
超详解!Transformer + self-attention
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达

最近刚开始阅读transformer文献感觉有一些晦涩,尤其是关于其中Q、K、V的理解,故在这里记录自己的阅读心得,供于分享交流
一、self-attention部分预热
1.1 计算顺序
首先了解NLP中self-attention计算顺序:

1.2 计算公式详解
有些突兀,不着急,接下来我们看看self-attention的公式长什么样子:
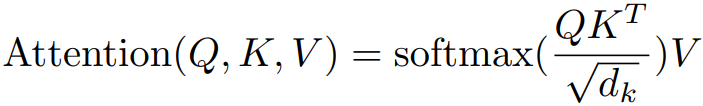 公式1
公式1此公式在论文《attention is all your need》中出现,抛开Q、K、V与dk不看,则最开始的self-attention注意力计算公式为:
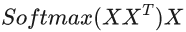 公式2
公式2两公式对比可以发现,Q、K、V都是由输入词X(词向量)经过某种变换所得,向量与转置后的向量相乘,我们可以看做向量与转置后得到的矩阵空间中每一个子向量做点积运算,即向量内积
值得注意的是:我们输入的只是一串字符,这里要把每个词转成我们后续可以进行操作的词向量,需要进行embedding操作,可以理解为把一个词如love转换为对应的语义信息如【1, 3, 0, 5】,当然为了获取词在输入序列中的位置信息,我们在后续的transformer中增加了对应词的位置信息(positional encoding)
内积(点乘)的几何意义包括:
表征或计算两个向量之间的夹角
a向量在b向量方向上的投影
两向量相乘得一新的向量,即A*B=C,那么这个新的向量C就在一定个程度上代表向量A对向量B的投影度大小
换个角度思考,投影度大小即输入序列中对应词与词的相关度,投影度越大(夹角越小),意味着在一定程度上两个词之间的相关度越大(词向量是文本形式的词在高维空间(抽象化)的数值形式映射)
至此公式2中的X*X^T理解完毕,那么对它进行softmax函数计算,即可得到我们想要的权重
值得注意的是:这里的权重过分关注于自身的位置,即对于X*X^T来说,最终的权重过分关注X对其他词向量的注意力而在一定程度上忽略了其他词,故在后续的transformer中作者采取了多头注意力机制来弥补
同时softmax函数还很好的使得权重和为1,我们只需将得到的权重乘以原来的X,即可得到最终的输出,这个输出经过了一次词与词之间相关度(也就是注意力)的计算,这也完成了一个self-attention的过程
现在让我们回到公式1:
Q、K、V究竟是何方神圣?在上文部分有提到:Q、K、V都是由原X经过某种变换所得到的,用图来表示的话,可以用下面这张图:
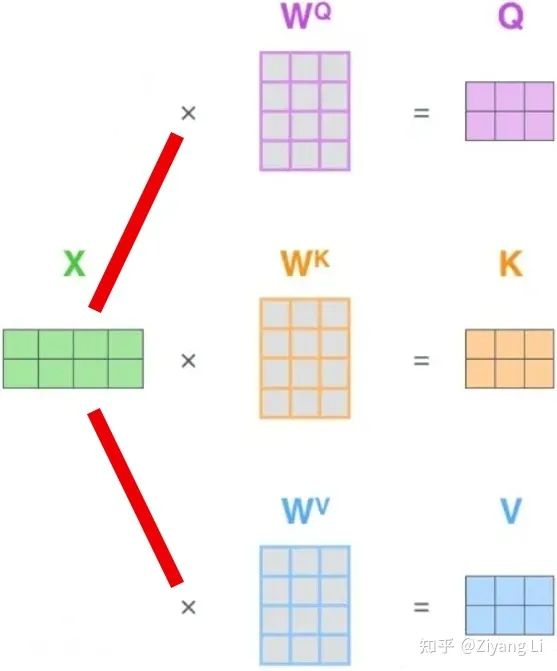
从图中不难看出,输入X乘以Q、K、V对应的W权值矩阵,就可以得到我们想要的Q、K、V
注意:此处的Q、K、V仅局限于后续Encoder和Decoder在各自输入部分的编码过程,Encoder和Decoder之间交互的Q、K和V并非此(后文会进行详细介绍)
补充:最开始的W权值矩阵需要初始化,在后续BP的过程中,W的具体数值会不断更新学习,这样做的好处不仅仅是可以提高模型的非线性程度,还能提高模型拟合能力,通过不断学习让注意力权值正确分布
公式中还在送入softmax前对权值矩阵乘以一个dk^(-1/2)(dk代表K的维度,同样的有dq、dv),这样做显然是对原权值矩阵做了一次缩放,这样做的意义是什么?
