
语义分割和目标检测是什么关系?
首先,让我们看一下语义分割和目标检测的目标分别是什么?
语义分割的目标
语义分割的任务是对输入的图像进行逐像素的分类,标记出像素级别的物体。

如上图,图1中把猫、天空、树、草地进行了逐像素的分类;图2中把牛、天空、树、草地进行了逐像素的分类。
目标检测的目标
目标检测的任务是对输入的图像进行物体检测,标注物体在图像上的位置,以及该位置上物体属于哪个分类。

如上图,模型把图中的人、狗、马分别进行了位置标注,并且也给出了对应的分类类别。
两种任务的异同之处:
一、从大方向的任务特点上来说
从大方向的任务特点来说,语义分割和目标检测任务目标都在意两个关键信息:
1)物体的位置
待检测的物体,它在图像中位于什么位置。
对于语义分割来说,这个信息需求的精准度在像素级别的。概括地说,我们需要把物体的轮廓描绘出来,以此来体现它的位置信息。
对于目标检测来说,这个信息需求的精准度仅在标注其外切矩形。换句话来说,把物体框出来,以此来体现它的位置信息。
2)物体的分类
有了位置信息之后,语义分割和目标检测都存在对物体的分类。不同的是:
对于语义分割来说,它提供的信息中位置信息和分类信息是有重叠的,即通过标记每个像素的分类,同时也达到提供位置信息。
对于目标检测来说,分类信息是针对每个标注的框的,每一个框对应着自己的分类。
二、从数据格式来说
正如前文所说,由于在任务的目标上存在着一些区别,这就使得它们需要不同的数据格式进行标注。
1)语音分割的数据格式
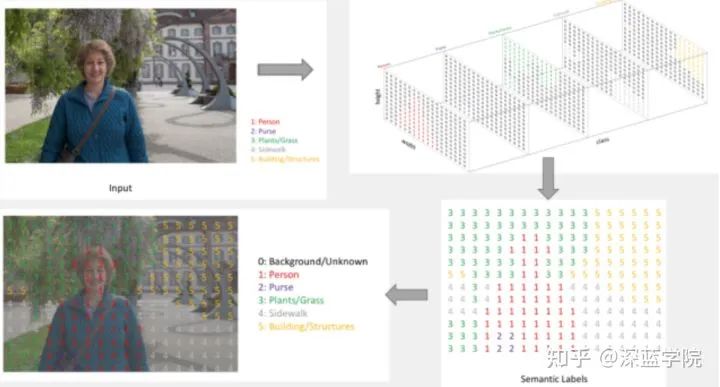
如上图,这张图中先验是5个类别。在分类中,会有5个channel,每个channel负责一个类别的概率预测。最后,每个像素上,以5个channel中的最大值作为最终分类,以此完成图像语义分割的标注工作。
2)目标检测的数据格式
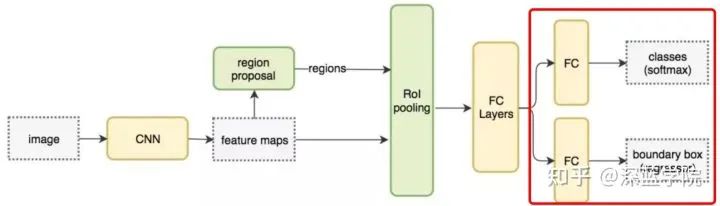
从上图中我们可以看到,对于目标检测的数据格式分为了两个部分,分类和框的坐标。具体体现为:
分类最终体现在对每个潜在框分类的1*1*channel上,每个channel代表一个分类,取值最大的channel作为最终分类;位置信息会用4个值来保存:被分类的物体中它的框的坐标则为左上角的x和y坐标,以及宽和高的尺寸。
共享上游的特征提取网络
无论是语义分割和目标检测任务,它们都有一个特征提取的backbone。它们通常是从图像分类网络中进行嫁接的。当我们发现有性能更佳的分类网络时,把它嫁接到语义分割或目标检测上,通常也能带动下游任务性能的提升。
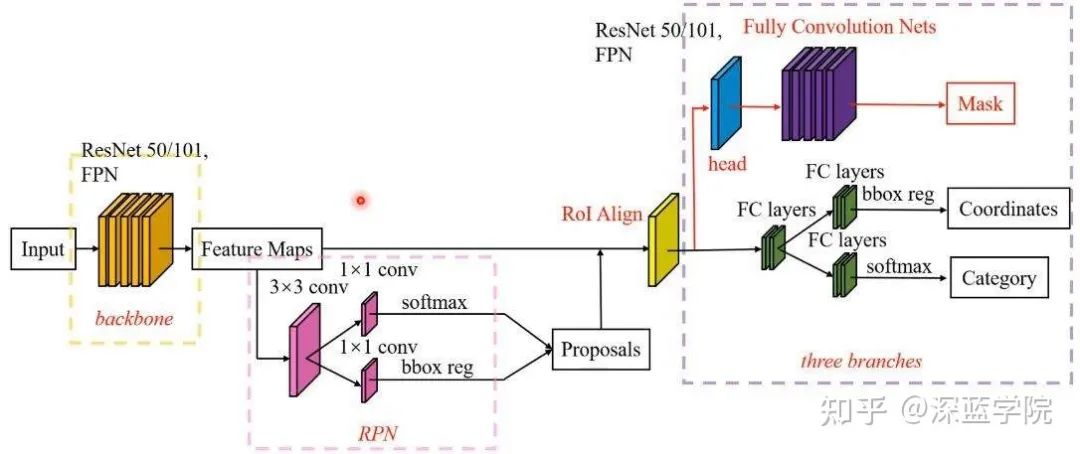
如上图,在Mask RCNN中,它同时处理了语义分割和目标检测的任务,在此网络的上游阶段,它们共享着ResNet的backbone网络。
小结
语义分割和目标检测,它们有着类似的任务目标,把物体标注出来,并且标记物体的具体分类信息。不同的是,语义分割所标记的物体是像素级别的颗粒度的,而目标检测标记的物体是其外切框。
不过,虽然存在着不同的任务细节特点,但是它们在网络上游上具有相同的特征提取的需求,于是,它们可以共享以图像分类为backbone的特征提取网络。
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码