
LeCun点赞!GAN模型130毫秒生成动漫肖像!
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
如何把肖像画变成动漫形象一直是一个研究热点,最近NTU的一个华人博士生提出一个新模型AgileGAN,效果碾压老牌模型。把LeCun的肖像画输入进去,竟得到惊天夸赞!
AgileGAN模型是一个能对肖像图进行风格化的模型,论文发表在计算机图形学顶级会议 SIGGRAPH 2021上。

当把Yann LeCun的照片输入到模型中,会发生什么?(Lecun本人会回复你)
LeCun的肖像画输入到AgileGAN中,以三种形式(卡通、漫画、油画)输出,获得了LeCun本人极高的评价:比梵高画的还好!

对于这三张图片,网友表示,最后一张漫画风格图和孙悟空很像!

AgileGAN 模型
肖像画作为一种艺术形式,已经从传统的现实主义描绘演变为其他大量的创作风格。
尽管在肖像自动风格化方面已经取得了实质性进展,但是生成高质量的肖像画仍然是一个挑战,即使是使用最近流行的Toonify,在用于输入真实的图像时也遭受了一些瑕疵的困扰。
这种基于StyleGAN的方法着重于寻找最佳的隐空间映射来重建输入图像。但是,我们发现这并不能很好地作用出不同的肖像风格。
因此,论文提出了AgileGAN,这是一个可以通过隐射一致隐空间的转移学习生成高质量风格肖像的框架。引入了一种新颖的分层变分自编码器,以确保映射隐空间分布符合原始的高斯分布,同时将原始空间扩展为多维度隐空间,以便更好地编码不同级别的细节。
为了更好地捕获面部特征生成,我们还提出了一种属性感知生成器,并采用了一种动态停止策略,以避免过度拟合小型训练数据集。
我们的方法在创建高质量和高分辨率(1024×1024)肖像风格化模型方面提供了更大的敏捷性,只需要有限数量的风格样本(~100)和较短的训练时间(~1小时)。
我们收集了几个用于评估的风格数据集,包括 3D 卡通、漫画、油画和名人。
结果表明,通过定性、定量和通过用户调研研究进行的比较,可以实现优于以前最先进方法的肖像风格化质量。
文中还将演示该方法的两种应用,图像编辑和风格视频生成。

给定单个输入图像,AgileGAN可以快速(130 毫秒)并自动生成各种艺术风格的高质量(1024×1024)风格人像 。对于一种新风格,我们的敏捷训练策略仅需要大约100个训练样本示例,并且可以在1小时内完成训练。
模型的主要流程是一个分层VAE,由一个编码器和生成器组成,带有表示不同训练数据流的不同颜色箭头基于StyleGAN2。蓝色箭头表示图像embedding,橙色箭头表示迁移学习。黑色边框表示块权重,从FFHQ数据集上预先训练的StyleGAN2得到的预训练权重,在训练期间参数保持不变。输入由Erin Wagner(public domain)提供。
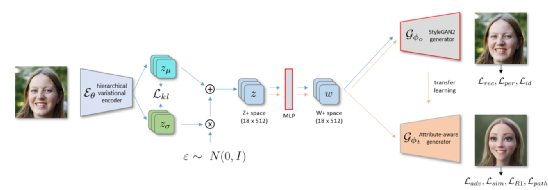
为了生成样式化的肖像,模型使用一个相对风格范例的小集合。主要框架基于StyleGAN2,但增强了多路径结构,以更好地适应与已知属性相对应的不同特征,如性别等。
为了缓解解决数据集的特征问题,更好地保留用户身份,训练过程采用了迁移学习和早期停止策略来训练生成器。
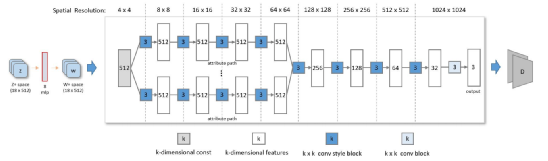
属性感知(attribute-aware)生成器网络的体系结构。每个潜在编码𝑧, 从标准高斯分布采样,首先映射到中间编码𝑤. 每个𝑤 向前转换为样式块中的仿射变换,并通过自适应实例控制生成归一化(AdaIN)。
解码时,首先初始化一个常量特征映射。在较低的层中使用多个路径属性特异性,而共享高层统一纹理外观。使用多属性特定鉴别器来评估生成的图像的质量图像。包括鉴别器的网络权值从StyleGAN2初始化。

给定一个输入的人脸图像𝑥, 它首先被扭曲并标准化为256×256,并由hVAE编码得到隐高斯后验分布𝑞(𝑧|𝑥), 从这以后重要度分布只与hVAE训练相关。
在推断过程中通常不从这个分布中取样,而是直接用分布均值作为latent code 𝑧, 可以更好地保持时间一致性。
这个编码𝑧 然后通过到所选的样式化生成器以生成1024×1024样式化的形象。
在极少数情况下,可能存在高频伪影生成。在这些情况下,我们可以从输入的高斯分布中抽取多个实例,从而得到多个输出图像。
我们也可以选择一个没有人工制品的手动或在输出图像中选择平均感知距离最小的图像。
对于性别属性,使用一个简单的外部预先训练的性别检测网络。
总的来说,推理阶段需要每幅图像约130毫秒。

生成质量的评估上,文中方法的结果可以与Toonify(2020的一个模型)和其他最近的非配对图像翻译技术,包括CycleGan(2017年),UNIT(2017年)和UGATIT(2020年)。
文中的对比结果由使用了作者的代码和设置来训练他们的模型,在作者提供的卡通数据集上传输给生成器。在他们的方法中,他们使用优化方法嵌入在潜在空间中输入图像,并将相应的编码输入到迁移学习得到的生成器。对于其他三种图像翻译方法,还使用了各自作者的代码和设置,以便在CelebA训练总的数据集和卡通数据集。
由于收敛困难和GPU内存限制,这些方法无法直接支持1024×1024分辨率,因此保持原来的256×256参与训练,输出到1024×1024进行比较。
Toonify的结果展示一些可见的人工制品,如不寻常的淡黄色斑块。
至于其他未配对的图像翻译方法,除了没有支持更高的决议,他们也没有很好地应付时用有限的范例训练。
作者
文中的第一作者是来自南洋理工大学的四年级博士生Song Guoxian,目前在字节跳动美国AI lab实习。
主要的研究兴趣是计算机视觉和图形,包括基于图像的 3D 人脸重建/分析、注视估计、人像重绘,尤其是针对 VR/AR 应用程序。
在线试用
模型提供了一个在线试用的网站。
当输入一张肖像图时,可以选择生成三种风格的动漫图片。

卡通风格:
油画风格:

漫画风格:

你学废了吗?
参考资料:
https://twitter.com/ylecun/status/1402148354688229376?s=21
https://guoxiansong.github.io/homepage/agilegan.html

点个在看 paper不断!