
Python分析三季度基金调仓

1
获取数据
from jqdatasdk import *
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'] # mac matplot显示中文
plt.rcParams['axes.unicode_minus'] = False
auth('聚宽账户', '聚宽密码') # 聚宽授权
df = get_all_securities(['fund', 'open_fund'], '2021-11-10')
df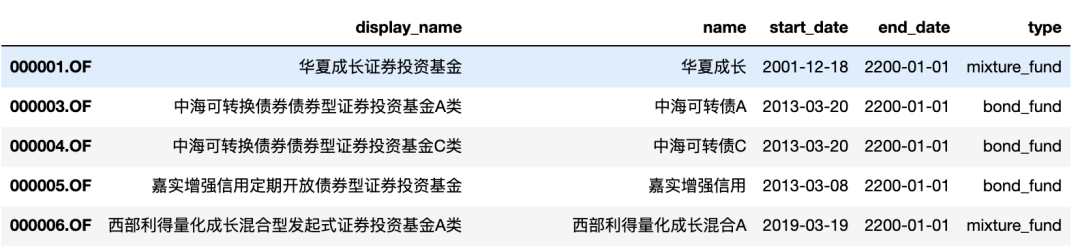
code_arr = list(set([x.split('.')[0] for x in df.index.values]))
len(code_arr)2
获取股票投资占比
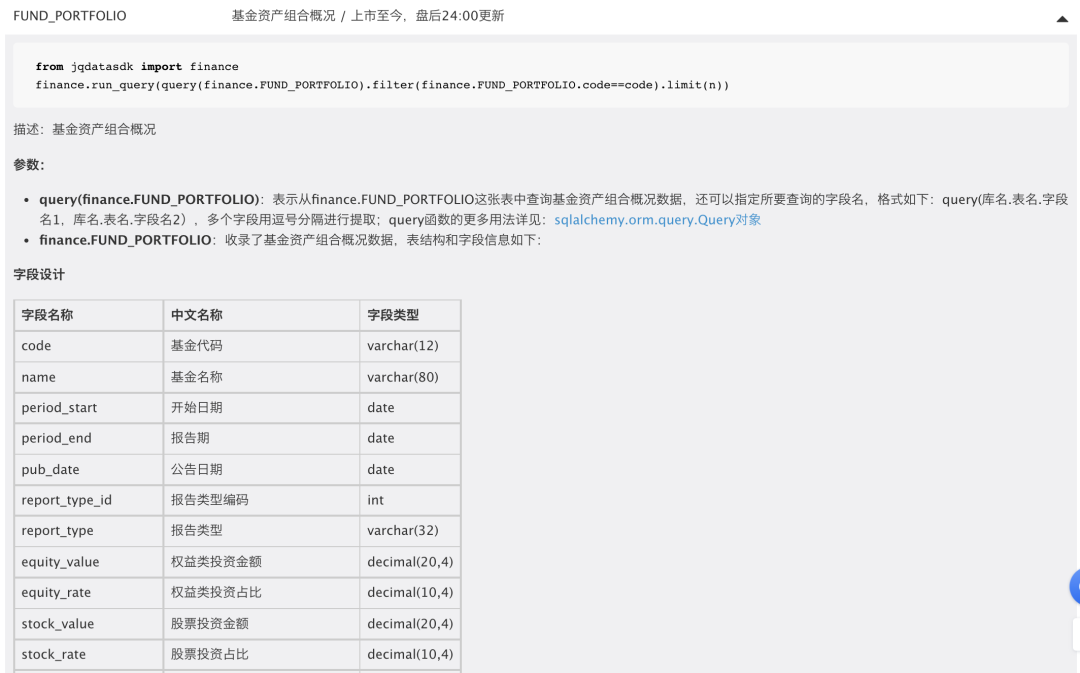
def asset_query(arr):
q=query(finance.FUND_PORTFOLIO.code,
finance.FUND_PORTFOLIO.name,
finance.FUND_PORTFOLIO.period_end,
finance.FUND_PORTFOLIO.report_type,
finance.FUND_PORTFOLIO.stock_rate
).filter(finance.FUND_PORTFOLIO.code.in_(arr),
finance.FUND_PORTFOLIO.period_end.in_(['2021-03-31', '2021-06-30', '2021-09-30']),
finance.FUND_PORTFOLIO.report_type.in_(['第一季度', '第二季度', '第三季度']))
return qi = 0
while i < len(code_arr):
print('获取基金资产 ' + str(i))
tmp_arr = code_arr[i: i+1500]
q = asset_query(tmp_arr)
tmp_df = finance.run_query(q)
if i == 0:
asset_df = tmp_df
else:
asset_df = pd.concat([asset_df, tmp_df])
i += 1500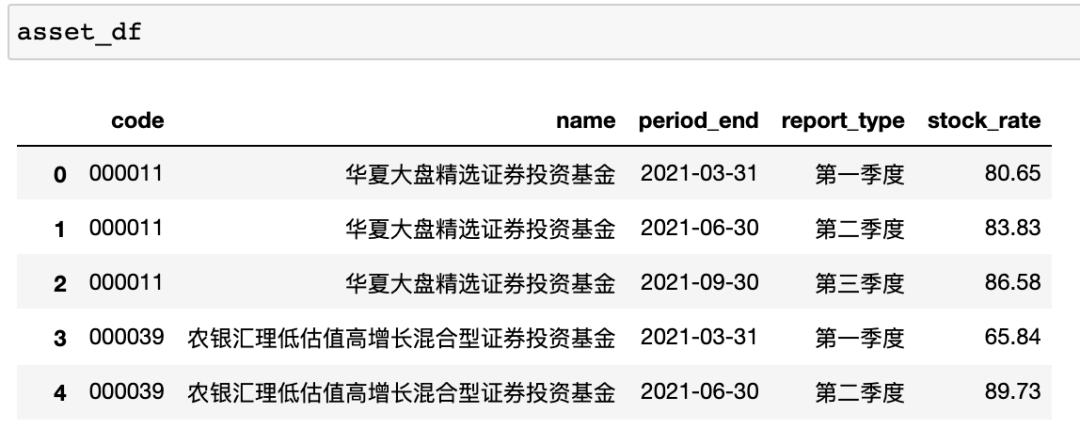
stock_fund_df = asset_df[asset_df['stock_rate'] > 50]stock_fund_code_arr = list(set(stock_fund_df['code']))
