
爬取B站20万+条弹幕,我学会了如何成为B站老司机
本文含 3420 字,27 图表截屏
建议阅读 10分钟
前言
弹幕分析
户外区-华农兄弟
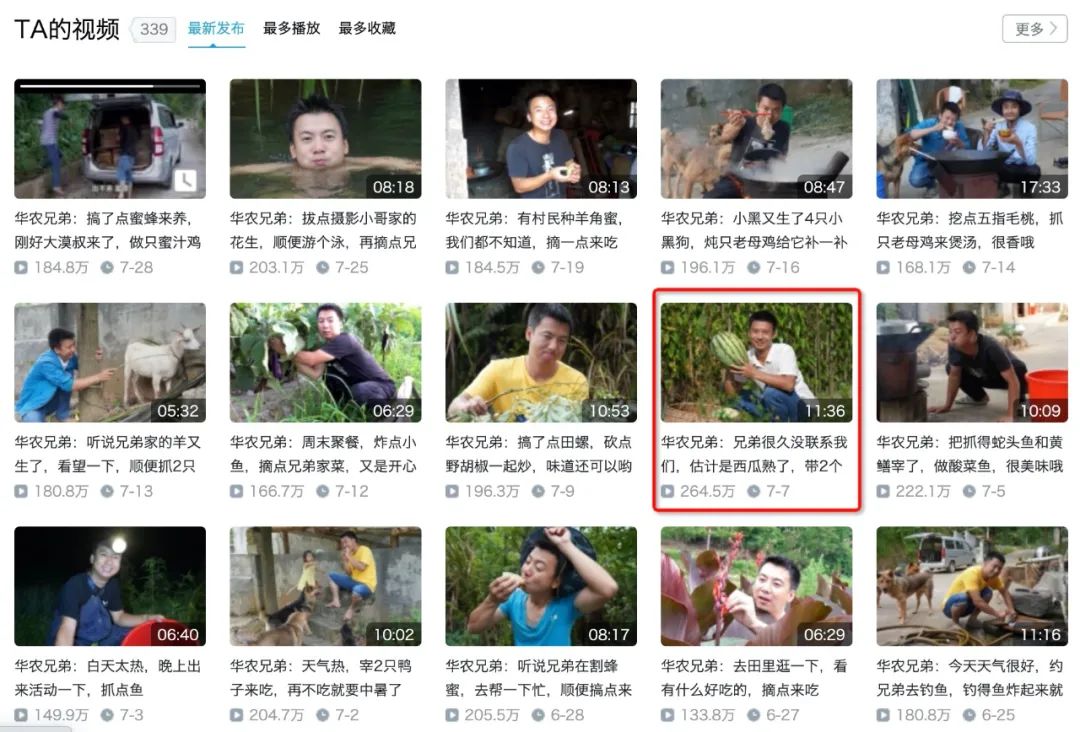

 ,其次就是村霸、危、亿点点、死因 等专属与华农兄弟的梗,还有类似于人言否、寸草不生、兄弟敢怒不敢言 等关键词也是弹幕爱刷的,学会了吗
,其次就是村霸、危、亿点点、死因 等专属与华农兄弟的梗,还有类似于人言否、寸草不生、兄弟敢怒不敢言 等关键词也是弹幕爱刷的,学会了吗
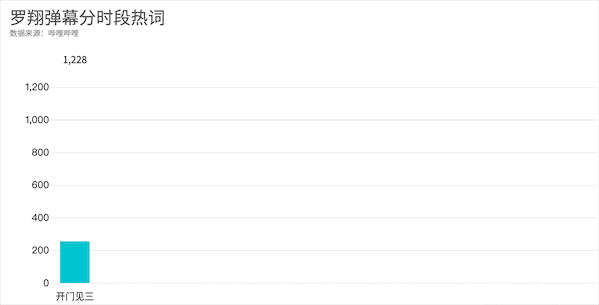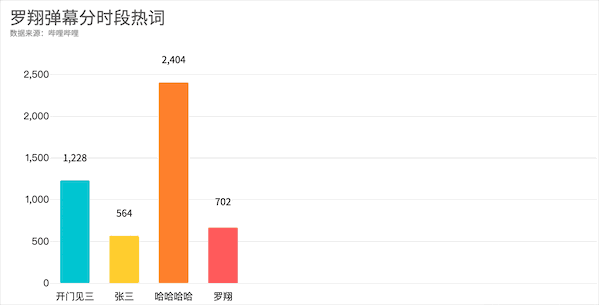