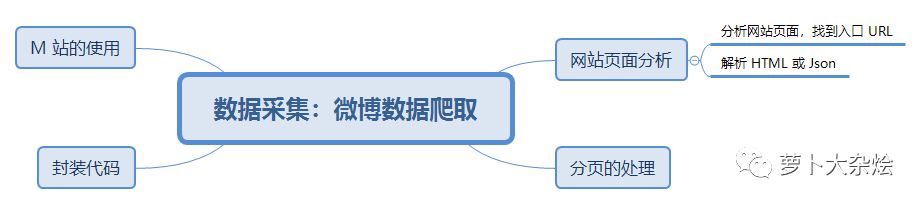
数据分析入门系列教程-微博热点
你玩微博吗
如果你玩微博,一定知道某些大 V 的一条微博,绝对拥有堵塞网络,撑爆服务器的威力。微博热搜,也成了流量圣地,很多人为了上热搜,已经到了近乎抓狂的地步。
如果你玩微博,那么一定知道,微博下面的评论,可是一座金山,里面藏着太多的神人和经典,绝对是不容错过的地方。
无论是官宣还是分手,无论是开撕还是出轨,都会到微博里搅动一番。那么该如何快速获取微博信息及评论呢,如何才能做出一个自动化的,可落地的爬虫工具呢。下面可以跟着我,一起看看怎么完成吧。
小试牛刀
先来看看对于某个微博的评论,该怎么做呢
微博页面分析
我们先进入如下的一个微博
https://weibo.com/1312412824/HxFY84Gqb?filter=hot&root_comment_id=0&type=comment#_rnd1567155548217
我们选择林志玲宣布结婚的那条微博为例
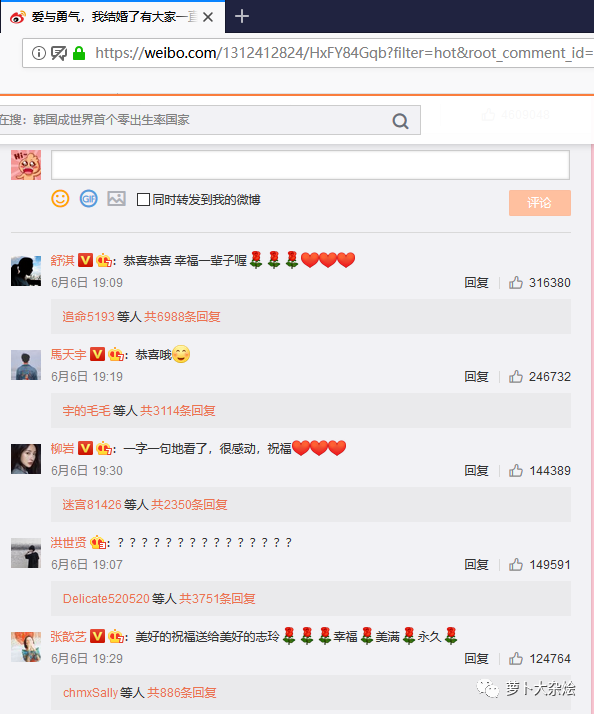
打开 Chrome 开发者工具(F12),切换到 Network 页签,再次刷新页面,能够看到一条请求,如下:
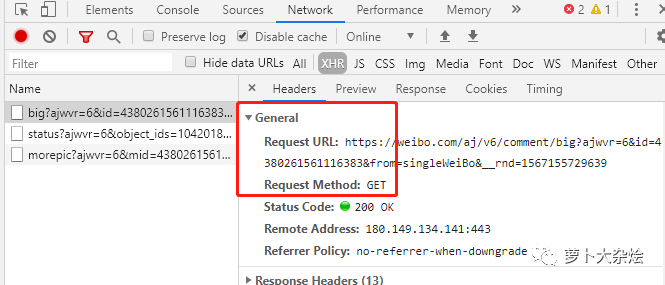
我们把这里的 URL 拷贝出来,放到 PostMan 中请求下(如果你还不知道 PostMan,那么赶紧去下载一个,是很好用的接口测试工具),发现得到的响应并不是正常的
https://weibo.com/aj/v6/comment/big?ajwvr=6&id=4380261561116383&from=singleWeiBo&__rnd=1567155729639
此时,我们就应该想到,尝试着增加 cookie
再观察刚刚 Network 中的请求,在 Request Headers 里,有一个 Cookie 字段,把这个字段拷贝出来,放进 PostMan 中再试试
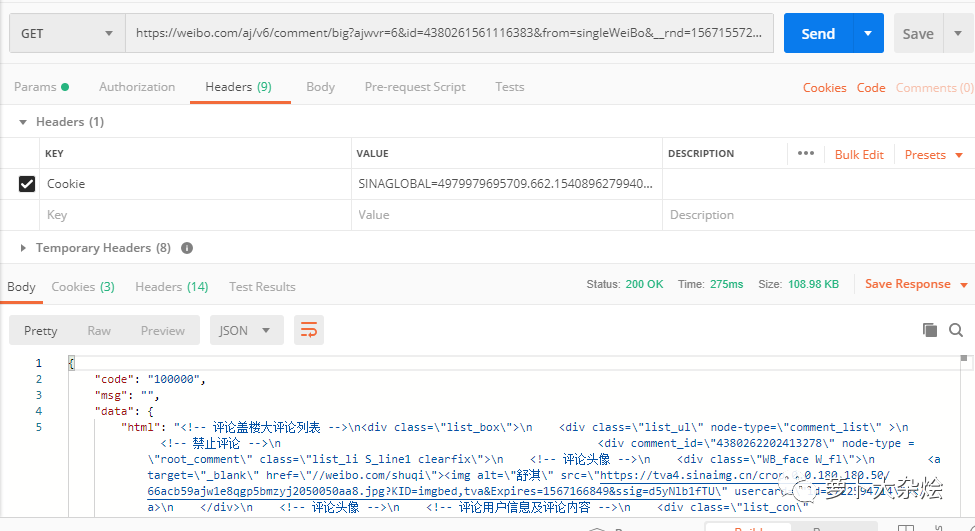
现在可以了,终于能够正常返回我们想要的数据了。
请注意 PostMan 添加 Cookie 的方式哦
URL 精简
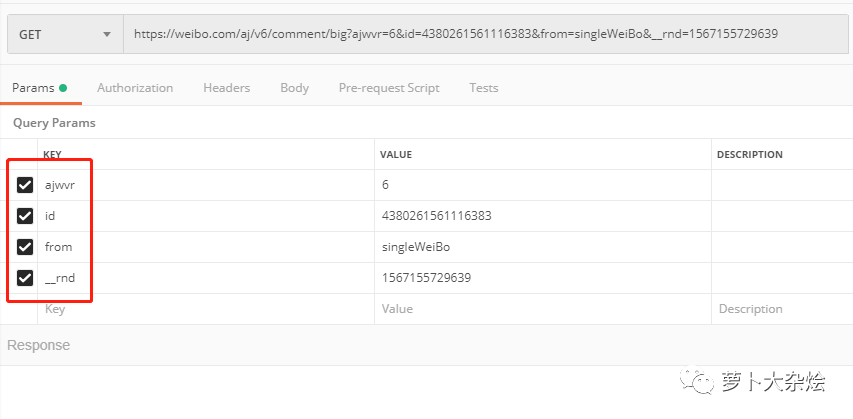
下面我们再来好好研究下这个 URL,它有很多的参数,有一些是可以精简掉的。
其实这个过程就是一个一个的删除参数,然后使用 PostMan 发送请求,看看在哪些参数情况下,响应是正常的。
最后我得到了如下的最精简的 URL
https://weibo.com/aj/v6/comment/big?ajwvr=6&id=4380261561116383
这里我希望你真正的动手去实操一下,逐个勾掉参数并发送请求,查看响应情况,真正的搞清楚,上面的精简 URL 是怎么来的。
URL 翻页
在完成 URL 精简之后,我们还需要处理评论分页的问题。
再次查看响应信息,发现在响应信息的最后,有一个 page 字段
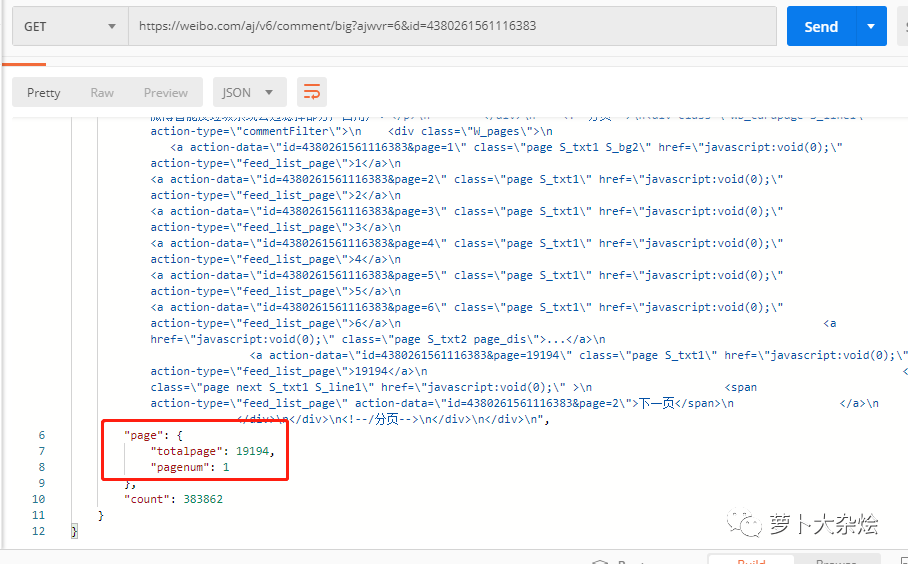
这里似乎是在告诉我们,当前的页数和总页数,那么出于经验,我们在 URL 中增加 page 参数,并设置为2,再次请求,看看这个字段是否会改变呢
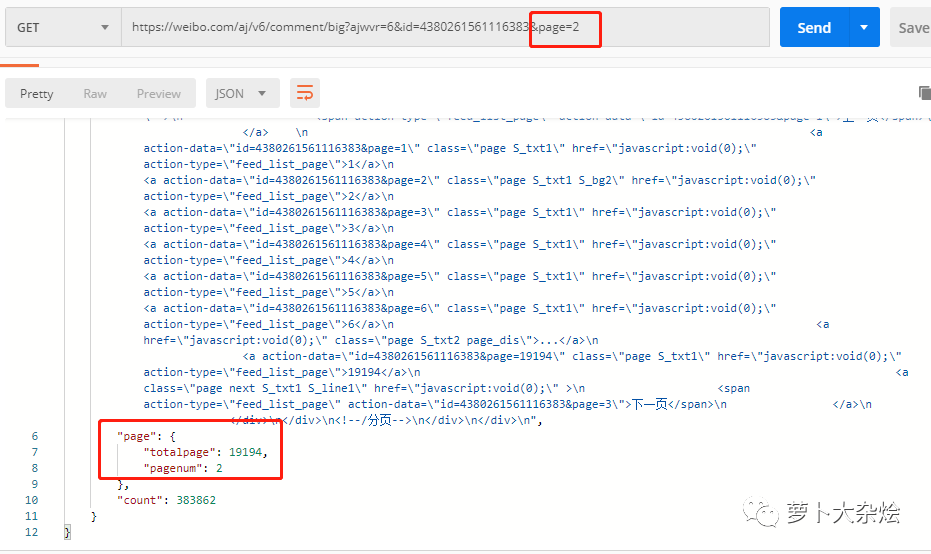
果然变了,说明参数设置成功,至此分页问题也解决了。
获取数据
既然可用的 URL 规则我们已经找到,下面就是发送请求,提取数据了
import requests
import json
from bs4 import BeautifulSoup
import pandas as pd
import timeHeaders = {'Cookie': 'SINAGLOBAL=4979979695709.662.1540896279940; SUB=_2AkMrYbTuf8PxqwJRmPkVyG_nb45wwwHEieKdPUU1JRMxHRl-yT83qnI9tRB6AOGaAcavhZVIZBiCoxtgPDNVspj9jtju; SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9W5d4hHnVEbZCn4G2L775Qe1; _s_tentry=-; Apache=1711120851984.973.1564019682028; ULV=1564019682040:7:2:1:1711120851984.973.1564019682028:1563525180101; login_sid_t=8e1b73050dedb94d4996a67f8d74e464; cross_origin_proto=SSL; Ugrow-G0=140ad66ad7317901fc818d7fd7743564; YF-V5-G0=95d69db6bf5dfdb71f82a9b7f3eb261a; WBStorage=edfd723f2928ec64|undefined; UOR=bbs.51testing.com,widget.weibo.com,www.baidu.com; wb_view_log=1366*7681; WBtopGlobal_register_version=307744aa77dd5677; YF-Page-G0=580fe01acc9791e17cca20c5fa377d00|1564363890|1564363890'}def sister(page):
sister = []
for i in range(0, page):
print("page: ", i)
url = 'https://weibo.com/aj/v6/comment/big?ajwvr=6&id=4380261561116383&page=%s' % int(i)
req = requests.get(url, headers=Headers).text
html = json.loads(req)['data']['html']
content = BeautifulSoup(html, "html.parser")
comment_text = content.find_all('div', attrs={'class': 'WB_text'})
for c in comment_text:
sister_text = c.text.split(":")[1]
sister.append(sister_text)
time.sleep(5) return sister
if __name__ == '__main__':
print("start")
sister_comment = sister(1001)
sister_pd = pd.DataFrame(columns=['sister_comment'], data=sister_comment)
sister_pd.to_csv('sister.csv', encoding='utf-8')
注意这里的 Headers,有一定的过期时间,当你运行该代码的时候,需要自行拷贝一份当前的 Cookie 替换。
代码解析:
由于响应的信息是一个 json,然后在 data 字段里面才是 HTML,所以要先解析 json 信息。可以使用 json.loads 来转化字符串到 json,或者也可以直接使用 requests.get(url, headers=Headers).json() 来获取响应信息中的 json 数据。
存储数据,采用了 Pandas 的输入输出。先创建一个 Pandas DataFrame 对象,然后通过 to_csv 函数保存至 csv 文件中。
至此,一个简单的微博评论爬虫就完成了,是不是足够简单呢?
自动化爬虫
下面我们来看看,我们爬取的流程是否有可以优化的地方呢
现在的实现是,我们手动找到了一篇微博,然后以该篇微博为起点,开始爬虫。那么以后的设想是,我只需要输入某位大 V 的微博名称,再输入微博中出现的一些字段,就能够自动爬取微博信息及微博对应的评论。
好的,让我们向着这个目标前进
微博搜索
既然是某位大 V,这里就肯定涉及到了搜索的事情,我们可以先来尝试下微博自带的搜索,地址如下:
https://s.weibo.com/user?q=林志玲
同样是先放到 PostMan 里请求下,看看能不能直接访问
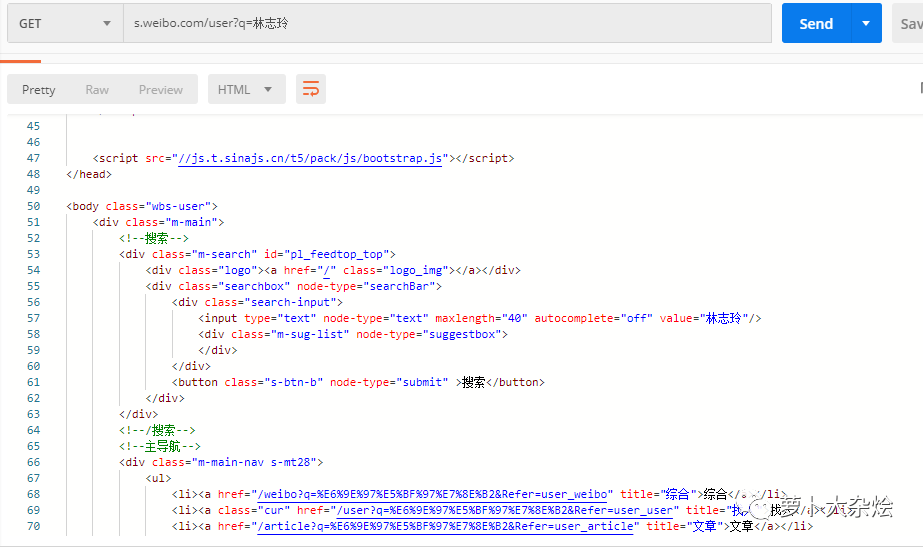
是可以正常返回数据的的,这就省去了我们很多的麻烦。下面就是来分析并解析响应消息,拿到对我们有用的数据。
经过观察可知,这个接口返回的数据中,有一个 UID 信息,是每个微博用户的唯一 ID,我们可以拿过来留作后面使用。
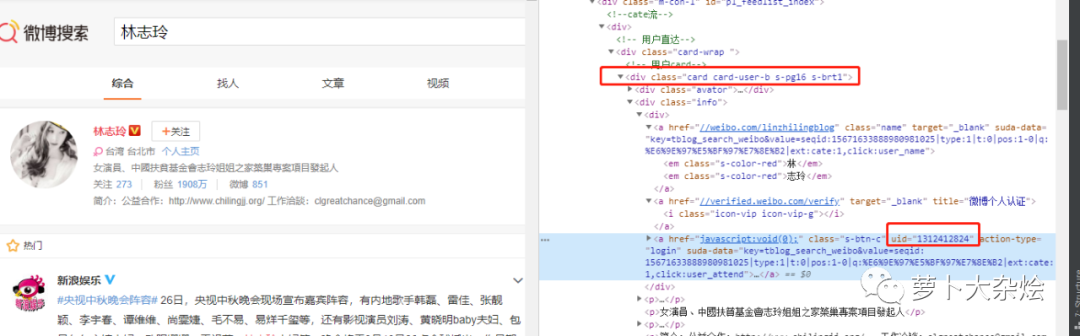
至于要如何定位到这个 UID,我也已经在图中做了标注,相信你只要简单分析下就能明白。
def get_uid(name):
try:
url = 'https://s.weibo.com/user?q=%s' % name
res = requests.get(url).text
content = BeautifulSoup(res, 'html.parser')
user = content.find('div', attrs={'class': 'card card-user-b s-pg16 s-brt1'})
user_info = user.find('div', attrs={'class': 'info'}).find('div')
href_list = user_info.find_all('a')
if len(href_list) == 3:
title = href_list[1].get('title')
if title == '微博个人认证':
uid = href_list[2].get('uid')
return uid
elif title == '微博会员':
uid = href_list[2].get('uid')
return uid
else:
print("There are something wrong")
return False
except:
raise
代码里都是我们讲过的知识,相信你完全可以看懂。
M 站的利用
M 站一般是指手机网页端的页面,也就是为了适配 mobile 移动端而制作的页面。一般的网站都是在原网址前面加“m.”来作为自己 M 站的地址,比如:m.baidu.com 就是百度的 M 站。
我们来打开微博的 M 站,再进入到林志玲的微博页面看看 Network 中的请求,有没有什么惊喜呢?
我们首先发现了这样一个 URL
https://m.weibo.cn/api/container/getIndex?uid=1312412824&luicode=10000011&lfid=100103type%3D1%26q%3D%E6%9E%97%E5%BF%97%E7%8E%B2&containerid=1005051312412824
接着继续拖动网页,发现 Network 中又有类似的 URL
https://m.weibo.cn/api/container/getIndex?uid=1312412824&luicode=10000011&lfid=100103type%3D1%26q%3D%E6%9E%97%E5%BF%97%E7%8E%B2&containerid=1076031312412824&page=2
随着该 URL 的出现,页面也展示了新的微博信息,显然该 URL 就是请求微博的 API。同样道理,把第二个 URL 放到 PostMan 中,看看哪些参数是可以省略的
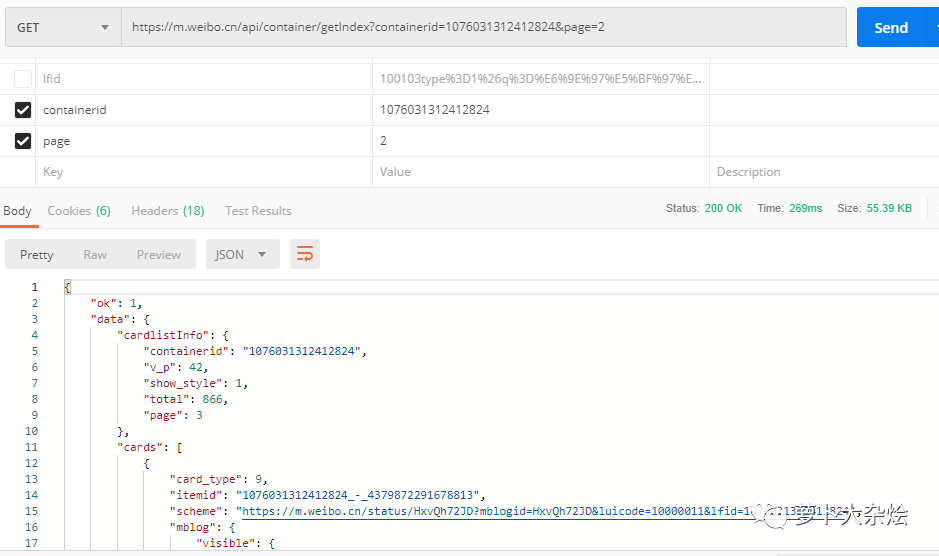
最后我们发现,只要传入正确的 containerid 信息,page 用来控制分页,就能够返回对应的微博信息,可是 containerid 信息又从哪里来呢?我们刚刚获得了一个 UID 信息,现在来尝试下能不能通过这个 UID 来获取到 containerid 信息。
这里就又需要一些经验了,我可以不停的尝试给接口“m.weibo.cn/api/container/getIndex”添加不同的参数,看看它会返回些什么信息,比如常见的参数名称 type,id,value,name 等等。最终,在我不懈的努力下,发现 type 和 value 的组合是成功的,可以拿到对应的 containerid 信息
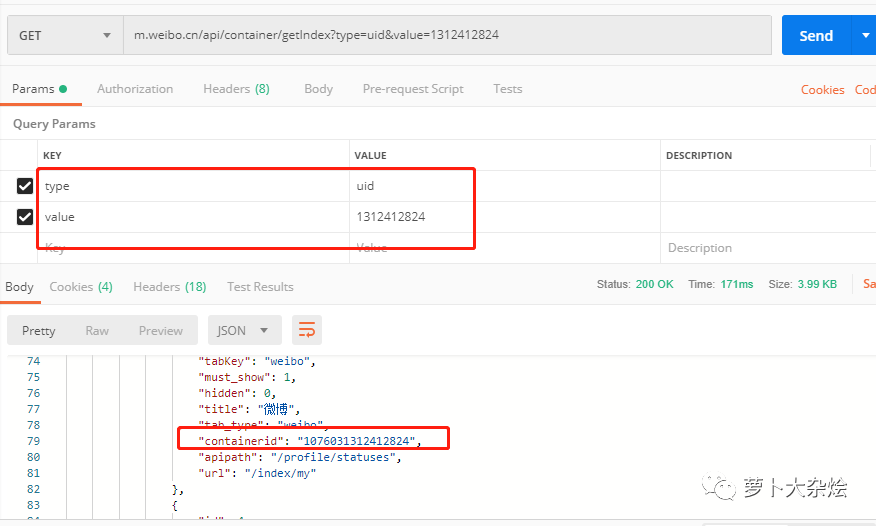
这个地方真的不有任何捷径了,只能靠尝试和经验,也是比较痛苦的地方,毕竟是靠全黑盒的形式来试探其他系统的 API。
现在就可以编写代码,获取对应的 containerid 了(如果你细心的话,还可以看到这个接口还返回了很多有意思的信息,可以自己尝试着抓取)。
def get_userinfo(uid):
try:
url = 'https://m.weibo.cn/api/container/getIndex?type=uid&value=%s' % uid
res = requests.get(url).json()
containerid = res['data']['tabsInfo']['tabs'][1]['containerid']
mblog_counts = res['data']['userInfo']['statuses_count']
followers_count = res['data']['userInfo']['followers_count']
userinfo = {
"containerid": containerid,
"mblog_counts": mblog_counts,
"followers_count": followers_count
}
return userinfo
except:
raise
代码都是最基本的操作,就不做过多的解释了。
下面就是保存微博信息了
微博信息就保存在 res['data']['cards'] 下面,有评论、转发,点赞数量等等信息。于是我们解析该 json 数据的函数就有了:
def get_blog_info(cards, i, name, page):
blog_dict = {}
if cards[i]['card_type'] == 9:
scheme = cards[i]['scheme'] # 微博地址
mblog = cards[i]['mblog']
mblog_text = mblog['text']
create_time = mblog['created_at']
mblog_id = mblog['id']
reposts_count = mblog['reposts_count'] # 转发数量
comments_count = mblog['comments_count'] # 评论数量
attitudes_count = mblog['attitudes_count'] # 点赞数量
with open(name, 'a', encoding='utf-8') as f:
f.write("----第" + str(page) + "页,第" + str(i + 1) + "条微博----" + "\n")
f.write("微博地址:" + str(scheme) + "\n" + "发布时间:" + str(create_time) + "\n"
