
数据分析入门系列教程-数据采集
前面我们一起完成了一个数据清洗的实战教程。现在,我们一起来学习数据采集的相关知识。
其实在当今社会,网络上充斥着大量有用的数据,我们只需要耐心的观察,再加上一些技术手段,就可以获取到大量的有价值数据。
不错,这里的“技术手段”就是网络爬虫。下面我们就一起进入到爬虫的世界吧!
爬虫基础
什么是爬虫呢?
爬虫就是自动获取网页内容的程序,例如搜索引擎,Google,Baidu 等,每天都运行着庞大的爬虫系统,从全世界的网站中爬虫数据,供用户检索时使用。
爬虫流程
其实把网络爬虫抽象开来看,它无外乎包含如下几个步骤
模拟请求网页。模拟浏览器,打开目标网站。
获取数据。打开网站之后,就可以自动化的获取我们所需要的网站数据。
保存数据。拿到数据之后,需要持久化到本地文件或者数据库等存储设备中。
那么我们该如何使用 Python 来编写自己的爬虫程序呢,在这里我要重点介绍一个 Python 库:Requests。
Requests 使用
Requests 库是 Python 中发起 HTTP 请求的库,使用非常方便简单。
模拟发送 HTTP 请求
发送 GET 请求
当我们用浏览器打开豆瓣首页时,其实发送的最原始的请求就是 GET 请求
import requests
res = requests.get('http://www.douban.com')
print(res)
print(type(res))
>>>
200]>
<class 'requests.models.Response'>
可以看到,我们得到的是一个 Response 对象
如果我们要获取网站返回的数据,可以使用 text 或者 content 属性来获取
text:是以字符串的形式返回数据
content:是以二进制的方式返回数据
print(type(res.text))
print(res.text)
>>>
<class 'str'>
<html lang="zh-cmn-Hans" class="">
<head>
<meta charset="UTF-8">
<meta name="google-site-verification" content="ok0wCgT20tBBgo9_zat2iAcimtN4Ftf5ccsh092Xeyw" />
<meta name="description" content="提供图书、电影、音乐唱片的推荐、评论和价格比较,以及城市独特的文化生活。">
<meta name="keywords" content="豆瓣,广播,登陆豆瓣">.....
发送 POST 请求
对于 POST 请求,一般就是提交一个表单
r = requests.post('http://www.xxxx.com', data={"key": "value"})
data 当中,就是需要传递的表单信息,是一个字典类型的数据。
header 增强
对于有些网站,会拒绝掉没有携带 header 的请求的,所以需要做一些 header 增强。比如:UA,Cookie,host 等等信息。
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36",
"Cookie": "your cookie"}
res = requests.get('http://www.xxx.com', headers=header)
解析 HTML
现在我们已经获取到了网页返回的数据,即 HTML 代码,下面就需要解析 HTML,来提取其中有效的信息。
BeautifulSoup
BeautifulSoup 是 Python 的一个库,最主要的功能是从网页解析数据。
from bs4 import BeautifulSoup # 导入 BeautifulSoup 的方法
# 可以传入一段字符串,或者传入一个文件句柄。一般都会先用 requests 库获取网页内容,然后使用 soup 解析。
soup = BeautifulSoup(html_doc,'html.parser') # 这里一定要指定解析器,可以使用默认的 html,也可以使用 lxml。
print(soup.prettify()) # 按照标准的缩进格式输出获取的 soup 内容。
BeautifulSoup 的一些简单用法
print(soup.title) # 获取文档的 title
print(soup.title.name) # 获取 title 的 name 属性
print(soup.title.string) # 获取 title 的内容
print(soup.p) # 获取文档中第一个 p 节点
print(soup.p['class']) # 获取第一个 p 节点的 class 内容
print(soup.find_all('a')) # 获取文档中所有的 a 节点,返回一个 list
print(soup.find_all('span', attrs={'style': "color:#ff0000"})) # 获取文档中所有的 span 且 style 符合规则的节点,返回一个 list
具体的用法和效果,我会在后面的实战中详细说明。
XPath 定位
XPath 是 XML 的路径语言,是通过元素和属性进行导航定位的。几种常用的表达式