如果我们在计算X*X^T完毕后,矩阵中元素的方差很大,这就会使得softmax的分布变得极其陡峭,从而影响梯度稳定计算,此时我们进行一次缩放,再将方差缩放到1,softmax的分布变得平缓稳定起来,进而在之后的训练过程中保持梯度稳定。
至此self-attention的部分已经讲解完毕,接下来我们回到transformer中,一起来庖丁解牛。
二、Transformer部分
2.1 整体结构
首先来纵观transformer整体结构(左半部分是encode,右半部分是decode):
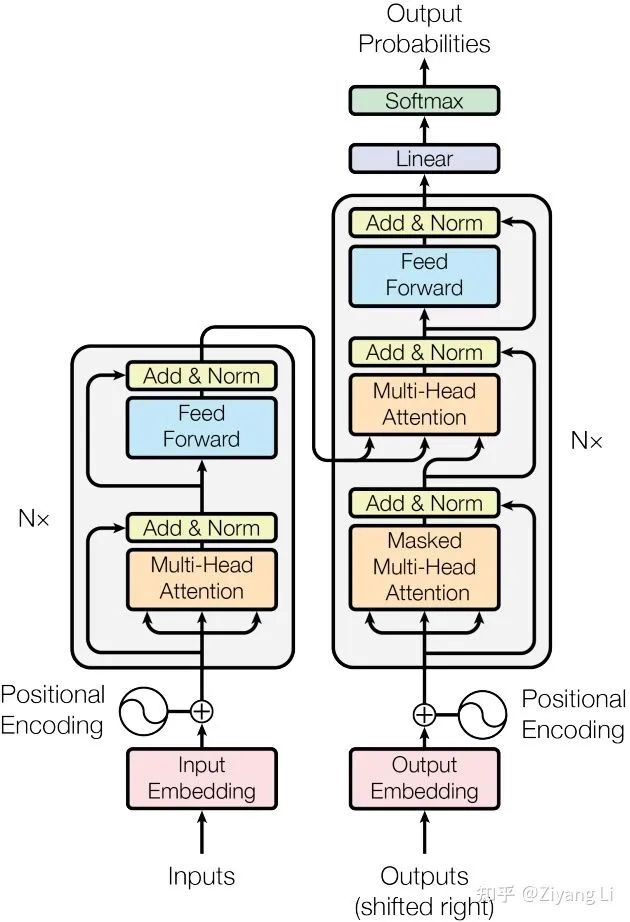 Transformer模型结构
Transformer模型结构2.2 encoder
首先分析左半部分,从下往上看inputs即为我们输入的字符串序列,此时在计算前我们要对输入序列进行如图所示的Input Embedding,此处即为上文self-attention中的语义信息转换,把输入的每个词转换为对应的词向量
同时transformer在embedding部分增加了位置编码,其位置计算公式为:
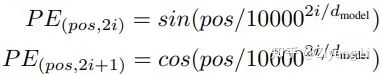
pos 指当前词在句子中的位置, 是指向量中每个值的 下标(索引);不难看出在偶数位置,使用正弦编码,在奇数位置,使用余弦编码;最终输出我们想要的位置向量
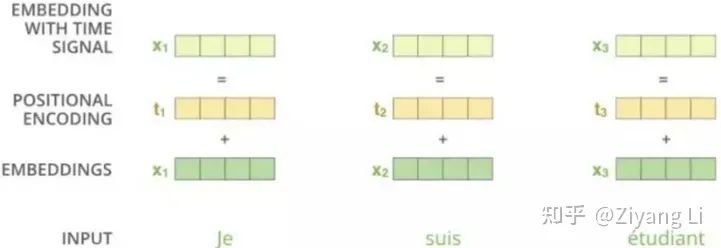
此处可以用一张图来表示:
接着回到transformer模型结构图,从左半部分继续向上看,来到了Encoder部分,左侧有一个 ×N 即多个encode叠加,右侧同理
顺着线路向上看,输入的一条路(一个词向量)分成三路(分别对应Q、K、V)进入了Multi-Head Attention层,同时输入的一条路增加了一个残差连接,通过简单的Add操作与Multi-Head Attention层相作用,同时在进入下一层前还进行BN层归一化
2.3 Multi-Head Attention层
那么接下来我们就一起解析Multi-Head Attention层,其具体结构如下:
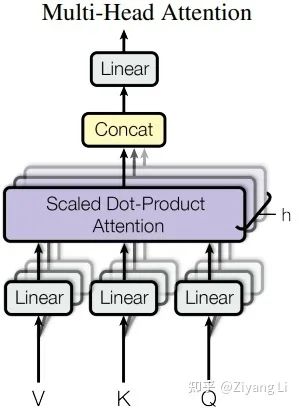
从图中可以看出Q、K、V首先经过了一个Linear层做线性变换,接着进入到了Scaled Dot-Product Attention层,接下来我们对Scaled Dot-Product Attention层展开详细分析:
对于Linear的理解,拿文中的话来说就是作者发现将Q、K、V经过一个线性层的学习是非常有益的
2.4 Scaled Dot-Product Attention层
先上图:
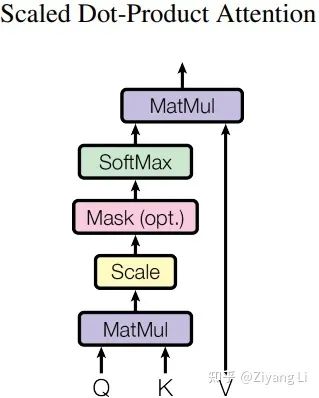
从下往上看,Q和K经过MatMul层做矩阵相乘(即上文self-attention部分提到的X*X^T),接着来到Scale层进行维度缩放(即上文self-attention部分提到的乘以dk^(-1/2))(注意这里的Mask是后续在decder部分需要使用的操作,encoder部分并没有,此层在这里跳过)。最终我们经过softmax得到的权值矩阵与V相乘,得到最终的输出。接着回到Multi-Head Attention图,我们可以看到在最终Linear输出前有h次同样的操作,那么这个h就对应着标题“多头”,h是几个头就是几个。
为什么要这样操作呢?
