
2202年了,继续大比拼ViT、MLP、CNN结构有意义吗??

文 | 卖萌菌
转自 | 夕小瑶的卖萌屋
近日,MSRA发布了一篇题为《Transformer不比CNN强 Local Attention和动态Depth-wise卷积前世今生》的博文,再次谈论了这个老生常谈的话题。文中提到,Depth-wise CNN 和 attention 存在高度相似的结构,调参优化之后,从结果上来看,指标上也没相差多少。如果从输入到输出的传播路径上来看,CNN 和 self-attention ,从视角上看,其最终汇总到的特征,的确都是类似的,例如,self-attention 一层可以看作是全连接的一跳,经 N 层之后,形成了 N 跳可达。CNN 则也类似,二者都是在整个输入空间下,各单元之间的关联强度。只是实现路径不同。
博文发出之后,加州大学伯克利分校,统计学大佬,马毅教授转发并评论:
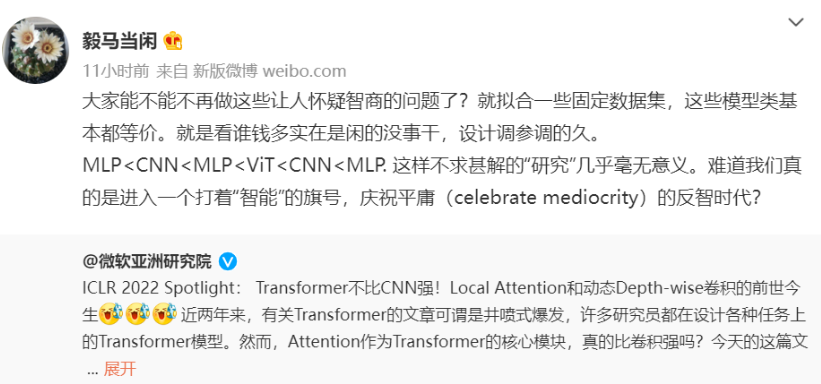
事实上,这不是马毅教授第一次对类似的研究开炮,之前几乎所有所谓优化 transformer,以及transformer、CNN、MLP 之争,马毅教授都会发表类似的观点,例如:

溯源Transformer、CNN、MLP 之争
Transformer、CNN、MLP 之争到底是什么时候开始的呢?
我们可以把时间拉回到一年之前。
2021年5月4日,谷歌大脑团队在arxiv上提交了一篇论文《MLP-Mixer: An all-MLP Architecture for Vision》,这篇论文是原视觉Transformer(ViT)团队的一个纯MLP架构的尝试。总结来说就是提出了一种仅仅需要多层感知机的框架——MLP-Mixer,无需卷积模块、注意力机制,即可达到与CNN、Transformer相媲美的图像分类性能。
众所周知,CV领域主流架构的演变过程是 MLP->CNN->Transformer 。MLP->CNN->Transformer 的演变之路难道现在要变成 MLP->CNN->Transformer->MLP ?
这难道就是学术“圈”的真谛吗?
下图是MLP-Mixer的框架图,详细细节说明可查看原论文。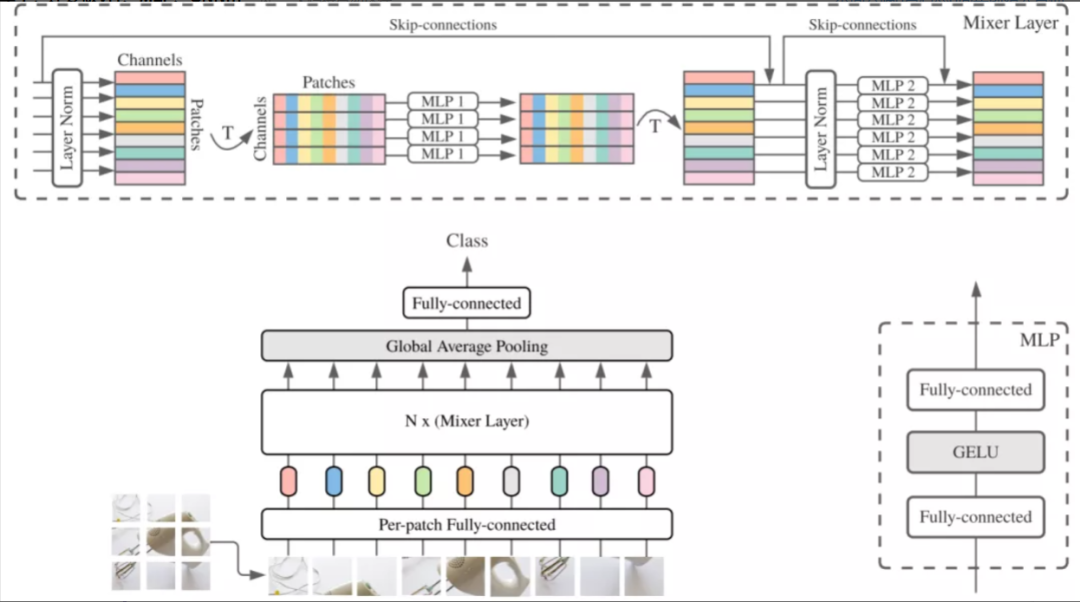
当时就有知乎网友表示“这个网络和Transformer很接近,关键还是故事编的好,实际上只要标题取得好,轮子重复发明没人会在乎的”。