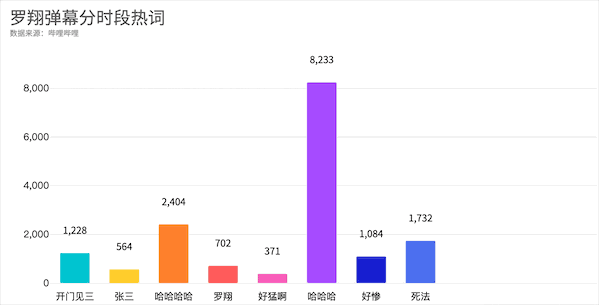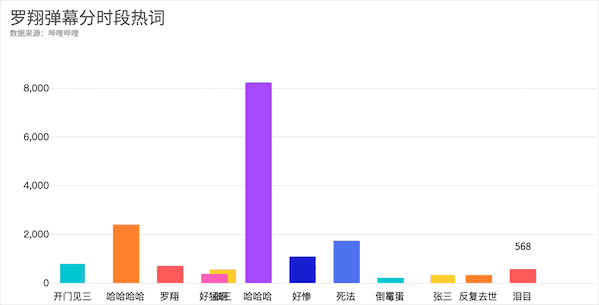
知识区-罗翔
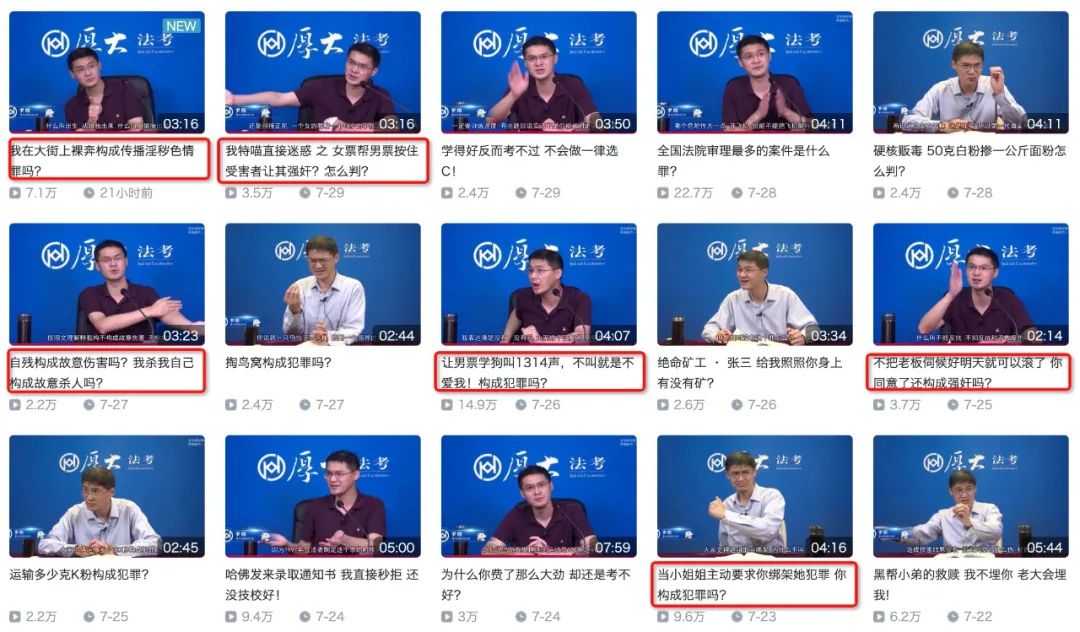
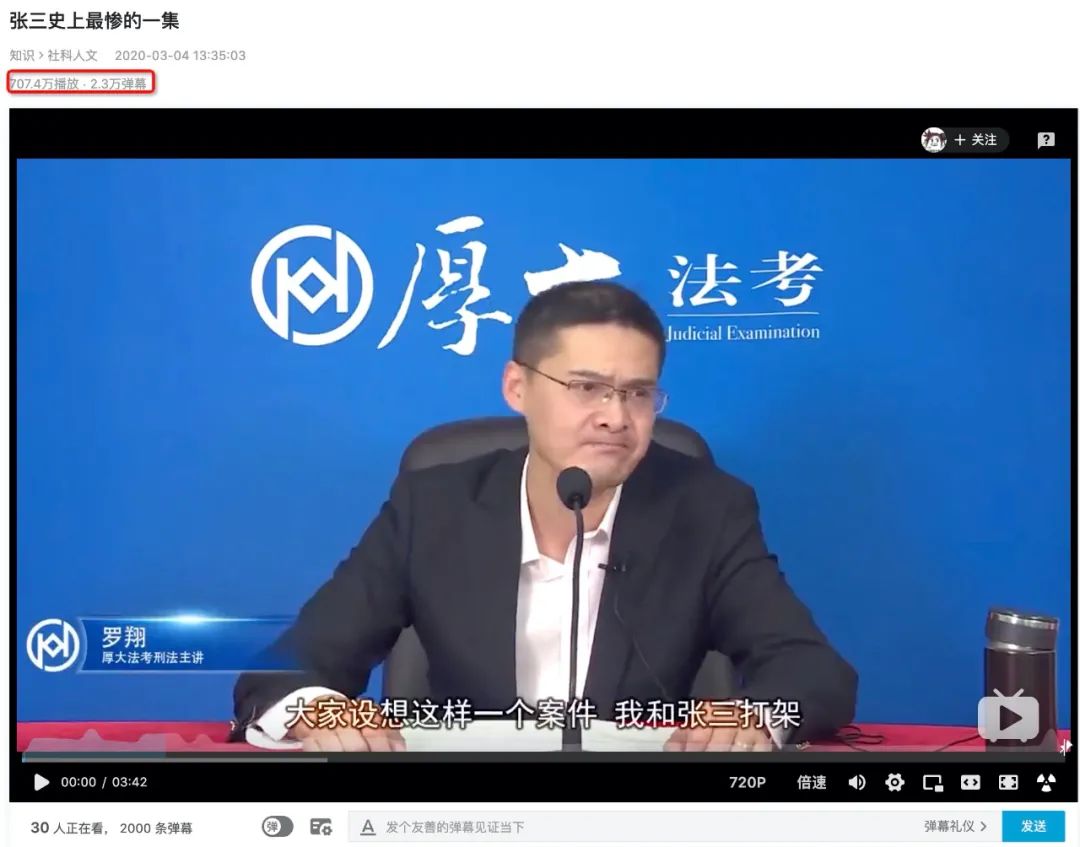
 。同时我们可以发现在华农兄弟弹幕区爱刷的死因来到罗老师这里成了死法,只不过一个是竹鼠的一百种死因一个是张三的一千种死法
。同时我们可以发现在华农兄弟弹幕区爱刷的死因来到罗老师这里成了死法,只不过一个是竹鼠的一百种死因一个是张三的一千种死法

生活区-手工耿

美食区-我是郭杰瑞
