
树+神经网络算法强强联手(Python)
结合论文《Revisiting Deep Learning Models for Tabular Data》的观点,集成树模型通常擅长于表格数据这种异构数据集,是实打实的表格数据王者。
集成树模型中的LightGBM是增强版的GBDT,支持了分类变量,在工程层面大大提高了训练效率。关于树模型的介绍,可见之前文章:一文讲透树模型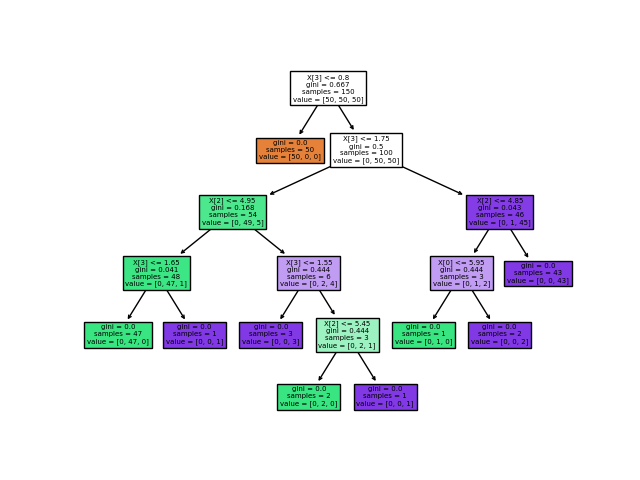
DNN深度神经网络擅长于同构的高维数据,从高维稀疏的表示中学习到低维致密的分布式表示,所以在自然语言、图像识别等领域基本上是称霸武林(神经网络的介绍及实践可见系列文章:一文搞定深度学习建模全流程)。对于异构致密的表格数据,个人实践来看,DNN模型的非线性能力没树模型来得高效。
所以一个很朴素的想法是,结合这树模型+神经网络模型的优势。比如通过NN学习文本的嵌入特征后,输入树模型继续学习(如word2vec+LGB做文本分类,可见文章:NLP建模全流程)。或者是,树模型学习表格数据后,输出样本的高维个叶子节点的特征表示,输入DNN模型。
接下来,我们使用LightGBM+DNN模型强强联手,验证其在信贷违约的表格数据预测分类效果。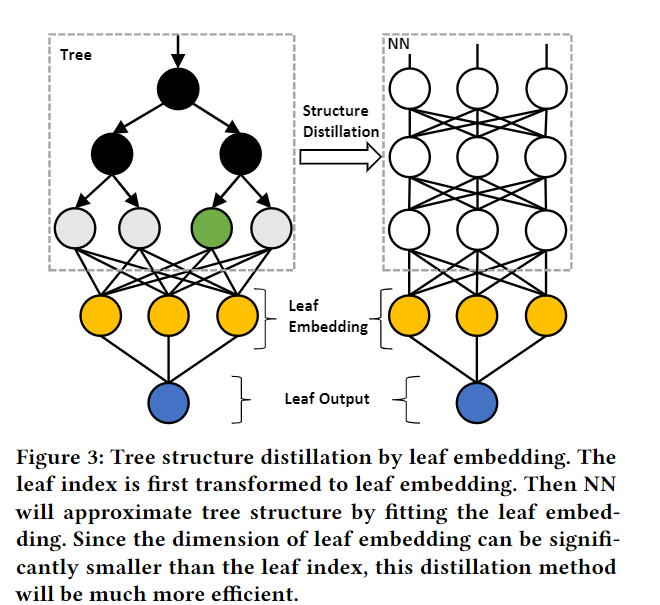
数据处理及树模型训练
lightgbm树模型,自带缺失、类别变量的处理,还有很强的非线性拟合能力,特征工程上面不用做很多处理,建模非常方便。
##完整代码及数据请见 算法进阶github:https://github.com/aialgorithm/Blog
# 划分数据集:训练集和测试集
train_x, test_x, train_y, test_y = train_test_split(train_bank[num_feas + cate_feas], train_bank.isDefault,test_size=0.3, random_state=0)
# 训练模型
lgb=lightgbm.LGBMClassifier(n_estimators=5, num_leaves=5,class_weight= 'balanced',metric = 'AUC')
lgb.fit(train_x, train_y)
print('train ',model_metrics(lgb,train_x, train_y))
print('test ',model_metrics(lgb,test_x,test_y))
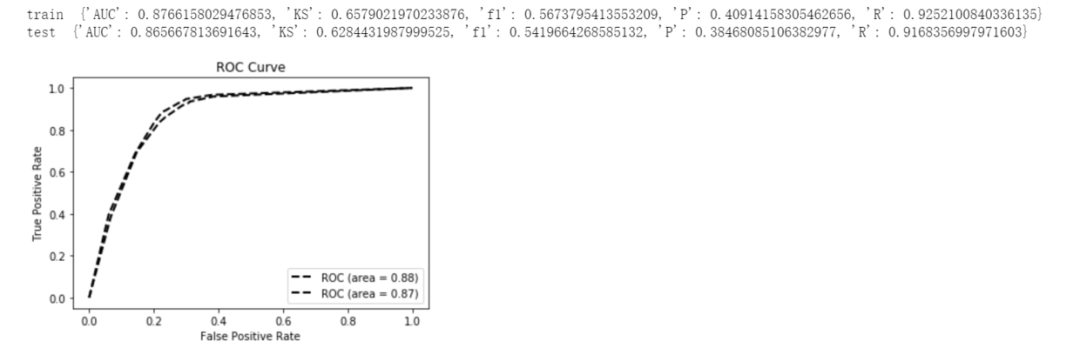 简单处理建模后test的AUC可以达到0.8656
简单处理建模后test的AUC可以达到0.8656
树+神经网络
接下来我们将提取树模型的叶子节点的路径作为特征,并简单做下特征选择处理
import numpy as np
y_pred = lgb.predict(train_bank[num_feas + cate_feas],pred_leaf=True)
# 提取叶子节点
train_matrix = np.zeros([len(y_pred), len(y_pred[0])*lgb.get_params()['num_leaves']],dtype=np.int64)
print(train_matrix.shape)
for i in range(len(y_pred)):
temp = np.arange(len(y_pred[0]))*lgb.get_params()['num_leaves'] + np.array(y_pred[i])