论文中提到这样的好处是可以允许模型在不同的表示子空间里学习到相关的信息。换个方式理解,我们可以类比CNN中同时使用多个滤波器的作用,我们想让模型学习全方位、多层次、多角度的信息,学习更丰富的信息特征,就要使用多头来完成。举个例子来说,我们在阅读文献的时候,总是对文献的摘要注意颇多,同时我们还对文献中的实验数据、实验结论想要有所了解,一般到最后才是文献的方法部分以及一些公式,这么一套流程下来我们对文献整体有了更丰富的掌握,那么“多头”即可类比于此(尽管有些许勉强)。
在Multi-Head Attention层得到最终的输出结果后,我们来到了Feed Forward层(见图4),同时还有一个一样的残差连接与层归一化处理。那么Feed Forward层的作用是什么呢?
细读文章可以发现,所谓Feed Forward即一个普通MLP结构,即全连接1 -> Relu -> dropout -> 全连接2,拿文中的公式表述为:
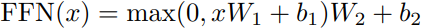
添加这一层的目的也是为了增加模型的非线性表达能力,提高模型拟合程度。
2.5 decoder
至此左半部分的encode讲解完毕,第N个encoder输出的K、V与decode部分进行交互,但我们先从decoder部分的下方输入开始看起(这里再把图拿过来):
从下往上看,Outputs是我们模型上一次的预测结果+shifted right,关于shifted right的讲解我们放在文末。输入的序列经过了和左半部分同样的操作,即语义信息编码+位置信息编码,但在分成三路后进入的却是一个Masked Multi-Head Attention,比左半部分多了一个Mask,那么接下来我们就详细分析一下这个Mask的具体内容:
2.6 Mask
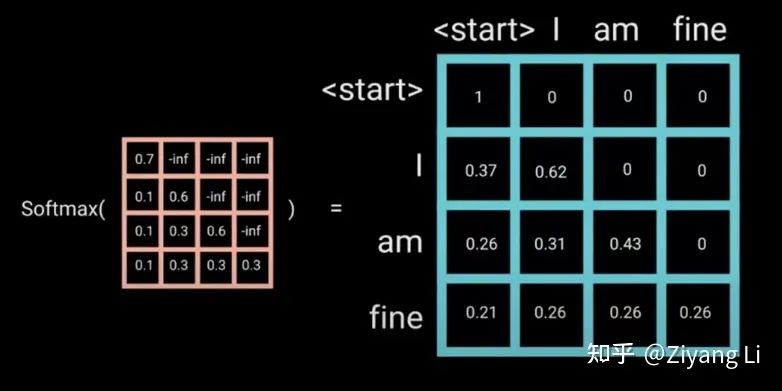
transformer的注意力计算我们已经熟悉,需要注意的是在训练阶段中,Decoder部分输入的数据是一整句,句中包含了等待被预测的后续的序列信息,我们不希望这样的情况发生,所以加入Mask操作来把那些不希望出现的信息掩盖
那么如何实现Mask?
只需要初始化一个下三角矩阵为0,上三角元素均为负无穷的矩阵加到注意力矩阵上,因为注意力需要经过softmax进行归一化,其中e^-  为0,因此可以将未来信息抹去。
为0,因此可以将未来信息抹去。

Masked Multi-Head Attention层的输出经过add&BN后与encoder部分输入的K、V交汇在一起,来到了一个和左半部分一样的Multi-Head Attention + Feed Forward层,decoder部分同样重复迭代N次,最终送入Linear层做最后的softmax计算,输出我们的预测值。
2.7 关于decoder的输入(包括shifted right)讲解:
一般训练阶段的Decoder第一次输入为起始符 + Positional Encoding,也可能是其他特殊的Token,目的是为了预测目标序列的第一个单词是什么。

我们将原输入序列中的对应词整体右移一位(shifted right),即得到了起始符+embedding的输入,对上图进行更为详细的描述,即:

由图中可以看出上文所述“Outputs是我们模型上一次的预测结果+shifted right”
三、The end
后期会对transformer代码进行详细的分析,笔者才学浅陋,初步接触机器学习,难免有诸多错误与遗漏,恳请广大读者不吝指教!
https://arxiv.org/pdf/1706.03762.pdf
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!