| 表达式 | 含义 |
|---|---|
| node | 选择 node 节点的所有子节点 |
| / | 从根节点选取 |
| // | 选取所有当前节点 |
| . | 当前节点 |
| .. | 父节点 |
| @ | 属性选取 |
| text() | 当前路径下的文本内容 |
一些简单的例子
xpath('node') # 选取 node 节点的所有子节点
xpath('/div') # 从根节点上选取 div 元素
xpath('//div') # 选取所有 div 元素
xpath('./div') # 选取当前节点下的 div 元素
xpath('//@id') # 选取所有 id 属性的节点
当然,XPath 非常强大,但是语法也相对复杂,不过我们可以通过 Chrome 的开发者工具来快速定位到元素的 xpath,如下图
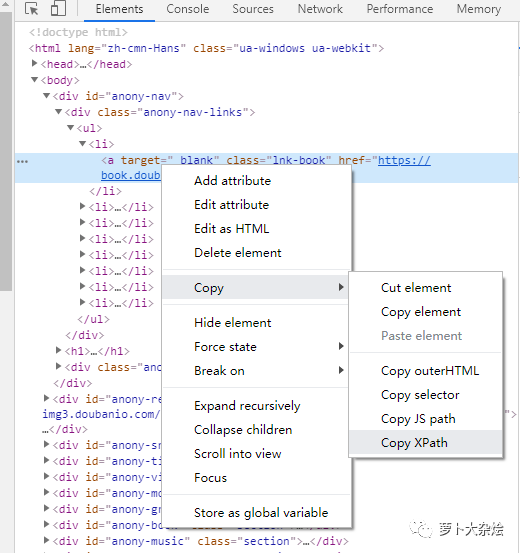
得到的 xpath 为
//*[@id="anony-nav"]/div[1]/ul/li[1]/a
在实际的使用过程中,到底使用 BeautifulSoup 还是 XPath,完全取决于个人喜好,哪个用起来更加熟练方便,就使用哪个。
爬虫实战:爬取豆瓣海报
我们可以从豆瓣影人页,进入都影人对应的影人图片页面,比如以刘涛为例子,她的影人图片页面地址为
https://movie.douban.com/celebrity/1011562/photos/
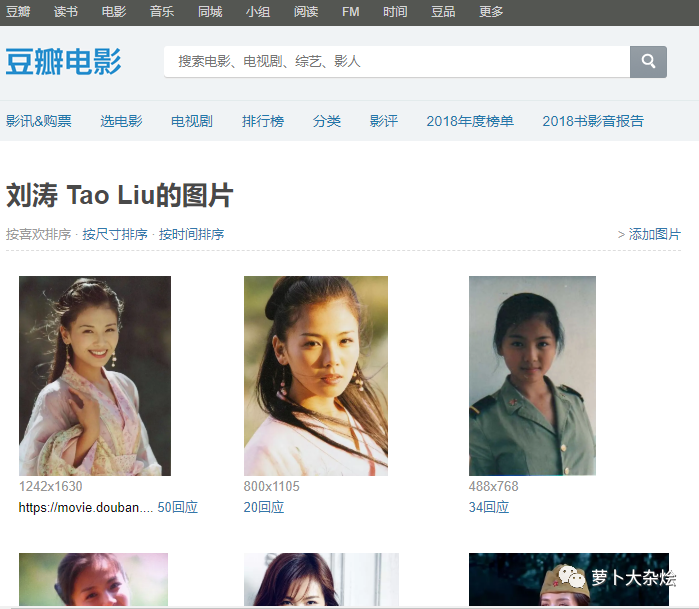
下面我们就来分析下这个网页
目标网站页面分析
注意:网络上的网站页面构成总是会变化的,所以这里你需要学会分析的方法,以此类推到其他网站。正所谓授人以鱼不如授人以渔,就是这个原因。
Chrome 开发者工具
Chrome 开发者工具(按 F12 打开),是分析网页的绝佳利器,一定要好好使用。
我们在任意一张图片上右击鼠标,选择“检查”,可以看到同样打开了“开发者工具”,而且自动定位到了该图片所在的位置
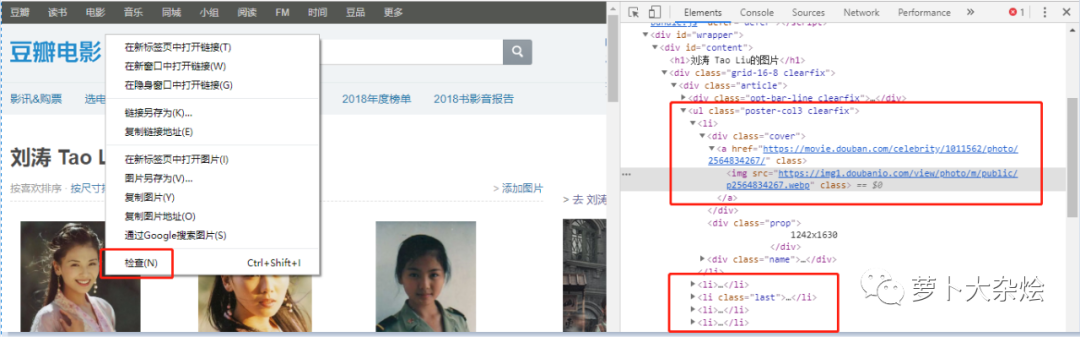
可以清晰的看到,每张图片都是保存在 li 标签中的,图片的地址保存在 li 标签中的 img 中。
知道了这些规律后,我们就可以通过 BeautifulSoup 或者 XPath 来解析 HTML 页面,从而获取其中的图片地址。
代码编写
我们只需要短短的几行代码,就能完成图片 url 的提取
import requests
from bs4 import BeautifulSoup
url = 'https://movie.douban.com/celebrity/1011562/photos/'
res = requests.get(url).text
content = BeautifulSoup(res, "html.parser")
data = content.find_all('div', attrs={'class': 'cover'})
picture_list = []
for d in data:
plist = d.find('img')['src']
picture_list.append(plist)
print(picture_list)
>>>
['https://img1.doubanio.com/view/photo/m/public/p2564834267.jpg', 'https://img1.doubanio.com/view/photo/m/public/p860687617.jpg', 'https://img1.doubanio.com/view/photo/m/public/p2174001857.jpg', 'https://img1.doubanio.com/view/photo/m/public/p1563789129.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2363429946.jpg', 'https://img1.doubanio.com/view/photo/m/public/p2382591759.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2363269182.jpg', 'https://img1.doubanio.com/view/photo/m/public/p1959495269.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2356638830.jpg', 'https://img3.doubanio.com/view/photo/m/public/p1959495471.jpg', 'https://img3.doubanio.com/view/photo/m/public/p1834379290.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2325385303.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2361707270.