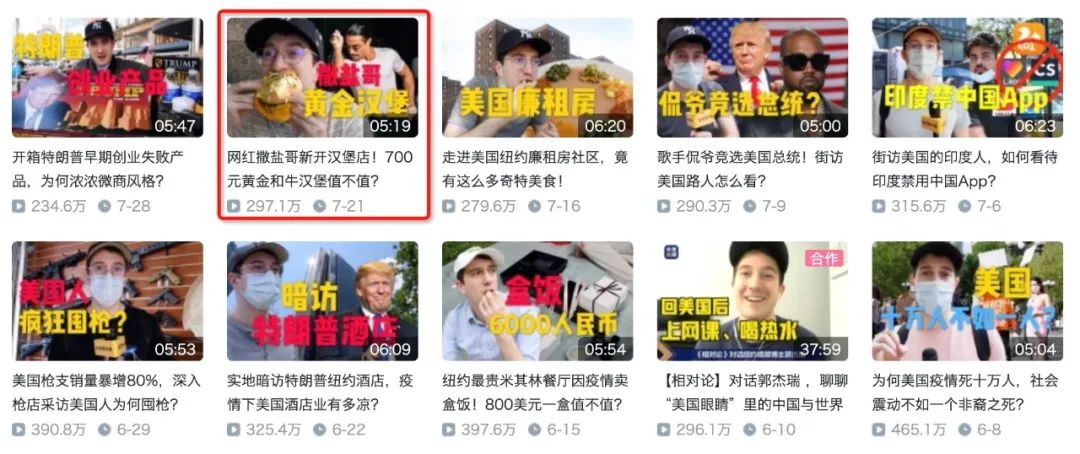


鬼畜区
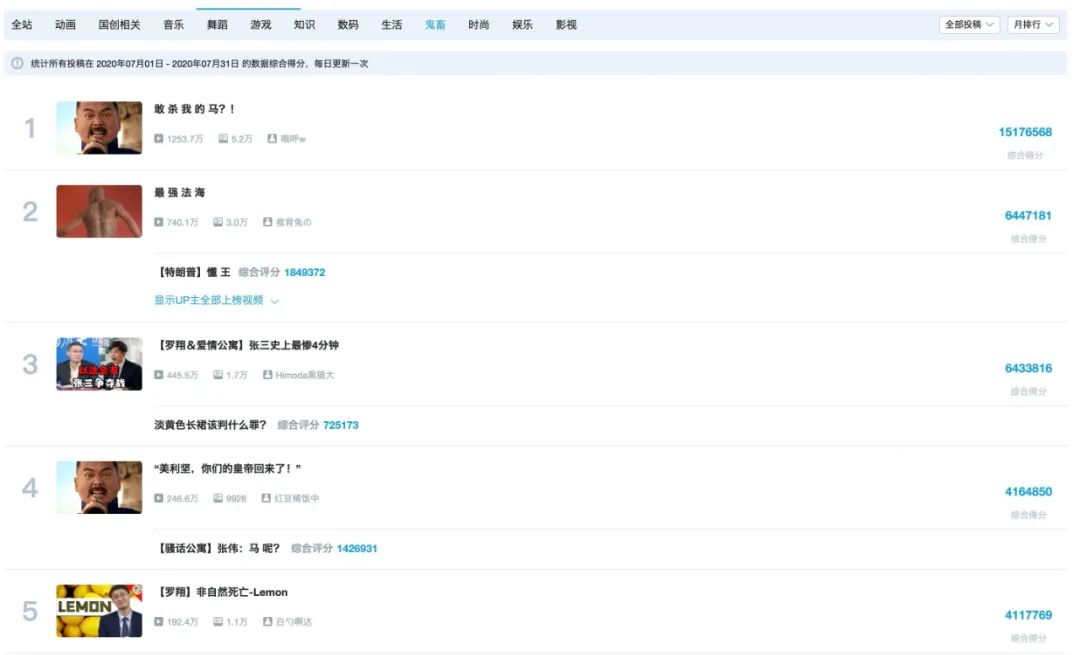

技术解析
requests请求数据,我们已华农兄弟的视频为例,首先打开需要采集弹幕的视频,然后F12—>Network,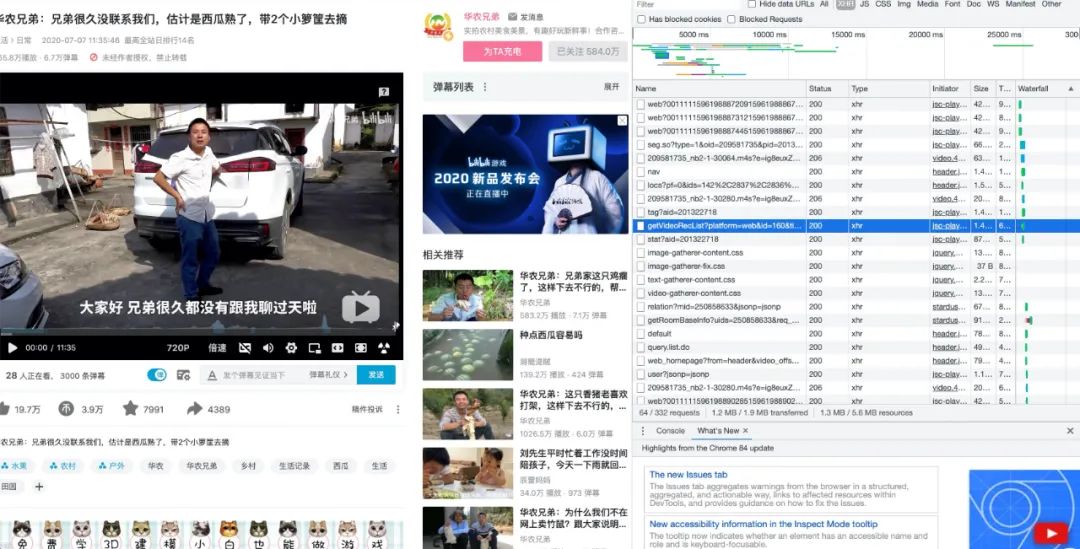
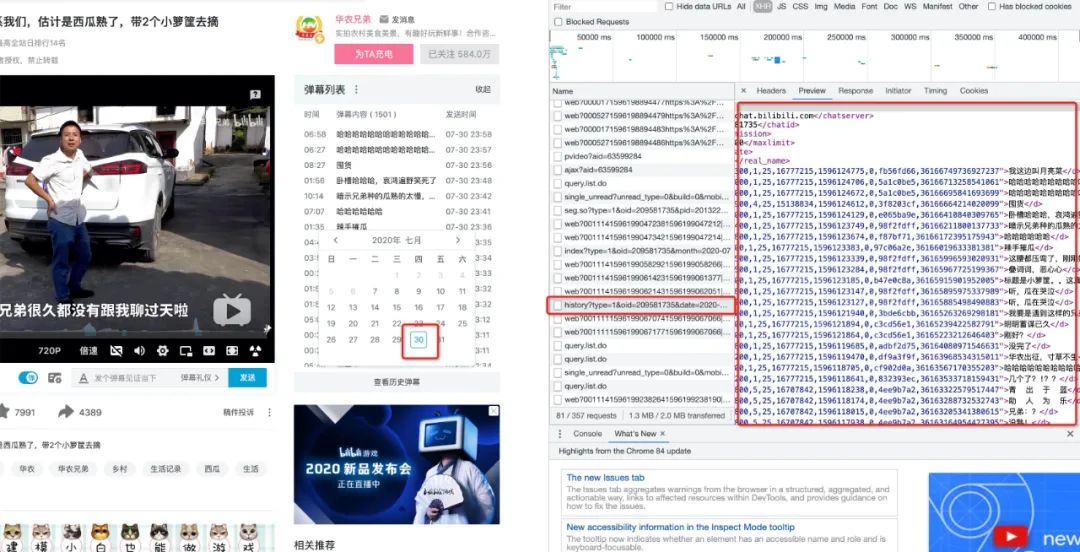
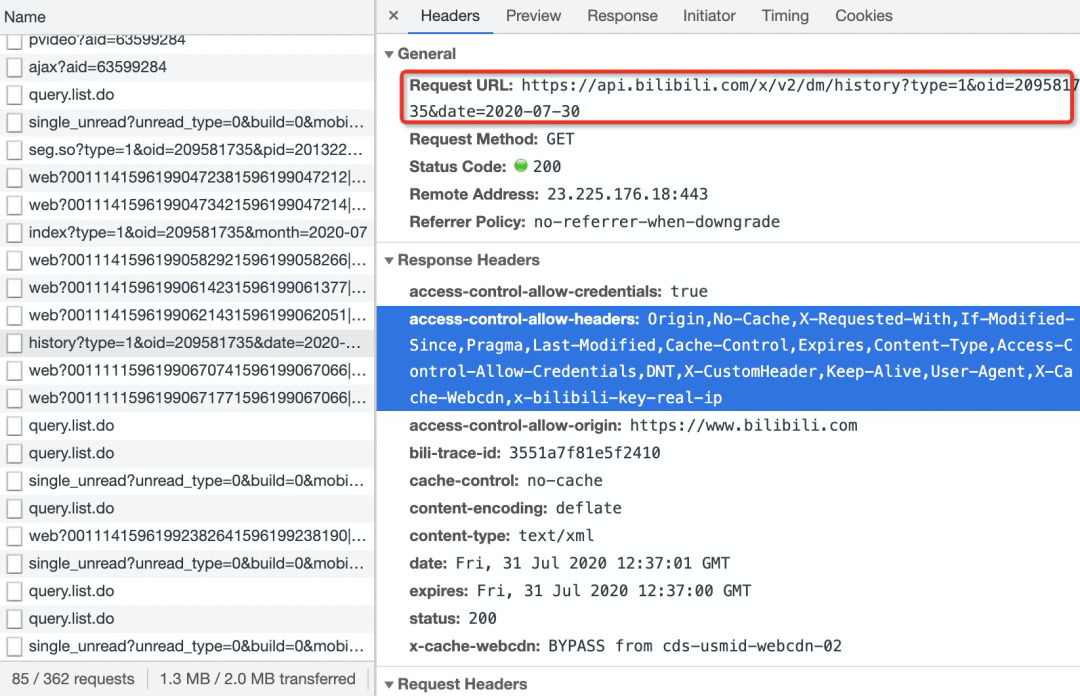
RequestURL关键就是oid和date两个参数,date是日期没什么好说的,oid虽然不知道是什么,但是一堆数据包中很多都是带有一个oid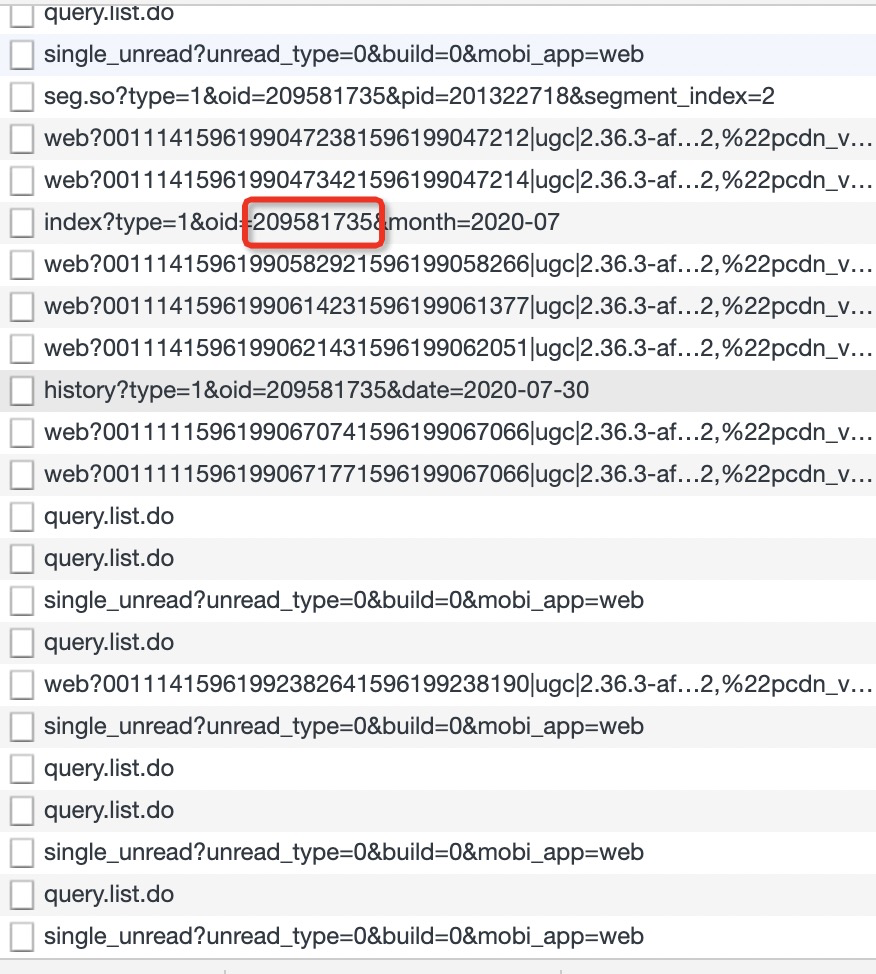
