
二次元属性被稀释,B站还剩什么?| 数据爬取
本文为HeoiJin原创投稿文章,欢迎更多读者投稿!
作者简介
HeoiJin:立志透过数据看清世界的产品策划,专注爬虫、数据分析、产品策划领域。
万物皆营销 | 资本永不眠 | 数据恒真理
CSDN:https://me.csdn.net/weixin_40679090
由于篇幅过大原因,文章将分为上篇与下篇:上篇为数据爬取,下篇为数据分析。今天为大家带来的是上篇:爬取B站数据!
本篇目录
一、项目背景
最近看了一篇对B站2019年数据解读的文章,文章最后得出结论:B站的二次元属性已被稀释,逐渐走向大众。
那么走过2020年的春节后,二次元属性的稀释情况如何?什么分区是B站的龙头?b站的主流用户喜欢什么标签的视频?各分区的情况能带来什么社会价值?本项目将通过数据带你一起窥探B站的变化。
项目特色:
- 利用Scrapy框架进行网页爬取
- 利用pandas、numpy进行数据分析
- 利用pyecharts进行数据可视化
- 利用scipy进行相关性分析
二、工具和环境
- 语言:python 3.7
- IDE:Pycharm
- 浏览器:Chrome
- 爬虫框架:Scrapy 1.8.0
三、需求分析
B站是我们熟悉的弹幕视频分享网站,根据百度百科的资料显示,B站的主要业务包括直播、游戏、广告、电商、漫画、电竞。在这么多项的业务当中,我们不难看到一个共同点,B站的主要盈利模式是高度依赖用户,其次是主播和UP主。因此要分析B站的变化,就要从用户喜爱变化情况切入分析,本次项目将采集以下数据:- 排行榜的分区名
- 排行页:视频的标题、作者、综合评分、排名、视频链接
- 详情页:视频的播放量、三连量、评论量、弹幕量、转发量、热门标签
四、页面分析
4.1 排行榜页解析
首先从排行榜页面进行过分析。禁用Javascript后,发现要提取的信息都是在静态网页当中,那么在编写代码的时候通过xpath定位抓取信息即可。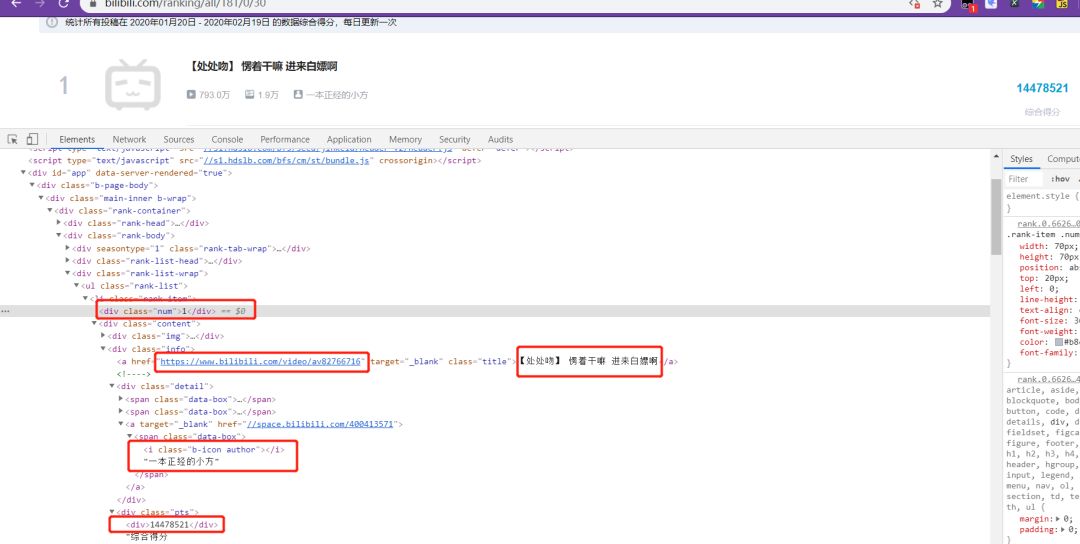 完成单个分区排行榜页面的分析后,只需找到各排行榜对应的url即可实现爬取多个分区。通过检查网页源码,发现每一个分区都只有文字描述,并没有相关的url,因此通过分析url变化再自行构造请求的url。
完成单个分区排行榜页面的分析后,只需找到各排行榜对应的url即可实现爬取多个分区。通过检查网页源码,发现每一个分区都只有文字描述,并没有相关的url,因此通过分析url变化再自行构造请求的url。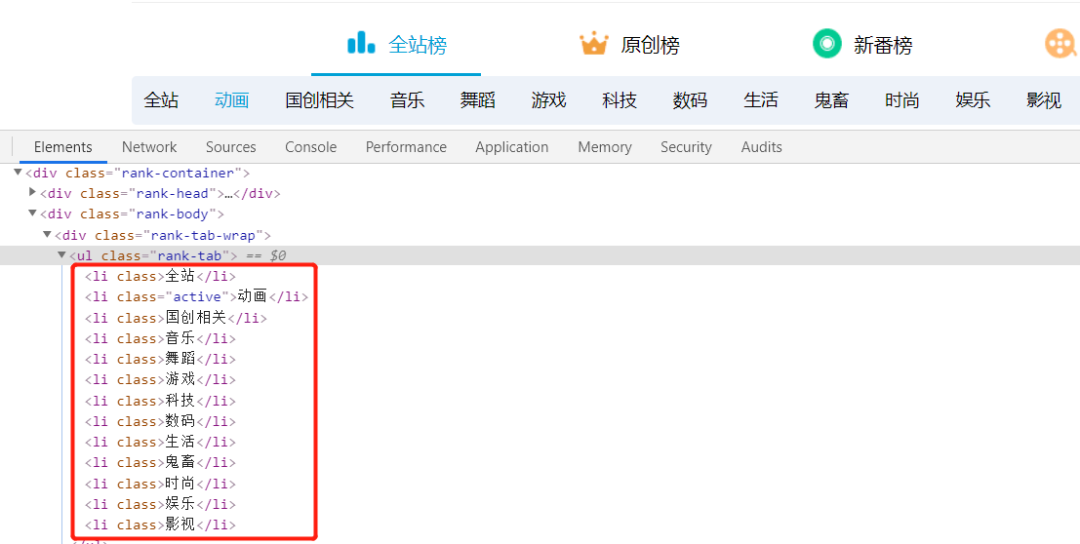 url规则即对应编号:https://www.bilibili.com/ranking/all/编号/0/30以下是各分类对应的编号:
url规则即对应编号:https://www.bilibili.com/ranking/all/编号/0/30以下是各分类对应的编号: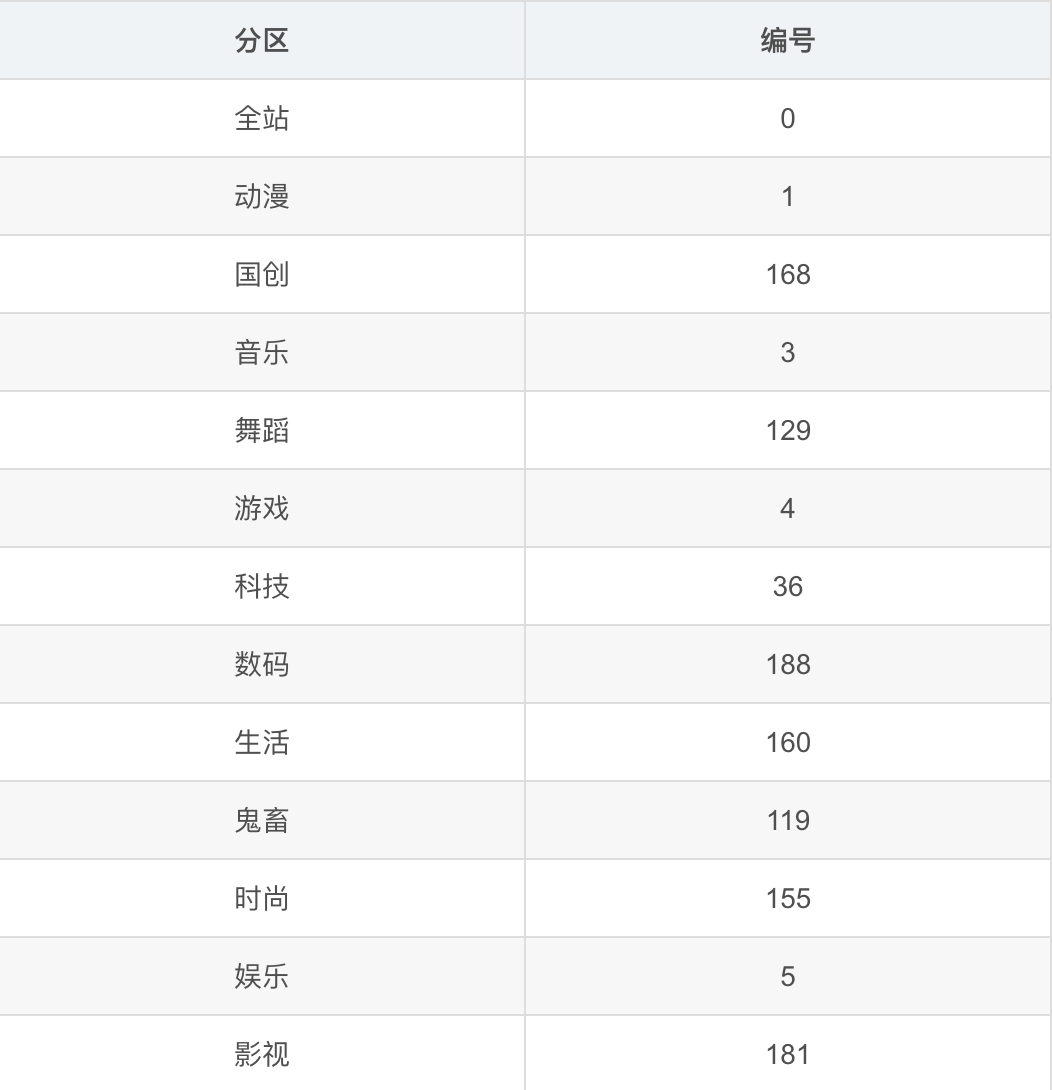 我们创建一个编号的列表,并用循环拼接url即可完成url的批量生成
我们创建一个编号的列表,并用循环拼接url即可完成url的批量生成from pprint import pprintlabels_num=[0,1,168,3,129,4,36,188,160,119,155,5,181]url_list=[f'https://www.bilibili.com/ranking/all/{i}/0/30' for i in labels_num]#利用pprint方法,我们能够在输出时实现一个url一行pprint(url_list)
4.2 详细信息页面api解析
我们还需要获取视频的播放量、三连量、评论量、弹幕量、转发量、热门标签,但在排行榜页中并没有体现,因此要进一步请求视频的详情页。进入视频详情页,同样禁用Javascript后,可以发现要找的信息都是ajax异步加载的,在这里考虑抓取api文件来获取信息,这样能够大大提升解析网页的效率,也不容易被封ip。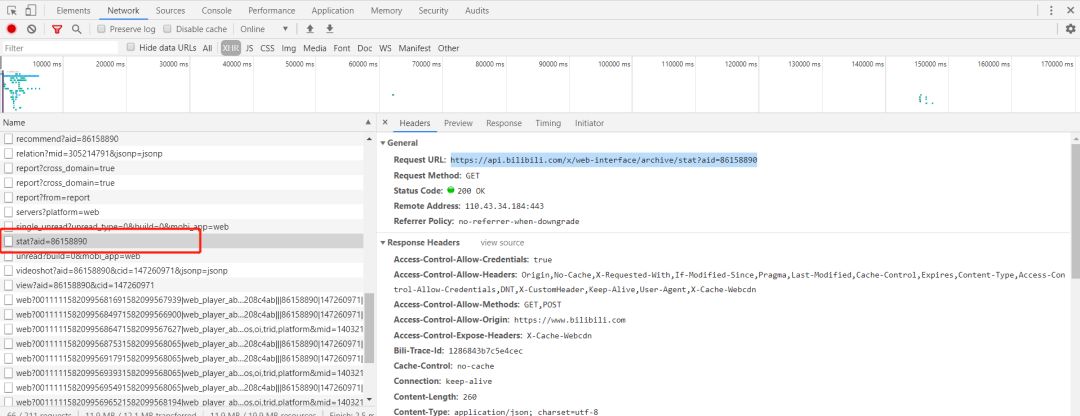 通过一轮的分析之后,找到了视频的播放量、三连量、评论量、弹幕量、转发量数据在stat?aid=文件当中,url末端的数字即视频的id,后续对视频链接进行切片获取id再拼接Request URL即可。访问该Request URL,是标准的json数据。
通过一轮的分析之后,找到了视频的播放量、三连量、评论量、弹幕量、转发量数据在stat?aid=文件当中,url末端的数字即视频的id,后续对视频链接进行切片获取id再拼接Request URL即可。访问该Request URL,是标准的json数据。 对数据页面进行json解析,后续只需获得键:[‘data ‘]下的数据即可
对数据页面进行json解析,后续只需获得键:[‘data ‘]下的数据即可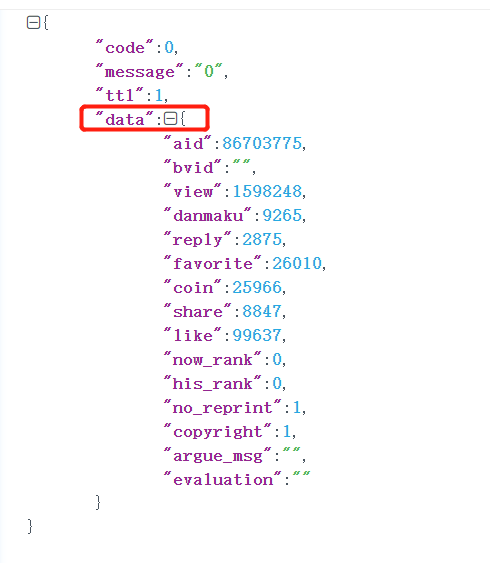 到这里还缺少了热门标签的数据,继续抓包找到另外一个api的url,同样需要通过视频的id进行url构造。
到这里还缺少了热门标签的数据,继续抓包找到另外一个api的url,同样需要通过视频的id进行url构造。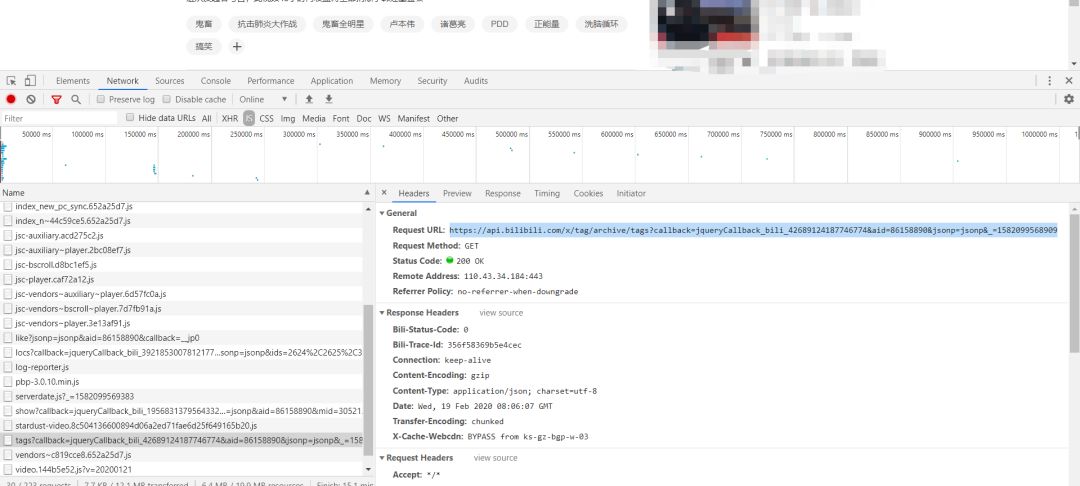
