
谷歌简单粗暴“复制-粘贴”数据增广,刷新COCO目标检测与实例分割新高度
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
近日,谷歌、UC伯克利与康奈尔大学的研究人员公布了一篇论文 Simple Copy-Paste is a Strong Data Augmentation Method for Instance Segmentation ,使用简单粗暴的“复制-粘贴”术,再次刷新COCO数据集上目标检测与实例分割的新高度。
该论文全文无公式,也无算法流程图,介绍方法只用了3句话,如下:

其余全是实验,但结果异常好,其最好模型在COCO数据集上实例分割和目标检测任务中分别达到49.1 mask AP 和 57.3 box AP,比之前最好结果分别高0.6 和1.5 个点!
该文作者信息:

该文主要使用了训练集中实例分割对象复制粘贴实现训练阶段的数据增广,其增广方法三个字概括为“无限制”,CV君把其过程总结为 5 个随机:
随机选择两幅训练图像
随机尺度抖动缩放
随机水平翻转
随机选择一幅图像中的目标子集
粘贴在另一幅图像中随机的位置
以上 5 个随机后把mask和box标注进行更新。
是不是就是你心中那个最简单粗暴的想法?
可能有些同学看到过其他论文在使用复制粘贴术增强数据的时候对位置和尺度进行建模,使其符合这个世界的尝试(这样好像更合理),但谷歌学者在论文中一再说明:不需要!乱放其实挺好!
请看下图:

数据增广后,长颈鹿飞到运动员的手臂上,鸵鸟进入比赛场,一边在激烈比赛一边还有动物在悠闲观看。。。
这样的场景看起来不合理,但论文实验结果显示,这样的数据增广却真实提高了模型精度。
另外,也许我们会想,目标边缘是不是要处理一下?毕竟直接放进去看起来不自然。但谷歌学者发现这个其实也没必要处理,反正他们信了一些论文处理了也没发现有提升。
总结起来就是:数据增强的结果看起来不自然,没关系!又不是给人看。
特别值得一提的是,作者除了重点强调复制粘贴要简单粗暴外,还在论文实验中发现,对于尺度抖动也不要太温柔。
一种标准的尺度抖动,把图像缩放到原来的0.8-1.25,这个标准看起来对原数据的改变不是太大,应该是大部分人的选择。但谷歌学者发现把图像缩放到0.1到2.0之间其实更好。
一组标准的尺度抖动缩放示例:

更“大胆”的大尺度抖动:
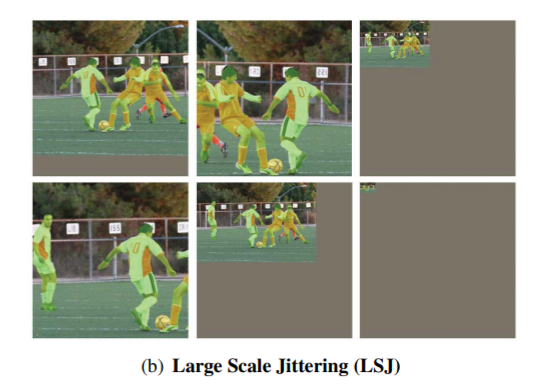
最右下角很显然已经小到人眼不可辨了。
不过没关系,反正不是给人看。
另外作者发现,这种方法也可以提高自训练方法的最终训练效果。
好了,我们已经完全理解这个算法了(其实就是简单粗暴复制粘贴+更大胆的尺度缩放),一起来看看实验结果如何。
作者做了很多实验,证明了此策略的两个优点:
很有效,精度提高很明显;
一直很有效,无论数据有改变、模型有改变还是任务有改变,精度提升一直很明显。
与其他SOTA目标检测算法在COCO数据集上的结果比较:
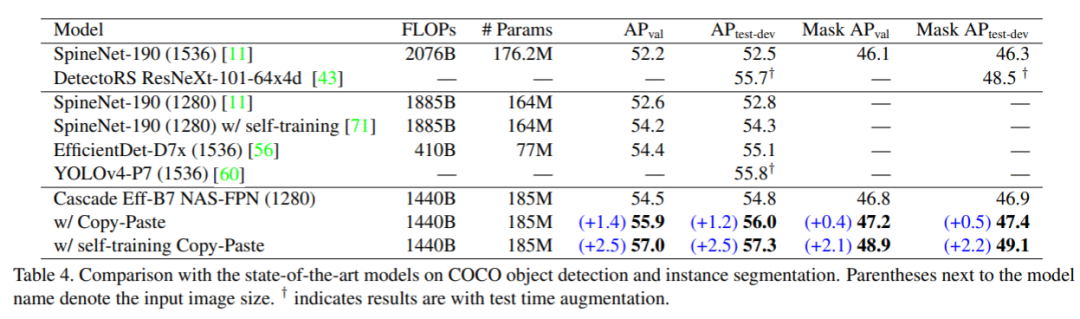
使用Cascade - Mask RCNN-EfficientNet-B7 NAS-FPN算法时(因其天然的可以得到实例分割和目标检测的结果,方便比较),在该文复制粘贴术+自训练的加持下将该数据集的最高精度推高到57.3 box AP,超过了YOLOv4-P7。(当然YOLOv4-P7并没有使用同样的数据增广方法,如果使用了也许更高,各位同学不妨一试)其实例分割结果也超过了之前的最好结果。
在LVIS数据集上的结果:
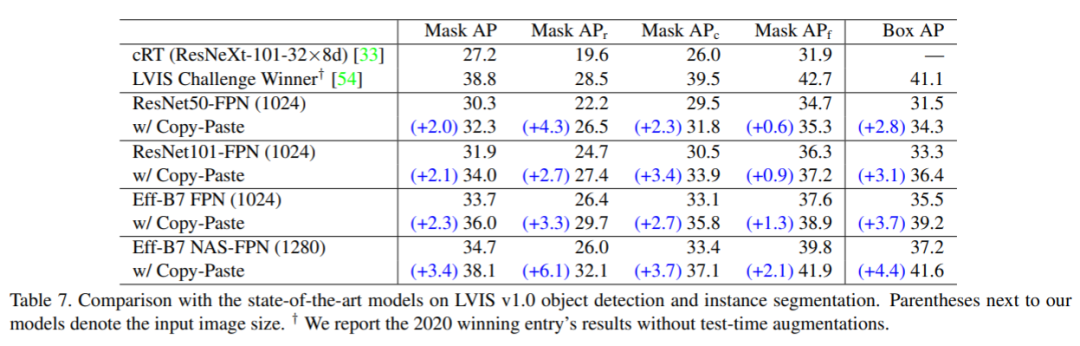
同样显著提高了相应基模型的精度。
另外,作者研究了在各种不同情况下,简单粗暴复制粘贴术都能提高模型精度。
比如:
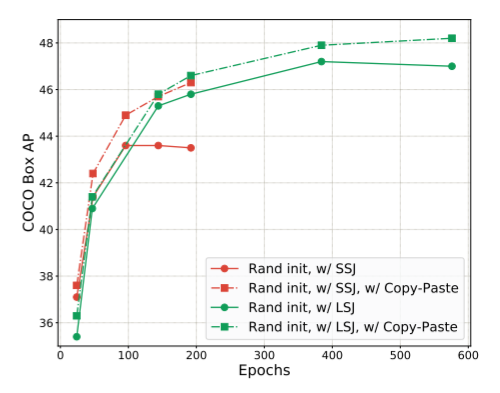
不同初始化方法下,增广后精度都有大度提高:
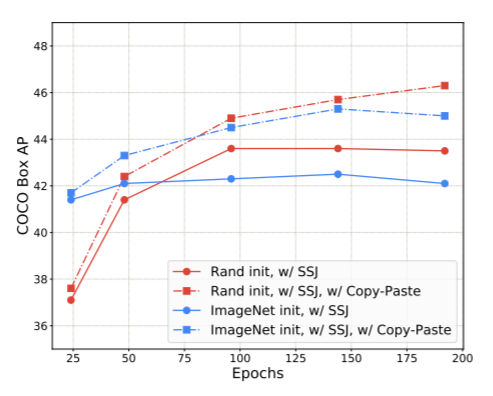
SS为标准尺度抖动,LS为大尺度抖动。
不同尺度抖动方法下,增广后精度都有提高:
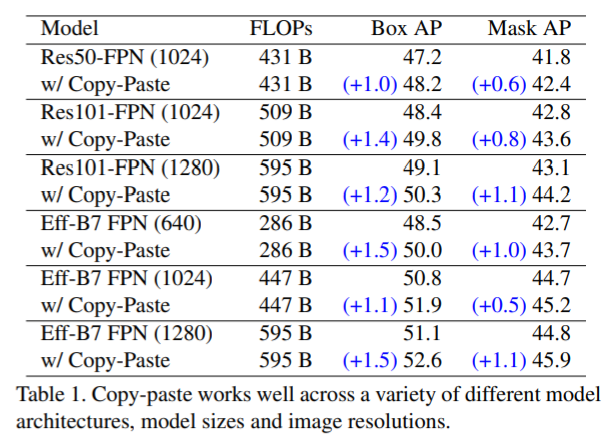
不同模型,不同输入分辨率,依然有效果:
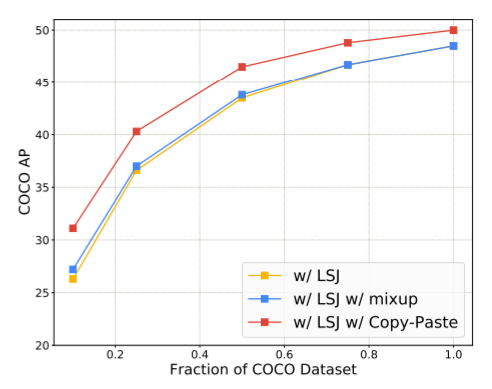
Copy-Paste与mixup增广方法相比,精度提升更明显:
自训练和复制粘贴术联合使用,效果更好:

由上图可知,精度增益几乎是实打实的“1+1=2”了,说明他们合起来真是绝配。
另外,作者还将通过这种增强方法得到的模型用于其他数据集任务的预训练模型,同样获得了精度提升:
在下游任务为VOC 2007 目标检测中:

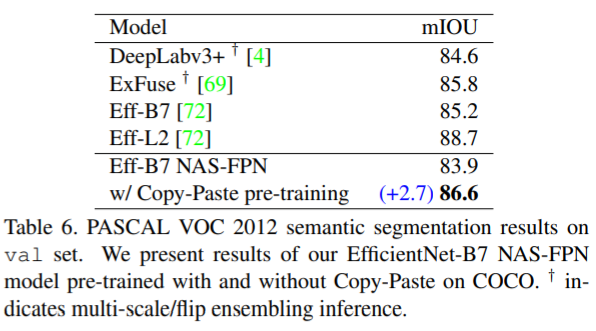
在下游任务为VOC 2012 实例分割中:
总之,这篇论文说明:简单粗暴复制粘贴+更加大胆尺度抖动的数据增广,尽管看起来不太合理,但对于改进目标检测与实例分割的模型效果是立竿见影的,而且与自训练方法结合效果更佳!
论文地址:
https://arxiv.org/pdf/2012.07177.pdf
目前没发现该文有开源代码(可能是官方觉得太简单了,没必要开源吧。。。)

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~