def get_url(oid,start,end):
'''
获取指定日期的弹幕
oid:视频oid
start,end:起止日期
'''
url_list = []
date_list = [i for i in pd.date_range(start,end).strftime('%Y-%m-%d')]
for date in date_list:
url = f"https://api.bilibili.com/x/v2/dm/history?type=1&oid={oid}&date={date}"
url_list.append(url)
return url_list
pandas中的date_range函数,非常好用,感兴趣的读者可以自行搜索了解,现在我们获得了指定日期的弹幕数据URL,接下来要做的就是使用requests请求网站并使用bs4解析数据,最后将数据写入TXT即可def get_danmu(url_list,name):
'''
下载弹幕存至本地txt
'''
headers = {"cookie": "修改为你的cookie",
"origin": "https://www.bilibili.com",
"referer": "https://www.bilibili.com/video/BV1gW411b735",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-site",
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36"}
file = open(f"{name}.txt",'w')
for i in trange(len(url_list)):
url = url_list[i]
res = requests.get(url,headers = headers)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text)
data = soup.find_all("d")
danmu = [data[i].text for i in range(len(data))]
for items in danmu:
file.write(items)
file.write("\n")
time.sleep(2)
file.close()
cookie等参数构造请求头循环请求数据即可,唯一要注意的就是返回的结果编码为ISO-8859-1,需要先使用res.encoding = 'utf-8'修改编码,否则就会乱码,当然我这里还是用了tqdm来添加进度条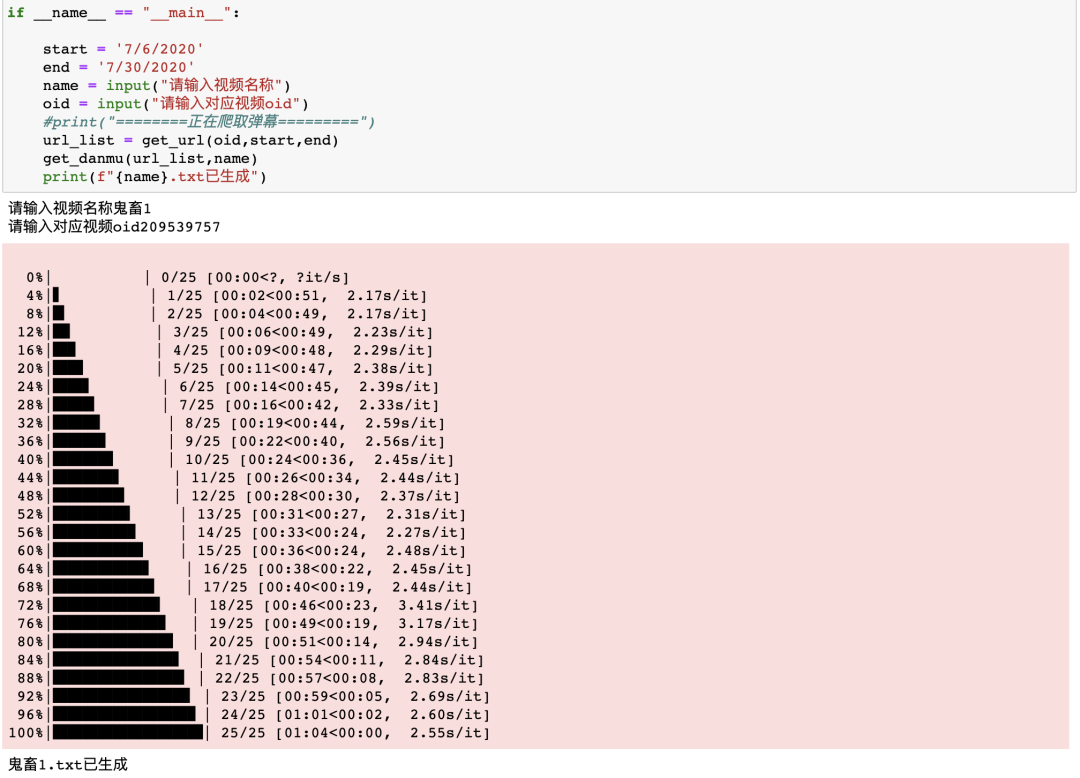
关注「Python 知识大全」,做全栈开发工程师 岁月有你 惜惜相处 回复【资料】获取高质量学习资料 【在看】和【赞】我都需要
评论