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2325385321.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2196488184.jpg', 'https://img1.doubanio.com/view/photo/m/public/p2186019528.jpg', 'https://img1.doubanio.com/view/photo/m/public/p2363270277.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2325240501.jpg', 'https://img1.doubanio.com/view/photo/m/public/p2258657168.jpg', 'https://img1.doubanio.com/view/photo/m/public/p2319710627.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2319710591.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2311434791.jpg', 'https://img1.doubanio.com/view/photo/m/public/p2363270708.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2258657185.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2166193915.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2363265595.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2312085755.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2311434790.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2276569205.jpg', 'https://img1.doubanio.com/view/photo/m/public/p2165332728.jpg']
可以看到,是非常干净的列表,里面存储了海报地址。
但是这里也只是一页海报的数据,我们观察页面发现它有好多分页,如何处理分页呢。
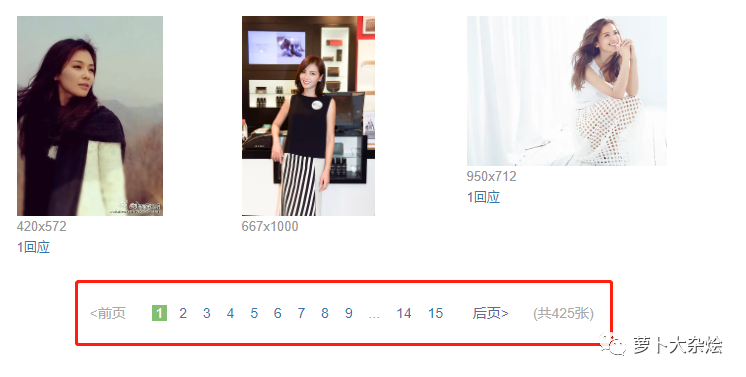
分页处理
我们点击第二页,看看浏览器 url 的变化
https://movie.douban.com/celebrity/1011562/photos/?type=C&start=30&sortby=like&size=a&subtype=a
发现浏览器 url 增加了几个参数
再点击第三页,继续观察 url
https://movie.douban.com/celebrity/1011562/photos/?type=C&start=60&sortby=like&size=a&subtype=a
通过观察可知,这里的参数,只有 start 是变化的,即为变量,其余参数都可以按照常理来处理
同时还可以知道,这个 start 参数应该是起到了类似于 page 的作用,start = 30 是第二页,start = 60 是第三页,依次类推,最后一页是 start = 420。
于是我们处理分页的代码也呼之欲出了
首先将上面处理 HTML 页面的代码封装成函数
def get_poster_url(res):
content = BeautifulSoup(res, "html.parser")
data = content.find_all('div', attrs={'class': 'cover'})
picture_list = []
for d in data:
plist = d.find('img')['src']
picture_list.append(plist)
return picture_list
然后我们在另一个函数中处理分页和调用上面的函数
def fire():
page = 0
for i in range(0, 450, 30):
print("开始爬取第 %s 页" % page)
url = 'https://movie.douban.com/celebrity/1011562/photos/?type=C&start={}&sortby=like&size=a&subtype=a'.format(i)
res = requests.get(url).text
data = get_poster_url(res)
page += 1
此时,我们所有的海报数据都保存在了 data 变量中,现在就需要一个下载器来保存海报了
def download_picture(pic_l):
if not os.path.exists(r'picture'):