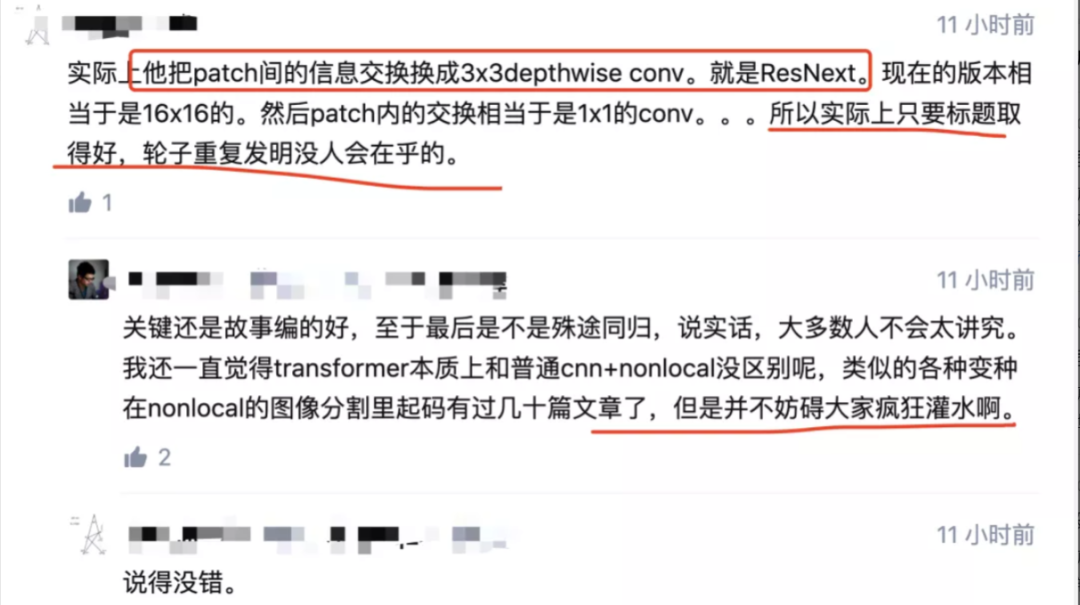
此文一出,一石激起千层浪。
只隔一天,2021年5月5日,清华大学图形学实验室Jittor团队在arXiv上也提交了一篇和MLP相关的论文《Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks》。这篇论文提出了一种新的注意力机制,称之为External Attention。
同日,清华大学软件学院丁贵广团队在arXiv上也提交了论文《RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition》,该论文中结合重参数化技术的MLP也能取得不错的视觉性能。
又隔了一天的5月6日,牛津大学的学者提交了一篇名为《Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet》的论文,表示attention机制是不必要的,仅仅使用反向传播就可以在ImageNet上取得非常高的结果。
那几天,AI圈“辩论之王”、图灵奖得主 LeCun也在推特上针对谷歌的MLP-Mixer论文简单的发声了,LeCun表示这篇论文并不是完全的没有卷积网络。

