
【深度学习】ICPR 2022|3DUNet:卷积+胶囊强强联手,医学图像分割的新良方
导读
卷积神经网络(CNN)目前在医学图像分割领域应用广泛。本文基于胶囊网络,设计了一种包含卷积与胶囊编码器的3DUNet架构并应用于医学图像分割,在减少推理时间的同时性能远优于以往UNet类架构。

论文地址:https://arxiv.org/abs/2205.09299
一、为什么要引入胶囊网络(Capsule Network)?
当MIS遇见CNN,火花最多的便是各种各样的UNet架构变体,然而:
CNN中的池化会丢失一部分空间信息(可以理解为池化操作后原来多个规律分布的特征值变为一个特征值,不仅特征表达量减少,且原特征值之间相对位置关系被打破)。 CNN对旋转和仿射变换敏感(CNN拥有良好的平移不变性,但若对象发生旋转,则原已训练好的权重矩阵将不再完美适用,此时要么人为干预数据,要么让CNN继续学习这种旋转不变性)。
有趣的是,这些问题都可以被胶囊网络所解决。尽管此前也有不少工作将胶囊网络与卷积相结合并应用于MSI领域,但或多或少都存在一些缺点:比如推断过程耗时长、2D的胶囊网络应用于含时间维度的3D数据时表现不佳、高度依赖于一些随机现象(如权重初始化)等等。
而本文基于3D-UCaps(MICCAI 2021)取得的巨大成功,也提出一种胶囊与卷积结合的3DUnet架构,称之为3DConvCaps。旨在通过胶囊网络获得对局部-整体关系的更好表达同时减少其推理时间。
二、胶囊网络预热
胶囊网络的概念始于2011年,正式提出并应用于2017年(详见论文:Dynamic Routing Between Capsules)。鉴于此前已有大量文献资料对胶囊网络进行了详细的分析与解读,此处仅作简要介绍:
胶囊网络与卷积神经网络的最大不同在于输出类型。前者为一组向量,向量中可以包含对目标的各种维度描述(见图1),如检测鸟时可分为:体型大小、羽毛颜色、鸟喙长度等等;而后者仅为对应特征值,该值即代表该鸟类。
PS:胶囊网络中这种对目标不同维度的表达与计算,可视为对目标进行部分-整体关系编码。也正是这种关系编码的存在,使得胶囊网络具备下述优势2。