len(stock_fund_code_arr)3
获取基金持仓
def hold_stock_query(arr):
q=query(finance.FUND_PORTFOLIO_STOCK
).filter(finance.FUND_PORTFOLIO_STOCK.code.in_(arr),
finance.FUND_PORTFOLIO_STOCK.rank <= 10,
finance.FUND_PORTFOLIO_STOCK.period_end.in_(['2021-03-31', '2021-06-30', '2021-09-30']),
finance.FUND_PORTFOLIO_STOCK.report_type.in_(['第一季度', '第二季度', '第三季度']))
return qi = 0
while i < len(stock_fund_code_arr):
print('获取基金持仓 ' + str(i))
tmp_arr = stock_fund_code_arr[i: i+150]
q = hold_stock_query(tmp_arr)
tmp_df=finance.run_query(q)
if i == 0:
hold_stock_df = tmp_df
else:
hold_stock_df = pd.concat([hold_stock_df, tmp_df])
i += 150
hold_stock_df
4
调仓方向
stock_to_industry_dict = {
'比亚迪':'新能源',
'宁德时代':'新能源',
'恩捷股份':'新能源',
'赣锋锂业':'新能源',
'亿纬锂能':'新能源',
'汇川技术':'新能源',
'圣邦股份':'半导体',
'韦尔股份':'半导体',
'卓胜微':'半导体',
'北方华创':'半导体',
'兆易创新':'半导体',
'三安光电':'半导体',
'贵州茅台':'白酒',
'五粮液':'白酒',
'山西汾酒':'白酒',
'泸州老窖':'白酒',
'洋河股份':'白酒',
'酒鬼酒':'白酒',
'阳关电源':'光伏',
'通威股份':'光伏',
'中环股份':'光伏',
'隆基股份':'光伏',
'特变电工':'光伏',
'正泰电器':'光伏',
'药明康德':'医疗',
'智飞生物':'医疗',
'沃森生物':'医疗',
'泰格医药':'医疗',
'长春高新':'医疗',
'凯莱英':'医疗',
'复星医药':'医疗',
}def stock_to_industry(cols):
if cols['name'] in stock_to_industry_dict:
return stock_to_industry_dict[cols['name']]
return '无'
hold_stock_df['industry'] = hold_stock_df.apply(lambda x: stock_to_industry(x), axis=1)
hold_stock_dfhold_stock_df[hold_stock_df['code'] == '005939']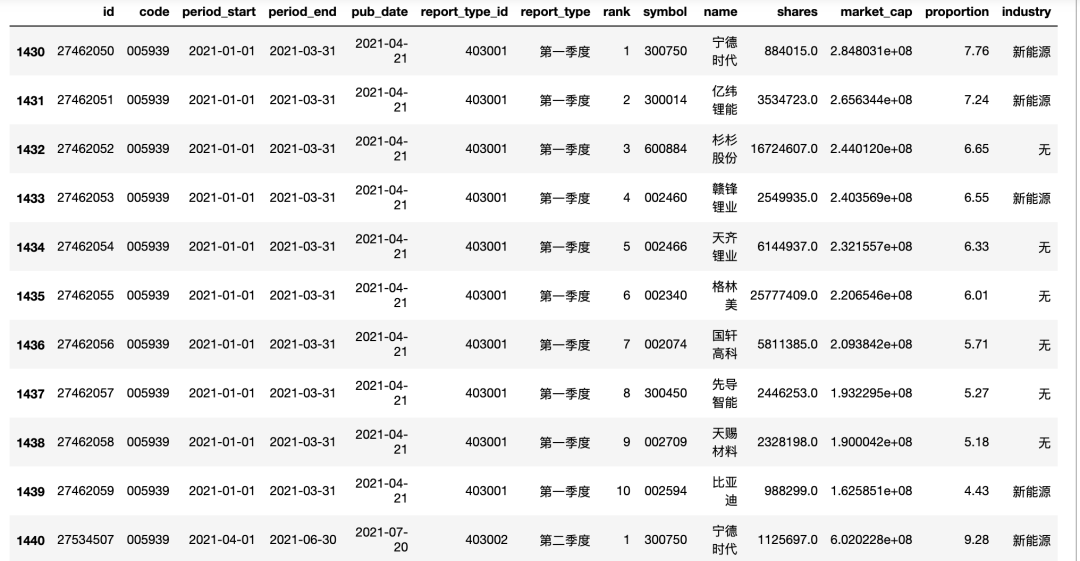
industry_count_df = hold_stock_df.pivot_table(index='industry',
columns=['report_type'],
values='code',
aggfunc=lambda x:len(x.unique()))
cols_name = ['第一季度', '第二季度', '第三季度']
industry_count_df = industry_count_df[cols_name]
industry_count_df.drop(['无'], inplace=True)
plt.rcParams['figure.figsize'] = (12, 8)
industry_count_df.plot.bar()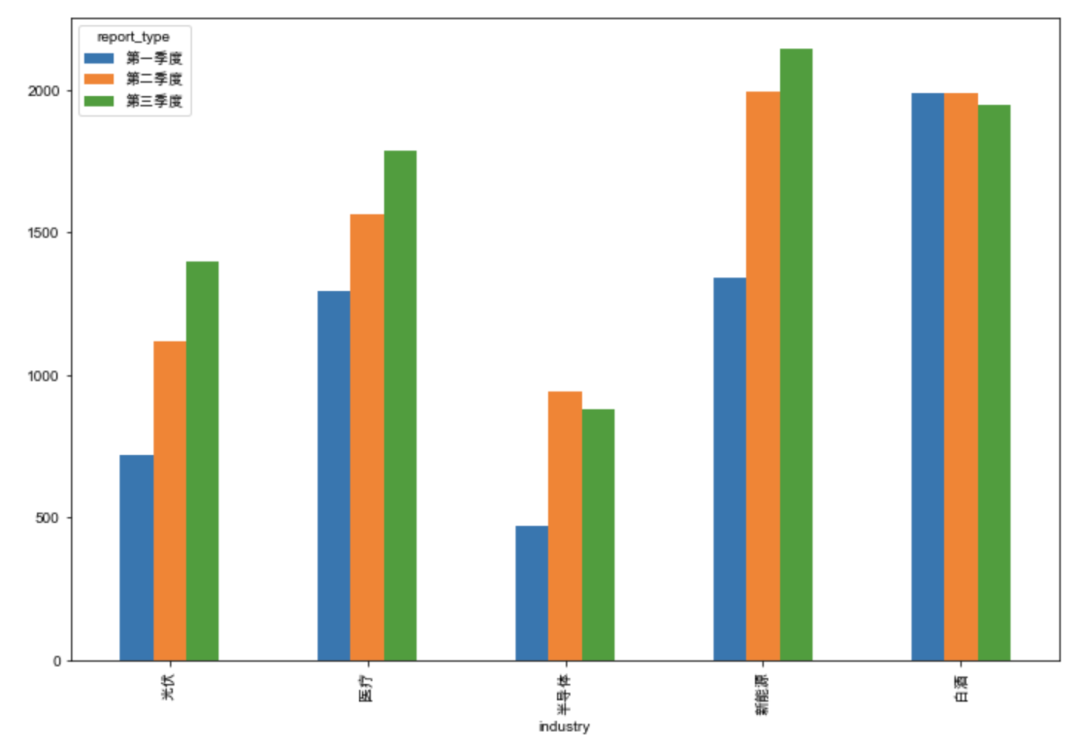
5
探索更有意思的
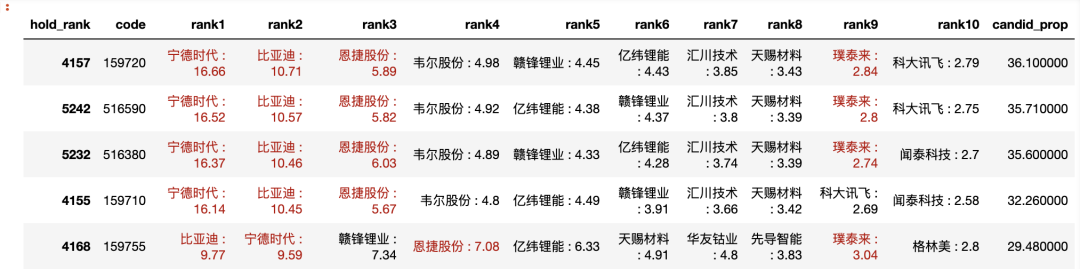
hold_stock_p3_df = hold_stock_df[hold_stock_df['report_type'] == '第三季度']hold_stock_p3_df['hold_rank'] = ['rank%d' % i for i in hold_stock_p3_df['rank']]
hold_stock_p3_df['hold_info'] = hold_stock_p3_df['name'] + " : " + hold_stock_p3_df['proportion'].astype(str)tmp_df = hold_stock_p3_df.pivot(index='code', columns='hold_rank', values='hold_info')
tmp_idx = tmp_df.index
tmp_df = tmp_df.reset_index()
tmp_df['name'] = tmp_idx
rank_cols = ['rank%d' % i for i in range(1, 11)]