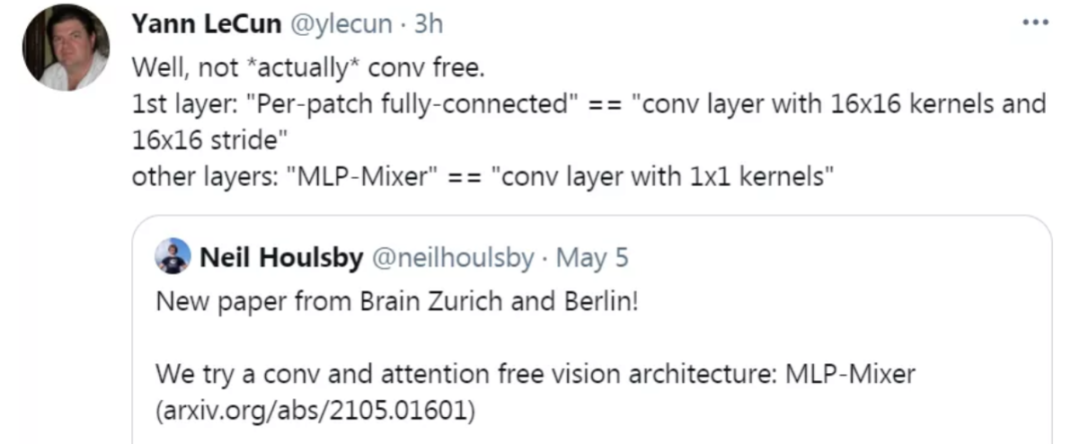
自此,Transformer、CNN、MLP 大论战开始。
也是在一年前的那几天,马教授表态:Transformers和MLP对图像patch sequences做处理时与CNN数学概念几乎完全等价。

所以...有必要吗?
回答本文的标题,2202年了,还要做ViT、MLP、CNN结构大比拼这种智商捉急的研究吗?
关于这个问题的答案,卖萌屋作者内部也兵分两派,产生了分歧。欢迎各位在评论区发表看法。
反方观点:“没必要”
确如马教授所说,从数学概念上讲,attention 和 CNN 几乎完全等价。现在研究界不断地通过刷榜来转着圈儿灌水,属实是毫无新意。
而且实验也仅仅是在固定数据集上打榜。无非是比拼谁的算力比较强,谁先过拟合出来一个更好的分数。其弊端在萌屋之前的推文(Google掀桌了,GLUE基准的时代终于过去了?)也有过讨论。如果整个学界的研究重心都倾注在这些事情上,那自然也会让人痛心。
本人非常支持马毅老师的观点:
正方观点:“有必要”
纵使CNN和Transformer在数学上等价,它们面对不同的任务时,不同的网络所带来的效益是不能等同的。哪怕同样是MLP网络,100多层的MLP和10层的MLP所取得的性能提升不一样的,同样是CNN网络,前些年被封为恺明神作的100多层的ResNet和简单的100多层纯CNN网络,在应用到下游任务时,性能的对比也是非常之大的。
也不能因为 ResNet和CNN本质无差别,所以否定ResNet以及之后的DenseNet、ResNetX等一切系列网络。就好像我们可以认为刀和剑本质上也是相同的,都是金属嘛,但是在战斗之中也是各有专长。好比手枪、步枪、机关枪都是枪,难道会有人因此拒绝哒哒哒冒蓝火的加特林吗?

而且,一个很无奈的事实是:在有团队能做出下一个 AI 历史性突破之前,大家都要在各自细分领域不断探索、内卷,甚至难免灌水...不然等着失业吗?
其实强如DeepMind说是要搞通用人工智能,但最近几年却一直在发力AI for Science,毕竟这个方向好落地啊,也能带来很大的科学应用价值。不是DeepMind不想全心全意搞通用人工智能,而是太难了,他们现在还搞不出来。先搞搞AI for Science,搞一波大的宣传,造血续命,让东家买账,何乐而不为呢?
往期精彩: