
【目标检测算法50篇速览】1、检测网络的出现
【GiantPandaCV导读】用深度学习网络来完成实际场景的检测任务已经是现在很多公司的常规做法了,但是检测网络是怎么来的,又是怎么一步步发展的呢?在检测网络不断迭代的过程中,学者们的改进都是基于什么思路提出并最终被证实其优越性的呢?
这个系列将从2013年RCNN开始,对检测网络发展过程中的50篇论文进行阅读,并尝试梳理检测网络的发展脉络。这个系列将按照以下安排梳理:
1、检测网络从出现到成为一个完整的端到端模型。
2、one stage 模型出现及two stage 的优化。
3、当前 anchor base检测算法的完整优化思路。
4、anchor free算法及检测的最新进展。
第一篇 RCNN
《Rich feature hierarchies for accurate object detection and semantic segmentation》
提出时间:2014年
针对问题:
从Alexnet提出后,作者等人思考如何利用卷积网络来完成检测任务,即输入一张图,实现图上目标的定位(目标在哪)和分类(目标是什么)两个目标,并最终完成了RCNN网络模型。
创新点:
RCNN提出时,检测网络的执行思路还是脱胎于分类网络。也就是深度学习部分仅完成输入图像块的分类工作。那么对检测任务来说如何完成目标的定位呢,作者采用的是Selective Search候选区域提取算法,来获得当前输入图上可能包含目标的不同图像块,再将图像块裁剪到固定的尺寸输入CNN网络来进行当前图像块类别的判断。下图为RCNN论文中的网络完整检测流程图。
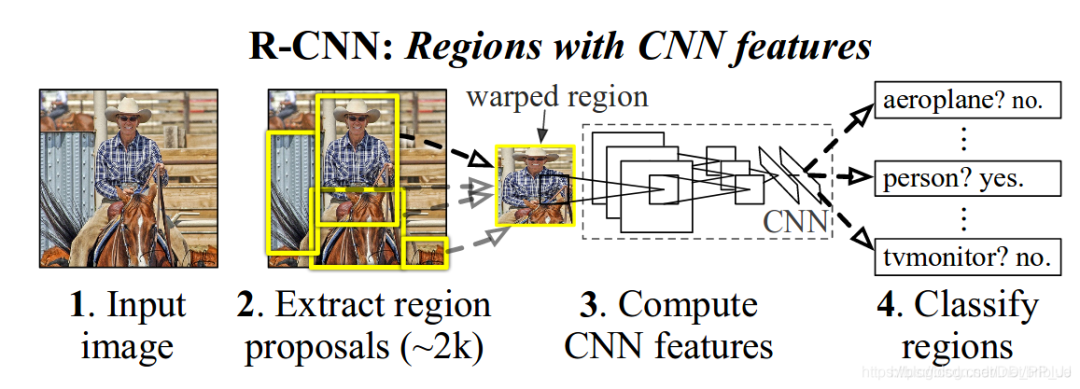
详解博客:https://blog.csdn.net/briblue/article/details/82012575。
第二篇 OverFeat
《OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks》
提出时间:2014年
针对问题:
该论文讨论了,CNN提取到的特征能够同时用于定位和分类两个任务。也就是在CNN提取到特征以后,在网络后端组织两组卷积或全连接层,一组用于实现定位,输出当前图像上目标的最小外接矩形框坐标,一组用于分类,输出当前图像上目标的类别信息。也是以此为起点,检测网络出现基础主干网络(backbone)+分类头或回归头(定位头)的网络设计模式雏形。
创新点:
在这篇论文中还有两个比较有意思的点,一是作者认为全连接层其实质实现的操作和1x1的卷积是类似的,而且用1x1的卷积核还可以避免FC对输入特征尺寸的限制,那用1x1卷积来替换FC层,是否可行呢?作者在测试时通过将全连接层替换为1x1卷积核证明是可行的;二是提出了offset max-pooling,也就是对池化层输入特征不能整除的情况,通过进行滑动池化并将不同的池化层传递给后续网络层来提高效果。如下为论文中的offset max-pooling示意图。
