
Transformer一作又出新作!HaloNet:用Self-Attention的方式进行卷积

极市导读
本文是谷歌团队Transformer的一作Ashish Vaswani 又一篇以一作身份发表的论文,也是今年CVPR的Oral文章。作者提出了HaloNet,并在多个任务上做了实验,证明了其有效性。HaloNet在ImageNet上达到了84.9%的top-1准确率,在目标检测和实力分割任务中也取得了不错的效果。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
写在前面
1. 论文和代码地址
2. Motivation
3. 方法
3.1. CNN和SA的滤波器
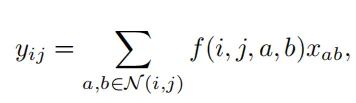
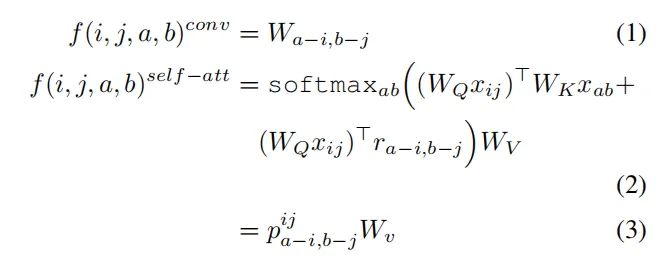
3.2.Block Self-Attention
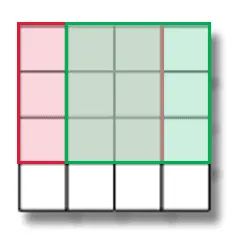
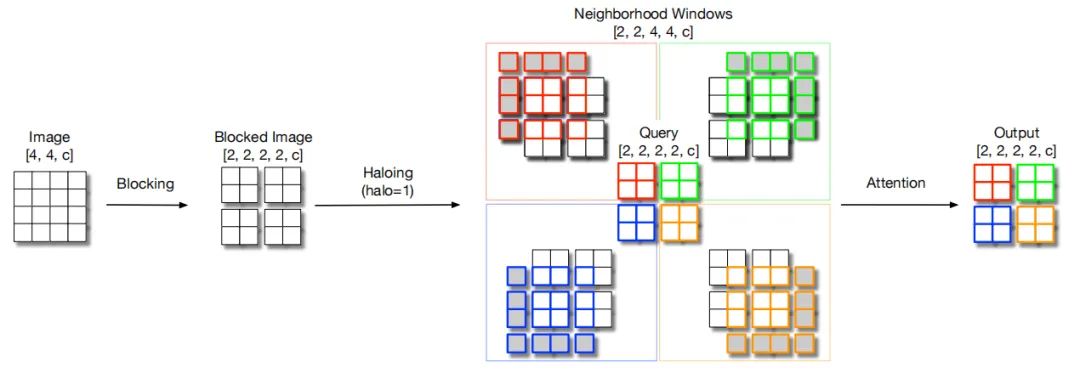

