \
+ tf.reduce_sum(s_logits_[self.batch_size:,:-1])/tf.reduce_sum(s_logits_[self.batch_size:,:])
f_match = tf.constant(0., dtype=tf.float32)
for i in range(4):
d_layer, d_glayer = tf.split(self.D_out_[i], [self.batch_size, self.batch_size], axis=0)
f_match += tf.reduce_mean(tf.multiply(tf.subtract(d_layer, d_glayer),tf.subtract(d_layer, d_glayer)))
self.d_loss_real = -tf.log(tf.reduce_sum(s_logits_[:self.batch_size, :-1])/tf.reduce_sum(s_logits_[:self.batch_size, :]))
self.d_loss_fake = -tf.log(tf.reduce_sum(s_logits_[self.batch_size:, -1])/tf.reduce_sum(s_logits_[self.batch_size:, :]))
self.g_loss = self.d_loss_fake + f_match*0.01*self.flag2
self.d_l_1, self.d_l_2, self.d_l_3 = self.d_loss_fake + self.d_loss_real, self.flag*s_l, (1-self.flag)*un_s
self.d_loss = self.d_l_1 + self.d_l_2 + self.d_l_3首先,建立了五个placeholder,flag表示两个标志位,只有0-1两种情况,注意到我num_class是11,也就是做11分类,但是lable的placeholder中shape是(batchsize,10),因为传进去训练之前会将label扩展到[batchsize, 11]。为了方便,我将生成器的生成结果和真实数据X级联在一起作为判别器的输入,输出再把他它们结果split分开。
d_regular 表示正则化,这里我将判别器中所有的weights做了l2正则。
监督学习的损失函数使用常见的交叉熵损失函数,对生成器生成的图像的label的one_hot型为:
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1]
将原始的label扩展到(batchsize,11)后再和生成器生成的假数据的label再第一维度concat到一起得到batchl,另外乘以0.9,做单边标签平滑(one side smoothing),由此计算得到监督学习的损失函数值s_l,。
生成器G的损失函数包括两部分,一个是来自GAN训练的部分,另外一个是feature matching , 论文中提到的feature matching意思是特征匹配,主要思想是希望生成器生成的假数据输入到判别器,经过判别器每一层计算的结果和将真实数据X输入到判别器,判别器每一层的结果尽可能的相似,公式如下:
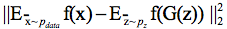
其中f(x)是D的每一层的输出。Feature matching 是指导G进行训练,所以我将他放在了G的损失函数里。
相比较G的损失函数,D的损失函数就比较麻烦了。
接下来介绍无监督学习的损失函数实现:
在前面介绍的无监督学习的损失函数中,有一部分和GAN的损失函数很相似,所以再代码中我们使用了无监督学习的时候没有标签的指导,此时判别器或者称为分类器D无法正确对输入进行分类,此时只要求D能够区分真假就可以了,由此我们得到了无监督学习的损失un_s,直观上也很好理解,假设输入给判别器D真图像,它结果经过soft max后输出类似下面表格的形式
其中前十个黄色区域表示对0-9的分类概率,最后一个灰色的表示对假图像的分类概率,由于无监督学习中判别器D并不知道具体是哪一类数据,所以干脆D的损失函数最小化输出假图像的概率就可以了,当输入为生成器生成的假图像时,只要最小化D输出为真图像的概率,由此我们得到了un_s.。但是此时有一个问题,即是有监督学习的时候不就没有用了吗,因为这时候应该使用s_l.为了解决这个问题,我使用了一个标志位flag作为控制他们之间的使用,具体代码:
flag*s_l + ( 1 – flag)*un_s
有标签的时候flag是1,表示使用s_l,无监督的时候flag是0,表示使用无监督损失函数。此时已经完成了判别器D损失函数的一部分设计,剩下的一部分和GAN中的D的损失一样,在代码中我给出了两种损失函数,一个是原始GAN的交叉熵损失函数,和DCGAN使用的一样,另外一个是improved wgan论文中使用的损失函数,但是在做了对比之后,我强烈建议使用DCGAN来做,improved wgan的损失函数虽然在生成结果的优化上有很大帮助,但是并不适合半监督学习中。
接下来就是训练部分:
此时可能有一个疑问,我们是如何实现只使用200带标签的数据训练的,答案就在flag这个标志位里,在训练部分代码中,当迭代次数小于2的时候,flag=1, 此时表示使用s_l作为损失函数的一部分,当flag=0的时候,un_s起作用而s_l并没有起作用,这时,即使我们feed了正确的标签数据,但是s_l不起作用,就相当于没有使用标签。
for idx in range(iters):
start_t = time.time()
flag = 1 if idxelse 0 # set we use 500 train data with label.flag2的作用本来是使用他控制feature matching是否工作的,这里暂时设置为1。
(训练部分详细代码请移步文章下面github链接查看)
def test(self):
count = 0.
print 'testing................'
for i in range(10000//self.batch_size):
testx, textl = mnist.test.next_batch(self.batch_size)
prediction = self.sess.run(self.prediction, feed_dict={self.x:testx, self.label:textl})
count += np.sum(prediction)
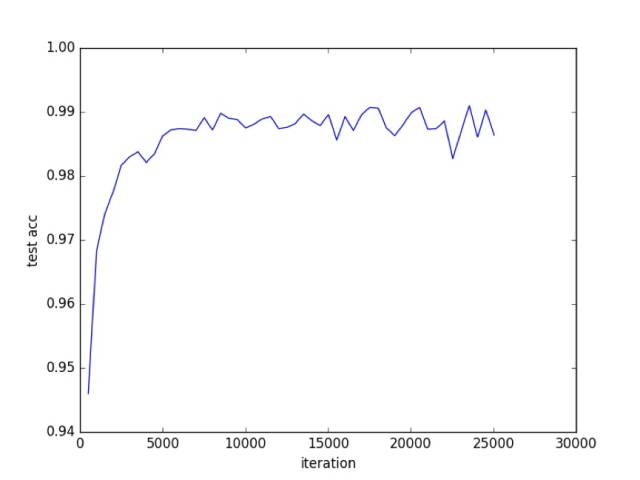
return count/10000.测试部分代码如上图所示,没训练完成一个epoch,就测试依次,测试的时候,使用了一个temp保存测试的最大精度,当测试结果比前几次都要好是,temp会更新到最好的测试精度,并保存模型,否则不保存模型,这样做的好处在于我保存的模型测试精度一定是最好的。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~