train_matrix[i][temp] += 1
# drop zero-features
df2 = pd.DataFrame(train_matrix)
droplist2 = []
for k in df2.columns:
if not df2[k].any():
droplist2.append(k)
print(len(droplist2))
df2= df2.drop(droplist2,axis=1).add_suffix('_lgb')
# 拼接原特征和树节点特征
df_final2 = pd.concat([train_bank[num_feas],df2],axis=1)
df_final2.head()

将拼接好原特征及树节点路径特征输入神经网络模型,并使用网格搜索调优神经网络模型。
# 划分数据集:训练集和测试集
train_x, test_x, train_y, test_y = train_test_split(df_final2, train_bank.isDefault,test_size=0.3, random_state=0)
# 神经网络模型评估
def model_metrics2(nnmodel, x, y):
yprob = nnmodel.predict(x.replace([np.inf, -np.inf], np.nan).fillna(0))[:,0]
fpr,tpr,_ = roc_curve(y, yprob,pos_label=1)
return auc(fpr, tpr),max(tpr-fpr)
import keras
from keras import regularizers
from keras.layers import Dense,Dropout,BatchNormalization,GaussianNoise
from keras.models import Sequential, Model
from keras.callbacks import EarlyStopping
from sklearn.metrics import mean_squared_error
np.random.seed(1) # 固定随机种子,使每次运行结果固定
bestval = 0
# 创建神经模型并暴力搜索较优网络结构超参: 输入层; n层k个神经元的relu隐藏层; 输出层
for layer_nums in range(2): #隐藏层的层数
for k in list(range(1,100,5)): # 网格神经元数
for norm in [0.01,0.05,0.1,0.2,0.4,0.6,0.8]:#正则化惩罚系数
print("************隐藏层vs神经元数vs norm**************",layer_nums,k,norm)
model = Sequential()
model.add(BatchNormalization()) # 输入层 批标准化 input_dim=train_x.shape
for _ in range(layer_nums):
model.add(Dense(k,
kernel_initializer='random_uniform', # 均匀初始化
activation='relu', # relu激活函数
kernel_regularizer=regularizers.l1_l2(l1=norm, l2=norm), # L1及L2 正则项