+ "微博内容:" + mblog_text + "\n" + "点赞数:" + str(attitudes_count) + "\n"
+ "评论数:" + str(comments_count) + "\n" + "转发数:" + str(reposts_count) + "\n")
blog_dict['mblog_id'] = mblog_id
blog_dict['mblog_text'] = mblog_text
blog_dict['create_time'] = create_time
return blog_dict
else:
print("没有任何微博哦")
return False
函数参数:
第一个参数,接受的值为 res['data']['cards'] 的返回值,是一个字典类型数据
第二个参数,是外层调用函数的循环计数器
第三个参数,是要爬取的大 V 名称
第四个参数,是正在爬取的页码
最后函数返回一个字典
搜索微博信息
我们还要实现通过微博的一些文字片段,来定位到某个微博,从而抓取该微博下的评论的功能。
再定义一个函数,调用上面的 get_blog_info 函数,从其返回的字典中拿到对应的微博信息,再和需要比对的我们输入的微博字段做比较,如果包含,那么就说明找到我们要的微博啦
def get_blog_by_text(containerid, blog_text, name):
blog_list = []
page = 1
while True:
try:
url = 'https://m.weibo.cn/api/container/getIndex?containerid=%s&page=%s' % (containerid, page)
res_code = requests.get(url).status_code
if res_code == 418:
print("访问太频繁,过会再试试吧")
return False
res = requests.get(url).json()
cards = res['data']['cards']
if len(cards) > 0:
for i in range(len(cards)):
print("-----正在爬取第" + str(page) + "页,第" + str(i+1) + "条微博------")
blog_dict = get_blog_info(cards, i, name, page)
blog_list.append(blog_dict)
if blog_list is False:
break
mblog_text = blog_dict['mblog_text']
create_time = blog_dict['create_time']
if blog_text in mblog_text:
print("找到相关微博")
return blog_dict['mblog_id']
elif checkTime(create_time, config.day) is False:
print("没有找到相关微博")
return blog_list
page += 1
time.sleep(config.sleep_time)
else:
print("没有任何微博哦")
break except:
pass
代码虽然看起来比较长,但是其实都是已经学习过的知识。
唯一需要说明的就是有一个 checkTime 函数和 config 配置文件
checkTime 函数定义如下
def checkTime(inputtime, day):
try:
intime = datetime.datetime.strptime("2019-" + inputtime, '%Y-%m-%d')
except:
return "时间转换失败" now = datetime.datetime.now()
n_days = now - intime
days = n_days.days
if days < day:
return True
else:
return False
定义这个函数的目的是为了限制搜索时间,比如对于 90 天以前的微博,就不再搜索了,也是提高效率。
而 config 配置文件里,则定义了一个配置项 day,来控制可以搜索的时间范围
day = 90 # 最久抓取的微博时间,60即为只抓取两个月前到现在的微博
sleep_time = 5 # 延迟时间,建议配置5-10s
获取评论信息
对于评论信息,和前面小试牛刀里的方法是一样的,就不再重复了
def get_comment(self, mblog_id, page):
comment = []
for i in range(0, page):
print("-----正在爬取第" + str(i) + "页评论")