但直接访问这个url,会显示要找的页面不存在。观察url发现,?后包含了很多参数,尝试仅保留关键的视频id参数再次访问后,能够获取需要的信息。也是非常工整的json数据。
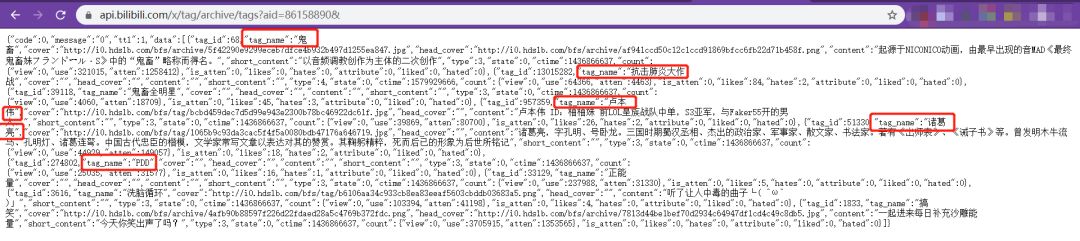
解析json后,只需要获取键[“data”]下的所有[‘tag_name ‘]即可。
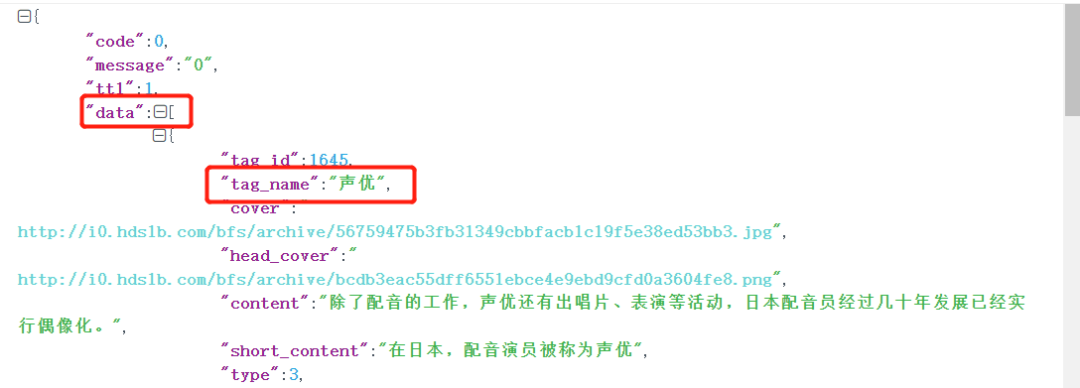 至此所有需要的url及相关定位信息都基本找到,下面就可以开始编写爬虫文件了。
至此所有需要的url及相关定位信息都基本找到,下面就可以开始编写爬虫文件了。五、爬虫分析
5.1 Scrapy框架爬虫概述
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。Scrapy架构图(绿色箭头为数据流向)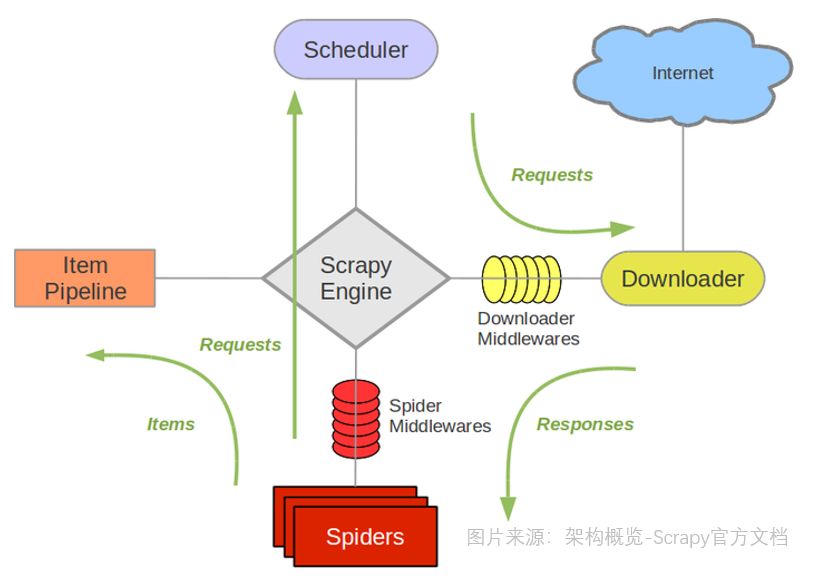 本次项目涉及的组件介绍Scrapy Engine
本次项目涉及的组件介绍Scrapy Engine引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。调度器(Scheduler)
调度器从引擎接收request并将他们入队,以便之后引擎请求他们时提供给引擎。下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider。Spiders
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。每个spider负责处理一个特定(或一些)网站。Item Pipeline
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)
5.2 为什么用Scrapy框架爬虫
Scrapy 使用了异步网络框架来处理网络通讯。相比于普通的Request爬虫或者多线程爬虫,Scrapy在爬取页面上具有更高的效率(详细的效率比较可以看这篇《Python爬虫的N种姿势》:https://www.cnblogs.com/jclian91/p/9799697.html)同时完善的框架意味着只需要定制开发其中的模块就能轻松实现爬虫,有清晰的逻辑路径。六、爬虫编写
如果之前还没有安装Scrapy,可在cmd中使用pip语句进行安装pip3 install Scrapy
6.1 新建爬虫项目
去到要新建爬虫文件的文件夹中,在地址栏输入cmd,进入cmd模式。scrapy startproject blbl命令解读:
cd blbl
scrapy genspider bl "bilibili.com"
- scrapy startproject blbl:创建爬虫项目,项目文件命名为blbl
- sd blbl :进入项目文件
- scrapy genspider bl “bilibili.com” :创建爬虫文件,爬虫名为bl(注意爬虫名应有别于项目文件名,且在该项目中是唯一的),限定爬取的url范围”bilibili.com”
到这里我们爬虫创建就完成了,目录结构如下:
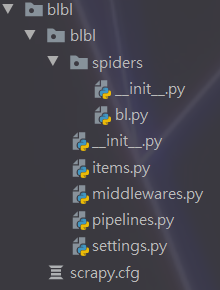
简单介绍下本项目所需文件的作用:
- scrapy.cfg :项目的配置文件
- blbl/blbl :项目的Python模块,将会从这里引用代码
- items.py :项目的目标文件
- pipelines.py :项目的管道文件
- settings.py :项目的设置文件
- spiders/ :存储爬虫代码目录
- bl.py :我们通过命令新建的爬虫文件
6.2 创建并编写start.py
通常启动Scrapy爬虫都是在shell或者cmd命令中进行。为了方便启动爬虫或者进行debug测试爬虫,创建一个start.py用来控制爬虫启动目标:- 在py文件中执行cmd命令
from scrapy import cmdline创建完成后,我们每次运行爬虫或者debug测试时,只需要执行这个文件即可。
cmdline.execute('scrapy crawl bl'.split())
6.3 编写settings.py
目标:- 关闭遵循君子协议
- 设置延迟(好的爬虫不应对别人服务器造成过大压力)
- 构造请求头
- 打开Pipeline(用于储存数据,取消注释即可)
ROBOTSTXT_OBEY = FalseDOWNLOAD_DELAY = 1DEFAULT_REQUEST_HEADERS = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language': 'en','User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36'}ITEM_PIPELINES = {'bilibili.pipelines.BlblPipeline': 300,}
6.4 编写bl.py
bl.py是我们通过cmd的命令符创建的爬虫文件,主要用于解析网站内容,并将解析后的数据传给items pipeline。目标:- 获得排名、视频标题、作者、得分
- 获得视频id,构造api链接