use_bias=True)) # 隐藏层1
model.add(Dropout(norm)) # dropout正则
model.add(Dense(1,use_bias=True,activation='sigmoid')) # 输出层
# 编译模型:优化目标为回归预测损失mse,优化算法为adam
model.compile(optimizer='adam', loss=keras.losses.binary_crossentropy)
# 训练模型
history = model.fit(train_x.replace([np.inf, -np.inf], np.nan).fillna(0),
train_y,
epochs=1000, # 训练迭代次数
batch_size=1000, # 每epoch采样的batch大小
validation_data=(test_x.replace([np.inf, -np.inf], np.nan).fillna(0),test_y), # 从训练集再拆分验证集,作为早停的衡量指标
callbacks=[EarlyStopping(monitor='val_loss', patience=10)], #早停法
verbose=False) # 不输出过程
print("验证集最优结果:",min(history.history['loss']),min(history.history['val_loss']))
print('------------train------------\n',model_metrics2(model, train_x,train_y))
print('------------test------------\n',model_metrics2(model, test_x,test_y))
test_auc = model_metrics2(model, test_x,test_y)[0]
if test_auc > bestval:
bestval = test_auc
bestparas = ['bestval, layer_nums, k, norm',bestval, layer_nums, k, norm]
# 模型评估:拟合效果
plt.plot(history.history['loss'],c='blue') # 蓝色线训练集损失
plt.plot(history.history['val_loss'],c='red') # 红色线验证集损失
plt.show()
model.summary() #模型概述信息
print(bestparas)


在我们这个实验中,使用树模型+神经网络模型在test的auc得到一些不错的提升,树模型的AUC 0.8656,而树模型+神经网络的AUC 0.8776,提升了1.2%
其他试验结果
结合微软的试验,树+神经网络(DeepGBM),在不同的任务上也是可以带来一些的效果提升的。有兴趣可以阅读下文末参考文献。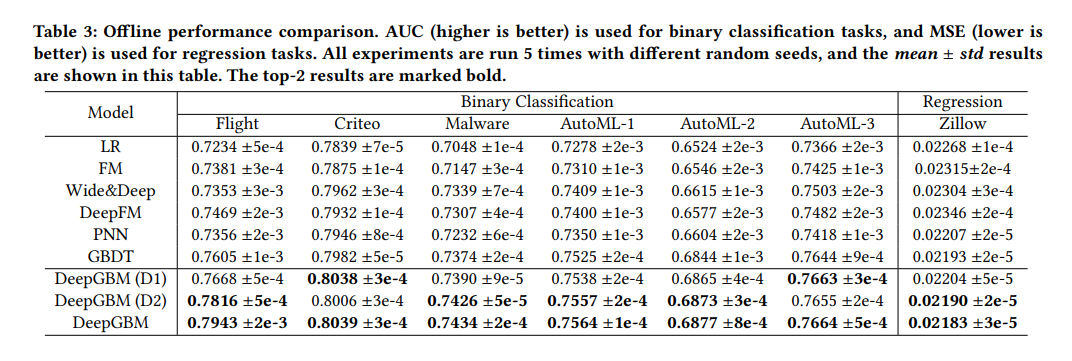
LGB+DNN(或者单层的LR)是一个很不错的想法,有提升模型的一些效果。但需要注意的是,这也会加重模型的落地及迭代的复杂度。综合来看,树+神经网络是一个好的故事,但是结局没有太惊艳。
- END -参考论文:https://www.microsoft.com/en-us/research/uploads/prod/2019/08/deepgbm_kdd2019__CR_.pdf
https://github.com/motefly/DeepGBM