os.mkdir(r'picture')
for i in pic_l:
pic = requests.get(i)
p_name = i.split('/')[7]
with open('picture\\' + p_name, 'wb') as f:
f.write(pic.content)
再增加下载器到 fire 函数,此时为了不是请求过于频繁而影响豆瓣网的正常访问,设置 sleep time 为1秒
def fire():
page = 0
for i in range(0, 450, 30):
print("开始爬取第 %s 页" % page)
url = 'https://movie.douban.com/celebrity/1011562/photos/?type=C&start={}&sortby=like&size=a&subtype=a'.format(i)
res = requests.get(url).text
data = get_poster_url(res)
download_picture(data)
page += 1
time.sleep(1)
下面就执行 fire 函数,等待程序运行完成后,当前目录下会生成一个 picture 的文件夹,里面保存了我们下载的所有海报
核心代码讲解
下面再来看下完整的代码
import requests
from bs4 import BeautifulSoup
import time
import osdef fire():
page = 0
for i in range(0, 450, 30):
print("开始爬取第 %s 页" % page)
url = 'https://movie.douban.com/celebrity/1011562/photos/?type=C&start={}&sortby=like&size=a&subtype=a'.format(i)
res = requests.get(url).text
data = get_poster_url(res)
download_picture(data)
page += 1
time.sleep(1)def get_poster_url(res):
content = BeautifulSoup(res, "html.parser")
data = content.find_all('div', attrs={'class': 'cover'})
picture_list = []
for d in data:
plist = d.find('img')['src']
picture_list.append(plist)
return picture_listdef download_picture(pic_l):
if not os.path.exists(r'picture'):
os.mkdir(r'picture')
for i in pic_l:
pic = requests.get(i)
p_name = i.split('/')[7]
with open('picture\\' + p_name, 'wb') as f:
f.write(pic.content)if __name__ == '__main__':
fire()
fire 函数
这是一个主执行函数,使用 range 函数来处理分页。
range 函数可以快速的创建整数列表,在 for 循环时及其好用。函数中的0代表从0开始计数,450代表一直迭代到450,不包含450,30代表步长,即每次递增的数字间隔。range(0, 450, 30),依次会输出:0,30,60,90 …
format 函数,是一种字符串格式化方式
time.sleep(1) 即为暂停1秒钟
get_poster_url 函数
这个就是解析 HTML 的函数,使用的是 BeautifulSoup
通过 find_all 方法查找所有 class 为 “cover” 的 div 元素,返回的是一个列表
使用 for 循环,循环上一步拿到的列表,取出 src 的内容,append 到列表中
append 是列表的一个方法,可以在列表后面追加元素
download_picture 函数
简易图片下载器
首先判断当前目录下是否存在 picture 文件夹,os.path.exists
os 库是非常常用用来操作系统相关的命令库,os.mkdir 就是创建文件夹
split 用于切割字符串,取出角标为7的元素,作为存储图片的名称
with 方法用来快速打开文件,打开的进程可以自行关闭文件句柄,而不再需要手动执行 f.close() 关闭文件
总结
本节讲解了爬虫的基本流程以及需要用到的 Python 库和方法,并通过一个实际的例子完成了从分析网页,到数据存储的全过程。其实爬虫,无外乎模拟请求,解析数据,保存数据。
当然有的时候,网站还会设置各种反爬机制,比如 cookie 校验,请求频度检查,非浏览器访问限制,JS 混淆等等,这个时候就需要用到反反爬技术了,比如抓取 cookie 放到 headers 中,使用代理 IP 访问,使用 Selenium 模拟浏览器等待方式。
由于本课程不是专门的爬虫课,这些技能就留待你自己去探索挖掘啦。