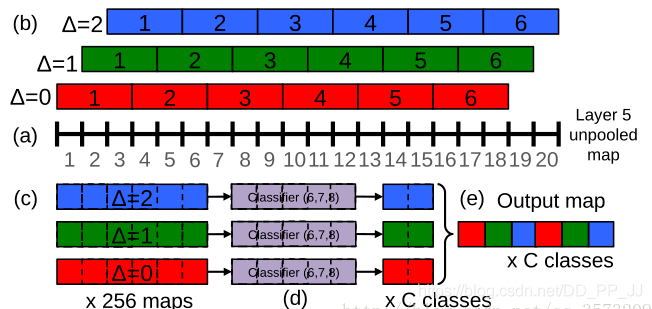
另外作者在论文里提到他的用法是先基于主干网络+分类头训练,然后切换分类头为回归头,再训练回归头的参数,最终完成整个网络的训练。图像的输入作者采用的是直接在输入图上利用卷积核划窗。然后在指定的每个网络层上回归目标的尺度和空间位置。
详解的博客:https://blog.csdn.net/qq_35732097/article/details/79027095
第三篇 MultiBox
《Scalable Object Detection using Deep Neural Networks》
提出时间:2014年multibox
针对问题:
既然CNN网络提取的特征可以直接用于检测任务(定位+分类),作者就尝试将目标框(可能包含目标的最小外包矩形框)提取任务放到CNN中进行。也就是直接通过网络完成输入图像上目标的定位工作。
创新点:
本文作者通过将物体检测问题定义为输出多个bounding box的回归问题. 同时每个bounding box会输出关于是否包含目标物体的置信度, 使得模型更加紧凑和高效。
先通过聚类获得图像中可能有目标的位置聚类中心,(800个anchor box)然后学习预测不考虑目标类别的二分类网络,背景or前景。用到了多尺度下的检测。
详解的博客:https://blog.csdn.net/m0_45962052/article/details/104845125
第四篇 DeepBox
《DeepBox: Learning Objectness with Convolutional Networks》
提出时间:2015年ICCV
主要针对和尝试解决问题:
本文完成的工作与第三篇类似,都是对目标框提取算法的优化方案,区别是本文首先采用自底而上的方案来提取图像上的疑似目标框,然后再利用CNN网络提取特征对目标框进行是否为前景区域的排序;而第三篇为直接利用CNN网络来回归图像上可能的目标位置。
创新点:
本文作者想通过CNN学习输入图像的特征,从而实现对输入网络目标框是否为真实目标的情况进行计算,量化每个输入框的包含目标的可能性值。
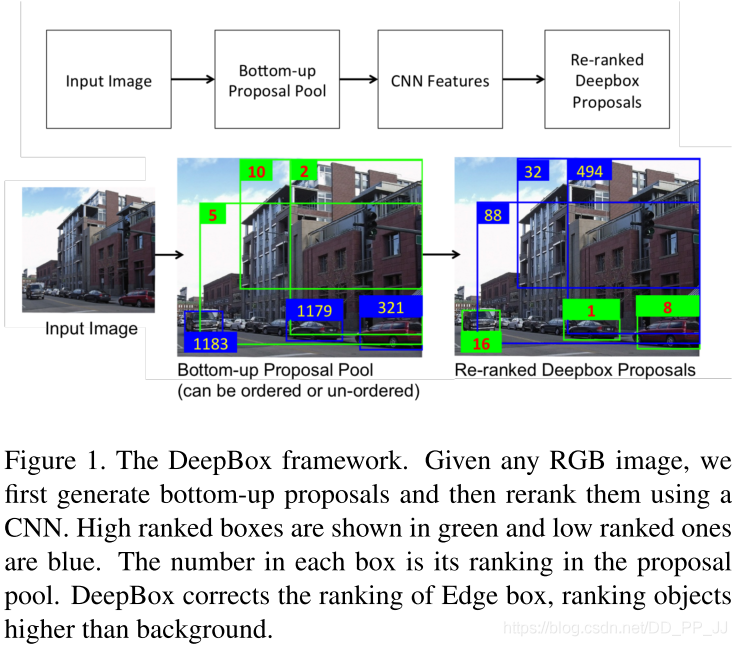
详解博客:https://www.cnblogs.com/zjutzz/p/8232740.html
第五篇 AttentionNet
AttentionNet: AggregatingWeak Directions for Accurate Object Detection》
提出时间:2015年ICCV
主要针对和尝试解决问题:
对检测网络的实现方案进行思考,之前的执行策略是,先确定输入图像中可能包含目标位置的矩形框,再对每个矩形框进行分类和回归从而确定目标的准确位置,参考RCNN。那么能否直接利用回归的思路从图像的四个角点,逐渐得到目标的最小外接矩形框和类别呢?