url = 'https://weibo.com/aj/v6/comment/big?ajwvr=6&id=%s&page=%s' % (mblog_id, i)
req = requests.get(url, headers=self.headers).text
html = json.loads(req)['data']['html']
content = BeautifulSoup(html, "html.parser")
comment_text = content.find_all('div', attrs={'class': 'WB_text'})
for c in comment_text:
_text = c.text.split(":")[1]
comment.append(_text)
time.sleep(config.sleep_time) return commentdef download_comment(self, comment):
comment_pd = pd.DataFrame(columns=['comment'], data=comment)
timestamp = str(int(time.time()))
comment_pd.to_csv(timestamp + 'comment.csv', encoding='utf-8')
定义运行函数
最后,我们开始定义运行函数,把需要用户输入的相关信息都从运行函数中获取并传递给后面的逻辑函数中。
from weibo_spider import WeiBo
from config import headers
def main(name, spider_type, text, page, iscomment, comment_page):
print("开始...")
weibo = WeiBo(name, headers)
print("以名字搜索...")
print("获取 UID...")
uid = weibo.get_uid()
print("获取 UID 结束")
print("获取用户信息...")
userinfo = weibo.get_userinfo(uid)
print("获取用户信息结束")
if spider_type == "Text" or spider_type == "text":
print("爬取微博...")
blog_info = weibo.get_blog_by_text(userinfo['containerid'], text, name)
if isinstance(blog_info, str):
print("搜索到微博,爬取成功")
if iscomment == "Yes" or iscomment == "YES" or iscomment == "yes":
print("现在爬取评论")
comment_info = weibo.get_comment(blog_info, comment_page)
weibo.download_comment(comment_info)
print("评论爬取成功,请查看文件")
return True
return True
else:
print("没有搜索到微博,爬取结束")
return False
elif spider_type == "Page" or spider_type == "page":
blog_info = weibo.get_blog_by_page(userinfo['containerid'], page, name)
if blog_info and len(blog_info) > 0:
print("爬取成功,请查看文件")
return True
else:
print("请输入正确选项")
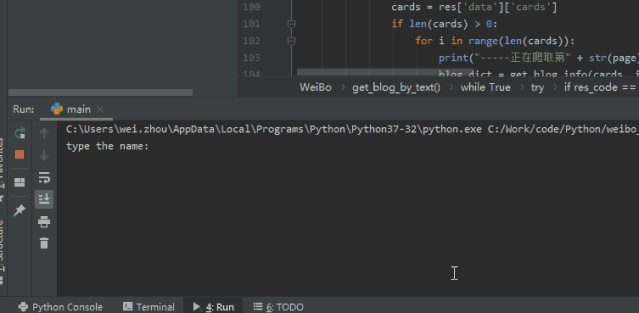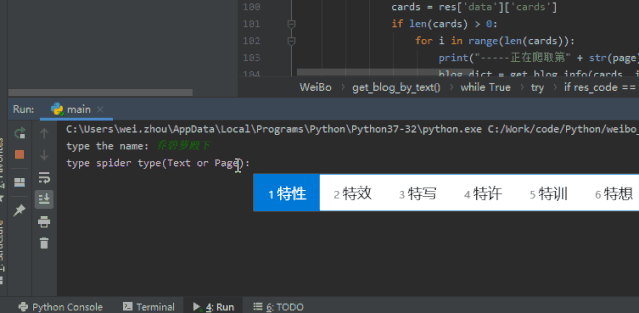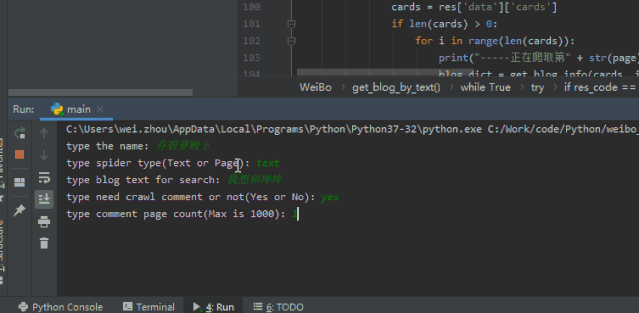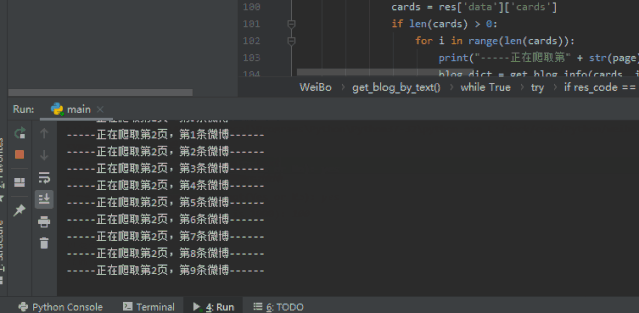
return Falseif __name__ == '__main__':
target_name = input("type the name: ")
spider_type = input("type spider type(Text or Page): ")
text = "你好"
page_count = 10
iscomment = "No"
comment_page_count = 100
while spider_type not in ("Text", "text", "Page", "page"):
spider_type = input("type spider type(Text or Page): ")