- 向api链接发送请求
- 获得三连、弹幕、评论和热门标签等数据
import scrapyfrom blbl.items import BlblItemimport jsonclass BlSpider(scrapy.Spider):name = 'bl'allowed_domains = ['bilibili.com']#start_urls默认为'http://'+allowed_domains[0]#所以这里我们要重写start_urls,把排行榜页面的url列表赋值给start_urlsstart_urls = ['https://www.bilibili.com/ranking/all/0/0/30','https://www.bilibili.com/ranking/all/1/0/30','https://www.bilibili.com/ranking/all/168/0/30','https://www.bilibili.com/ranking/all/3/0/30','https://www.bilibili.com/ranking/all/129/0/30','https://www.bilibili.com/ranking/all/4/0/30','https://www.bilibili.com/ranking/all/36/0/30','https://www.bilibili.com/ranking/all/188/0/30','https://www.bilibili.com/ranking/all/160/0/30','https://www.bilibili.com/ranking/all/119/0/30','https://www.bilibili.com/ranking/all/155/0/30','https://www.bilibili.com/ranking/all/5/0/30','https://www.bilibili.com/ranking/all/181/0/30']def parse(self, response):#获取当前爬取的榜单rank_tab=response.xpath('//ul[@class="rank-tab"]/li[@class="active"]/text()').getall()[0]print('='*50,'当前爬取榜单为:',rank_tab,'='*50)#视频的信息都放在li标签中,这里先获取所有的li标签#之后遍历rank_lists获取每个视频的信息rank_lists=response.xpath('//ul[@class="rank-list"]/li')for