创新点:
通过从图像的四个角点,逐步迭代的方式,每次计算一个缩小的方向,并缩小指定的距离来使得逐渐逼近目标。作者还提出了针对多目标情况的处理方式。
详解博客:https://blog.csdn.net/m0_45962052/article/details/104945913
第六篇 SPPNet
《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》
提出时间:2014年SPPnet
针对问题:
如RCNN会将输入的目标图像块处理到同一尺寸再输入进CNN网络,在处理过程中就造成了图像块信息的损失。在实际的场景中,输入网络的目标尺寸很难统一,而网络最后的全连接层又要求输入的特征信息为统一维度的向量。作者就尝试进行不同尺寸CNN网络提取到的特征维度进行统一。
创新点:
作者提出的SPPnet中,通过使用特征金字塔池化来使得最后的卷积层输出结果可以统一到全连接层需要的尺寸,在训练的时候,池化的操作还是通过滑动窗口完成的,池化的核宽高及步长通过当前层的特征图的宽高计算得到。原论文中的特征金字塔池化操作图示如下。
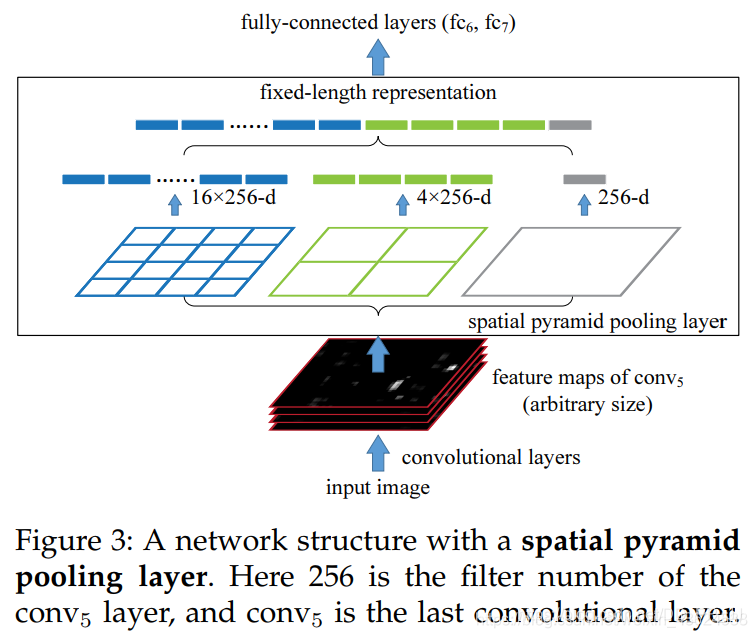
详解的博客:https://blog.csdn.net/weixin_43624538/article/details/87966601
第七篇 Multi Region CNN
《Object detection via a multi-region & semantic segmentation-aware CNN model》
提出时间:2015年
针对问题:
既然第三篇论文multibox算法提出了可以用CNN来实现输入图像中待检测目标的定位,本文作者就尝试增加一些训练时的方法技巧来提高CNN网络最终的定位精度。
创新点:
作者通过对输入网络的region进行一定的处理(通过数据增强,使得网络利用目标周围的上下文信息得到更精准的目标框)来增加网络对目标回归框的精度。具体的处理方式包括:扩大输入目标的标签包围框、取输入目标的标签中包围框的一部分等并对不同区域分别回归位置,使得网络对目标的边界更加敏感。这种操作丰富了输入目标的多样性,从而提高了回归框的精度。
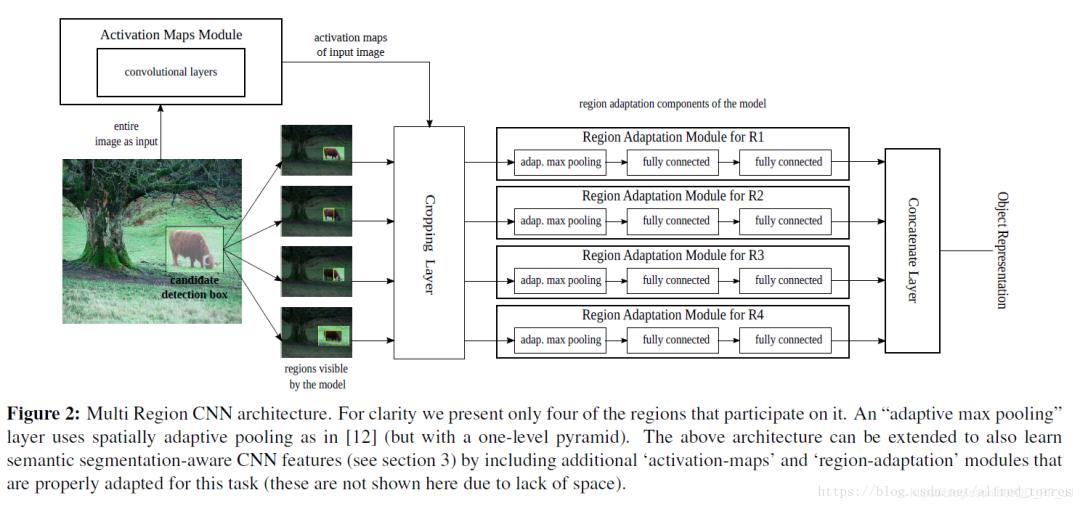
详解博客:https://blog.csdn.net/alfred_torres/article/details/83022967
第八篇 Fast R-CNN
提出时间:2015年
针对问题:
RCNN中的CNN每输入一个图像块就要执行一次前向计算,这显然是非常耗时的,那么如何优化这部分呢?