if spider_type == "Page" or spider_type == "page":
page_count = input("type page count(Max is 50): ")
while int(page_count) > 50:
page_count = input("type page count(Max is 50): ")
elif spider_type == "Text" or spider_type == "text":
text = input("type blog text for search: ")
iscomment = input("type need crawl comment or not(Yes or No): ")
while iscomment not in ("Yes", "YES", "yes", "No", "NO", "no"):
iscomment = input("type need crawl comment or not(Yes or No): ")
if iscomment == "Yes" or iscomment == "YES" or iscomment == "yes":
comment_page_count = input("type comment page count(Max is 1000): ")
while int(comment_page_count) > 1000:
comment_page_count = input("type comment page count(Max is 1000): ")
result = main(target_name, spider_type, text, int(page_count), iscomment, int(comment_page_count))
if result:
print("爬取成功!!")
else:
print("爬取失败!!")
虽然代码比较长,但是大部分都是逻辑的判断,并不难。
唯一的知识点就是输入函数 input(),它提供一个阻塞进程,只有当用户按下回车键之后,才会继续执行后面的代码。
你应该注意到了这句代码
weibo = WeiBo(name, headers)
这里是把前面一系列的函数都封装到了 WeiBo 这个类中,就是面向对象的思维了。
爬虫类与工具集
我们来看下爬虫类 WeiBo 是如何定义的
class WeiBo(object): def __init__(self, name, headers):
self.name = name
self.headers = headers
def get_uid(self): # 获取用户的 UID
... def get_userinfo(self, uid): # 获取用户信息,包括 containerid
... def get_blog_by_page(self, containerid, page, name): # 获取 page 页的微博信息
... def get_blog_by_text(self, containerid, blog_text, name): # 一个简单的搜索功能,根据输入的内容查找对应的微博
... def get_comment(self, mblog_id, page): # 与上个函数配合使用,用于获取某个微博的评论
... def download_comment(self, comment): # 下载评论
...在类的初始化函数中,传入需要爬取的大 V 名称和我们准备好的 headers(cookie),然后把上面写好的函数写到该类下,后面该类的实例 weibo 就能够调用这些函数了。
对于工具集,就是抽象出来的一些逻辑处理,我们也都讲解过
import datetime
from config import daydef checkTime(inputtime, day):
. ...def get_blog_info(cards, i, name, page):
...
好了,至此,你就可以愉快的运行爬虫了,然后喝杯茶,慢慢的等着程序运行完毕即可。
我们看一下最终的成果
是不是有些许的满足感呢!
完整的代码戳这里:
小试牛刀
https://github.com/zhouwei713/DataAnalyse/tree/master/weibo_spider
自动爬微博
https://github.com/zhouwei713/DataAnalyse/tree/master/auto_weibo_spider
总结
今天我以微博爬虫为例,全面的讲解了如何分析网页,如何应对反爬虫,如何使用 M 站等技能。相信通读完今天的课程,你应该已经可以胜任一些简单的爬虫工作了,是不是已经蠢蠢欲动了呢。