rank_list in rank_lists:rank_num=rank_list.xpath('div[@class="num"]/text()').get()title=rank_list.xpath('div/div[@class="info"]/a/text()').get()# 抓取视频的url,切片后获得视频的idid=rank_list.xpath('div/div[@class="info"]/a/@href').get().split('/av')[-1]# 拼接详情页api的urlDetail_link=f'https://api.bilibili.com/x/web-interface/archive/stat?aid={id}'Labels_link=f'https://api.bilibili.com/x/tag/archive/tags?aid={id}'author=rank_list.xpath('div/div[@class="info"]/div[@class="detail"]/a/span/text()').get()score=rank_list.xpath('div/div[@class="info"]/div[@class="pts"]/div/text()').get()#如用requests库发送请求,要再写多一次请求头# 因此我们继续使用Scrapy向api发送请求# 这里创建一个字典去储存我们已经抓到的数据# 这样能保证我们的详细数据和排行数据能一 一对应无需进一步合并# 如果这里直接给到Scrapy的Item的话,最后排行页的数据会有缺失items={'rank_tab':rank_tab,'rank_num' : rank_num ,'title' :title ,'id' : id ,'author' : author ,'score' : score ,'Detail_link':Detail_link}# 将api发送给调度器进行详情页的请求,通过meta传递排行页数据yield scrapy.Request(url=Labels_link,callback=self.Get_labels,meta={'item':items},dont_filter=True)def Get_labels(self,response):#获取热门标签数据items=response.meta['item']Detail_link=items['Detail_link']# 