3.3. Downsampling
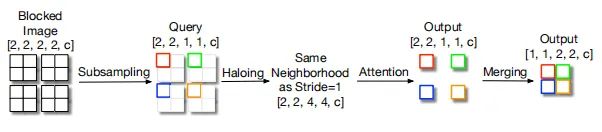
3.4. HaloNet

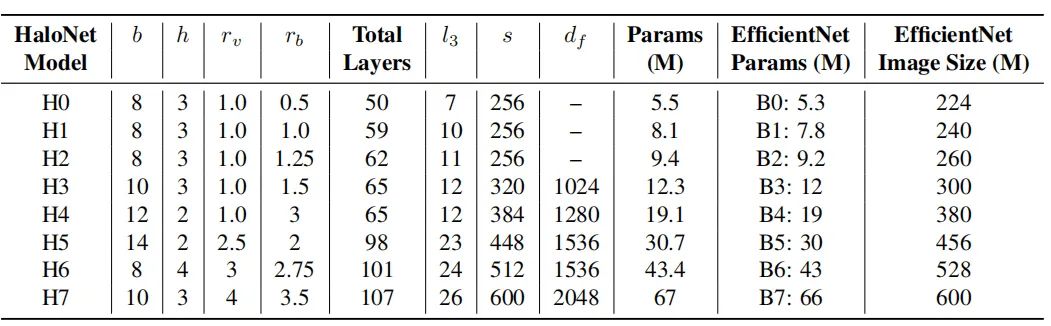
4.实验
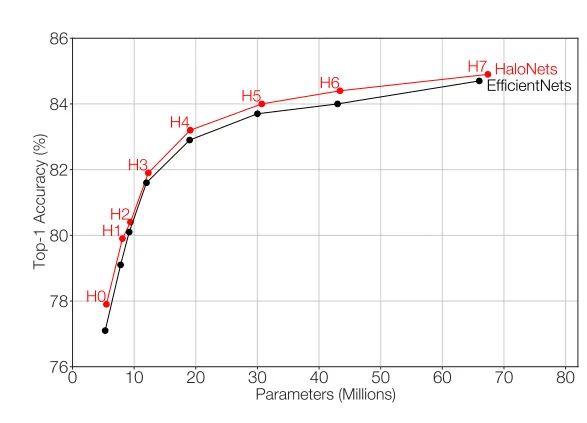
4.1. 分类任务
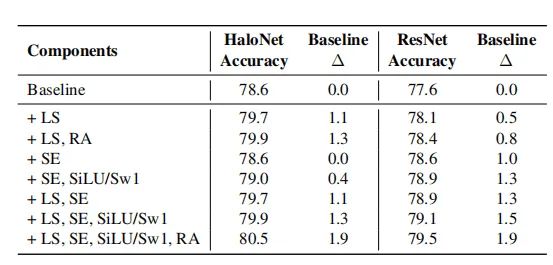
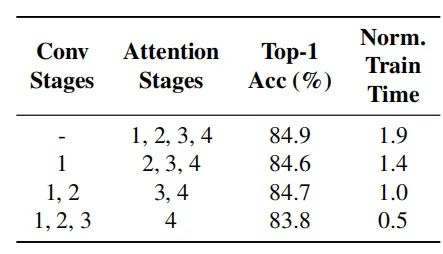
4.2. 卷积结构对于SA的影响
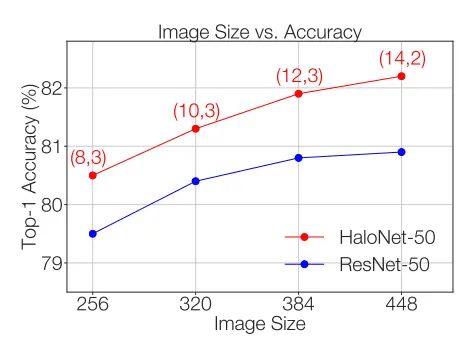
4.3. 图片大小的影响
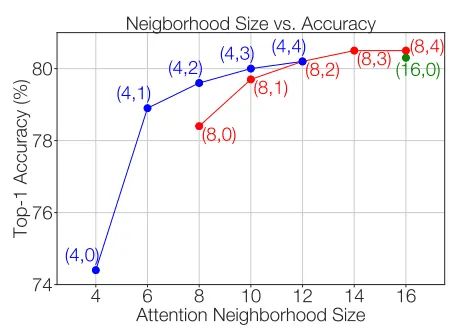
4.4. Window size和Halo Size的影响
4.5. 卷积和SA的 速度-精度 tradeoff
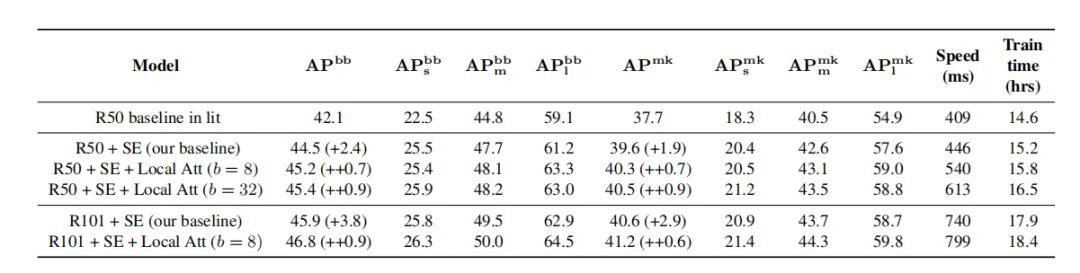
4.6. 目标检测和实例分割的结果
5. 总结
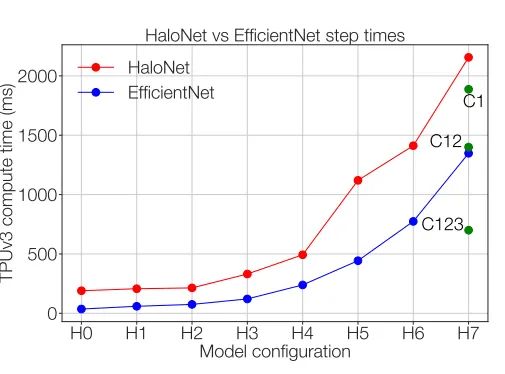
参考文献
Bello, Anselm Levskaya, and Jon Shlens. Stand-alone selfattention in vision models. In H. Wallach, H. Larochelle, A.
Beygelzimer, F. d’Alché Buc, E. Fox, and R. Garnett, editors,
Advances in Neural Information Processing Systems 32, pages
68–80. Curran Associates, Inc., 2019.
本文亮点总结
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“调研报告”获取《2020年度中国计算机视觉人才调研报告》~

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~

评论