一张32×32大小的特征图中,卷积神经网络仅仅包含32×32个特征点,然而胶囊网络则包含32×32组向量。
由于胶囊网络的向量形式,当目标发生旋转或放射变换时,向量仅需改变长度或角度即可适应这种变换。而卷积神经网络则没有这种特性(尽管对于分类任务来说似乎并不影响)。
因此当训练过程进行时,卷积神经网络在不断调整权重矩阵,以得到更有效的特征输出。而胶囊网络则不断更新每个向量的模长或角度。(值得注意的是,胶囊网络中,因为模长代表目标存在于对应位置的概率,故其值将不超过1)
另外胶囊网络还具有以下优势及缺点:
需求更少的训练数据但训练较为缓慢(归咎于原论文中的“routing by agreement”算法)。 非常适用于处理密集/拥挤的场景但较难识别靠得近且类型相同的目标(如检测人眼睛和鼻子非常轻松,但检测左眼和右眼则不容易)。
三、3DConvCaps剖析
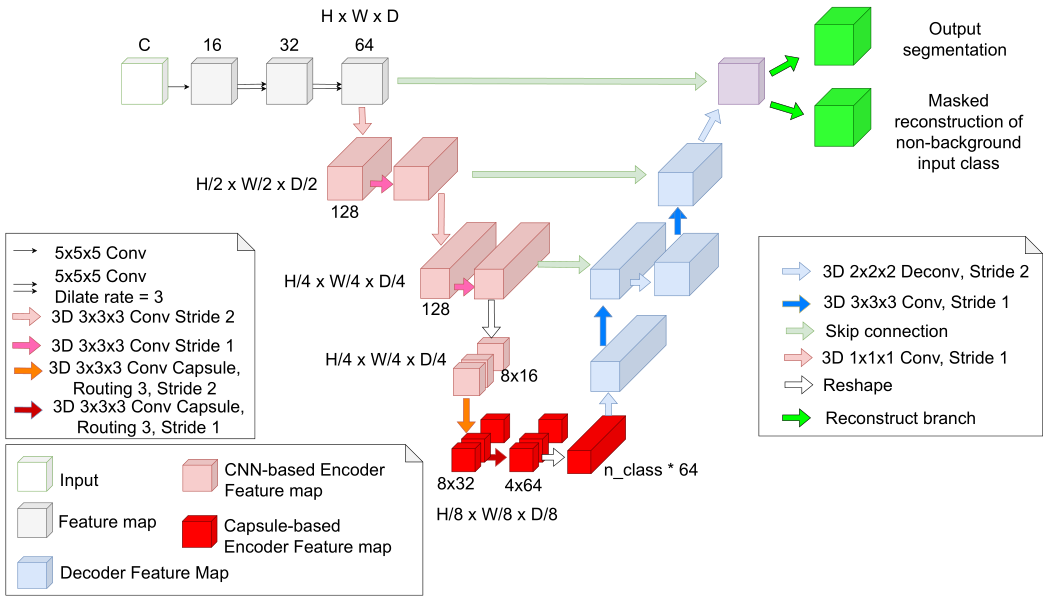
如图2所示,3DConvCaps包含三个部分:视觉特征提取部分、ConvCaps特征编码器和Conv解码器。
图中左上角的白色方块部分即为视觉特征提取部分,由简单的5×5卷积组成,其扩张率分别为{1, 3, 3}。最后在进入编码器前的特征图尺寸为H×W×D×64。
编码器进一步提取特征,然而浅层特征捕捉到的多为短距离信息,因此作者等人首先使用卷积块来提取低级特征,再用胶囊层来捕获长距离信息(部分与整体的长距离依赖)。
在进入胶囊编码层前,特征图的尺寸被reshape为。在第一个胶囊层中,胶囊类型的数量为(8, 8),即8个尺寸为8的胶囊。而在最后一个胶囊层中,含有4个尺寸为64的胶囊。
进入解码器前最后一个胶囊层的输出被reshape为n_class,其值即为4.作者等人为了通过margin loss对模型进行监督学习,最后一个胶囊层中的胶囊类型数量等于分割中的类别数量。
在思考这部分方法的同时,笔者试着解释为什么浅层特征要使用卷积而非直接的胶囊层。却发现以“卷积层→初级胶囊层→分类胶囊层”为结构似乎是一个公认的既定事实。卷积层用于特征提取,同时为胶囊层生成合适的尺寸或通道。而在胶囊层中,利用一定的胶囊数来组合前一层的特征,继而进行相关计算。
同时在本文中,仅在网络最下面(即特征图相对最小)时使用胶囊层,一方面可相对减少参数量计算量,另一方面在解码时可不使用该层而只使用卷积层。这样相比以往的3D-UCaps可更显轻量化。
四、性能对比
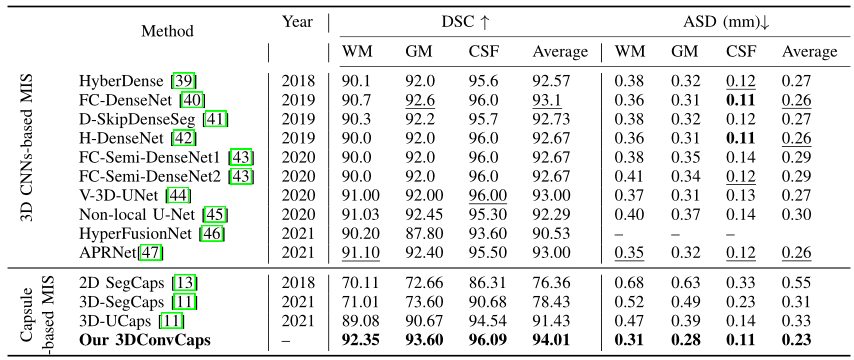
如表1,本文方法在于过往应用于医学图像分割领域的胶囊网络相比较,性能表现出大幅度提升。
然而本文方法在细节部分也看重实际推理速度(如胶囊层不参与解码、仅在网络底部使用胶囊层),因此作者等人对模型推理速度进行对比测试,结果如下:

可见本文方法即使略逊色于纯卷积的3D-Unet,也远优于过往含胶囊网络的SOTA模型。
五、思考与总结
阅读完这篇文章,有些意犹未尽。胶囊网络具有诸多良好优点,其中最重要的,契合与医学图像分割的便是其向量的表示,可以很好的建模局部-整体关系。同时由于这种向量的表达,使得胶囊网络仅需在训练过程中找到合适的胶囊从而生成有用的预测即可,而不是像卷积神经网络那样去“记住”目标的特征形式。这也是为什么胶囊网络更适合训练较少的数据,当数据集过大反而性能下降的原因。
利用卷积去捕获局部特征,利用胶囊去捕获局部-整体关系。这样的思想在很多方法中都可以见到类似的影子,如MaxViT中利用Block Attention捕获局部信息,利用Grid Attention捕获全局信息;还有百度提出的MixFormer等等。
而在3DConvCaps是否可以将卷积与胶囊更好的结合甚至是融合值得思考,作者等人则希望在未来能进一步分析实际应用中3DConvCaps应对各种变换的鲁棒性。
最后也期待能尽早看到本文的开源代码,作为MIS领域中含胶囊操作的SOTA模型,一定有很多地方值得去学习和借鉴~
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码