解析json数据html=json.loads(response.body)Tags=html['data'] #视频标签数据#利用逗号分割列表,返回字符串tag_name=','.join([i['tag_name'] for i in Tags])items['tag_name']=tag_nameyield scrapy.Request(url=Detail_link,callback=self.Get_detail,meta={'item':items},dont_filter=True)def Get_detail(self,response):# 获取排行页数据items=response.meta['item']rank_tab=items['rank_tab']rank_num=items['rank_num']title=items['title']id=items['id']author=items['author']score=items['score']tag_name=items['tag_name']# 解析json数据html=json.loads(response.body)# 获取详细播放信息stat=html['data']view=stat['view']danmaku =stat['danmaku']reply =stat['reply']favorite =stat['favorite']coin =stat['coin']share =stat['share']like =stat['like']# 把所有爬取的信息传递给Itemitem=BlblItem(rank_tab=rank_tab,rank_num = rank_num ,title = title ,id = id ,author = author ,score = score ,view = view ,danmaku = danmaku ,reply = reply ,favorite = favorite ,coin = coin ,share = share ,like = like ,tag_name = tag_name)yield item
6.5 编写Items.py
将爬取到的数据名称按照Scrapy的模板填写好即可目标:- 收集爬取到数据
import scrapyclass BlblItem(scrapy.Item): rank_tab=scrapy.Field() rank_num =scrapy.Field() id=scrapy.Field() title =scrapy.Field() author =scrapy.Field() score =scrapy.Field() view=scrapy.Field() danmaku=scrapy.Field() reply=scrapy.Field() favorite=scrapy.Field() coin=scrapy.Field() share=scrapy.Field() like=scrapy.Field() tag_name=scrapy.Field() 6.6 编写pipeline.py
运用scrapy原生的CsvItemExporter能够让我们从编写表头以及写writerow语句中解放出来,比传统写入csv的方法更简便。目标:- 利用CsvItemExporter把数据写入csv文件
from scrapy.exporters import CsvItemExporterclass BlblPipeline(object):def __init__(self):# a为追加写入模式,这里要用二进制的方式打开self.fp=open('bilibili.csv','ab')#include_headers_line默认为True# 能够帮我们自动写入表头,并且在追加写入数据的时候不会造成表头重复self.exportre=CsvItemExporter(self.fp,include_headers_line=True,encoding='utf-8-sig')def open_spider(self,spider):pass# 向csv文件中写入数据def process_item(self,item,spider):self.exportre.export_item(item)return itemdef close_spider(self,spider):self.fp.close()
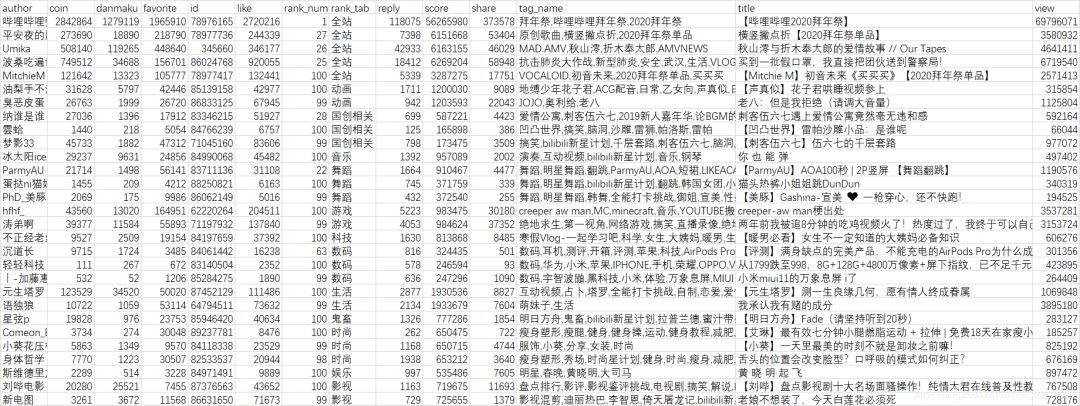
最后打开bilibili.csv,可以看到数据都完整爬取下来了!
七、本篇小结
最后回顾下本次爬虫的重点内容:- 对ajax异步加载的网页进行抓包,通过抓取Request URL访问异步加载数据
- 使用Scrapy框架爬虫进行数据采集
- 利用scrapy.Request向api发送请求并通过meta传递已爬取的排行页数据
- 利用Scrapy内置的CsvItemExporter将数据存储到csv中
下周二将推出本篇文章的下部分:数据分析实战环节,敬请期待吧~源码地址(或阅读原文):https://github.com/heoijin/Bilibili-Rnak
郑重声明:本项目及所有相关文章,仅用于经验技术交流,禁止将相关技术应用到不正当途径,因为滥用技术产生的风险与本人无关
评论