创新点:
作者参考了SPPNet(第六篇论文),在网络中实现了ROIpooling来使得输入的图像块不用裁剪到统一尺寸,从而避免了输入的信息丢失。其次是将整张图输入网络得到特征图,再将原图上用Selective Search算法得到的目标框映射到特征图上,避免了特征的重复提取。
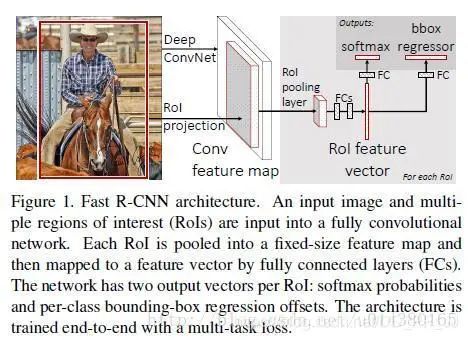
详解博客:https://blog.csdn.net/u014380165/article/details/72851319
第九篇 DeepProposal
《DeepProposal: Hunting Objects by Cascading Deep Convolutional Layers》
提出时间:2015年
主要针对和尝试解决问题:
本文的作者观察到CNN可以提取到很棒的对输入图像进行表征的论文,作者尝试通过实验来对CNN网络不同层所产生的特征的作用和情况进行讨论和解析。
创新点:
作者在不同的激活层上以滑动窗口的方式生成了假设,并表明最终的卷积层可以以较高的查全率找到感兴趣的对象,但是由于特征图的粗糙性,定位性很差。相反,网络的第一层可以更好地定位感兴趣的对象,但召回率降低。
第十篇 Faster R-CNN
提出时间:2015年NIPS
主要针对和尝试解决问题:
由multibox(第三篇)和DeepBox(第四篇)等论文,我们知道,用CNN可以生成目标待检测框,并判定当前框为目标的概率,那能否将该模型整合到目标检测的模型中,从而实现真正输入端为图像,输出为最终检测结果的,全部依赖CNN完成的检测系统呢?
创新点:
将当前输入图目标框提取整合到了检测网络中,依赖一个小的目标框提取网络RPN来替代Selective Search算法,从而实现真正的端到端检测算法。
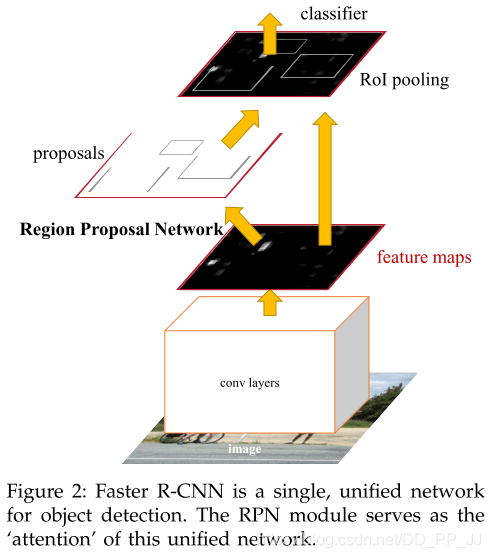
详解博客:https://zhuanlan.zhihu.com/p/31426458
总结
第一章是检测CNN开始的阶段,这个阶段的模型最早从Alexnet的分类模型开始,首先提出了检测网络模型的基础结构RCNN(第一篇),接着讨论了利用CNN网络同时完成定位和分类任务的可能性(第二篇)。接着就是基于以上两篇论文的思路,对检测网络的不同部分进行完善。首先针对候选目标框提取部分,也就是图像中目标的定位,分别为基于全图直接回归(第三篇),基于自底向上方案候选框的筛选(第四篇)以及基于全图的迭代回归(第五篇)做了尝试;接着对不同尺度的目标如何统一训练的问题进行了优化(第六篇),并通过一些训练技巧来强化网络模型的精度(第七篇);然后是对CNN中不同层输出特征情况的研究,以此奠定了CNN网络不同层的特征具有不同的作用(第九篇);最终,总结并 凝练学者们提出的检测模型结构和改进,形成了两阶段目标检测框架Fast RCNN和Faster RCNN。也标志着用CNN来实现端到端的目标检测任务的主流方向确定。

对文章有问题,或者对公众号的建议欢迎在评论区反馈!
希望加入交流群,可以添加BBuf微信