col_names = ['code'] + rank_cols
final_fund_df = tmp_df[col_names]
final_fund_df
candid_fund_list = ['宁德时代','比亚迪', '恩捷股份', '璞泰来', '诺德股份']def filter_fund(x):
all_prop = 0
for i in range(1, 11):
col = 'rank' + str(i)
vals = str(x[col]).split(':')
if vals[0].strip() in candid_fund_list:
all_prop += float(vals[1].strip())
return all_propdef show_color(val):
color = '#BB0000' if str(val).split(':')[0].strip() in candid_fund_list else ''
return 'color:%s' % colorfinal_fund_df['candid_prop'] = final_fund_df.apply(lambda x: filter_fund(x), axis=1)
tmp_fund_df = final_fund_df[final_fund_df['candid_prop'] > 0].sort_values(by='candid_prop', ascending=False)
tmp_fund_df = tmp_fund_df.style.applymap(show_color)
tmp_fund_df最后送大家一张我们投资星球的优惠券,星球主要是交流理财相关的知识,目前涉及基金,股票和其他的一些投资品种,里面高手很多,有基金今年赚89%的高手,还有一些投资其他品种赚6倍的大神。投资群信息差非常非常重要,需要抱团取暖才能走的远,有兴趣的赶紧上车。
学投资,交个朋友
推荐阅读:
入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径
干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影
趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!
AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影
小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|

年度爆款文案
点阅读原文,看200个Python案例!
评论