
Python之数据爬取&数据可视化
前言
临近中秋,月饼的销量持续增长,然而不仅仅是中秋节,非旺季也有很多月饼爱好者在电商平台购买月饼。本文利用淘宝上的公开数据,应用 python 对月饼非旺季的销售状况进行分析,并对统计结果进行数据可视化的展示。
数据来源
本次研究的数据来源于淘宝网关于月饼的公开数据,整个数据集包括 4033条数据,其中将为空值的数据直接从数据集中删除。
数据处理
数据预处理
对于较粗糙的数据:
1.添加列名
2.去除重复数据(翻页爬取过程中会有重复)
3.购买人数为空的记录,替换成0人付款
4.将购买人数转换为销量(注意部分单位为万)
5.删除无发货地址的商品,并提取其中的省份
描述型统计分析
1
价格分布
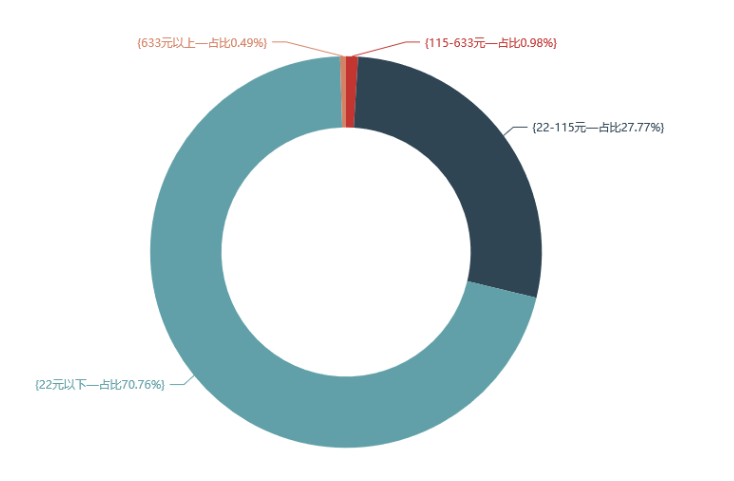
可以观察到22元以下占比最多,达到了百分之七十,说明大部分人在月饼的消费上还是比较保守的,更看中的是吃的属性,而非作为馈赠的礼物。
2
销量前十店铺
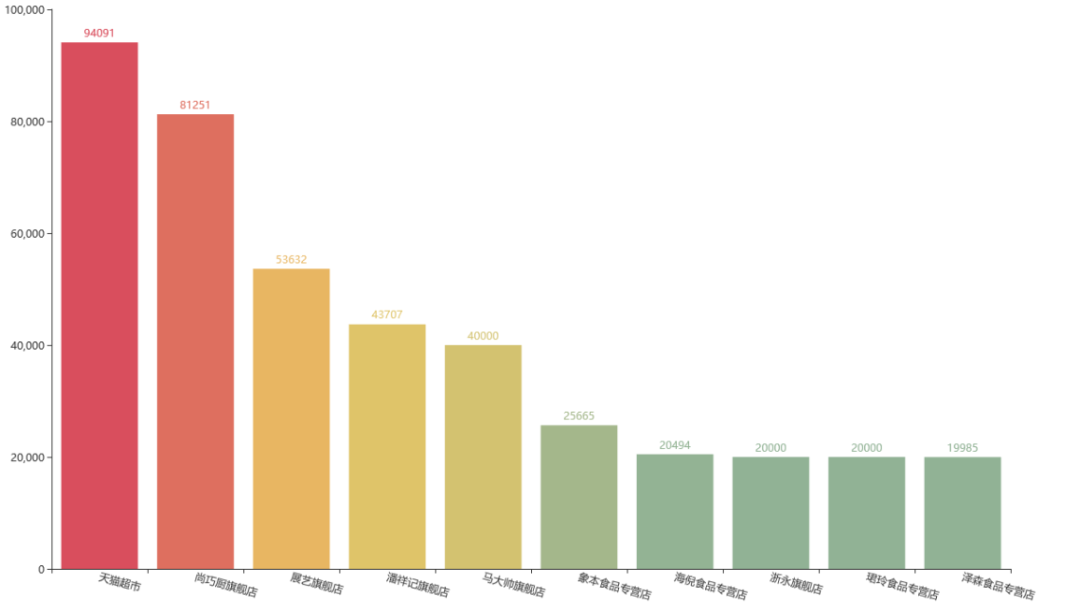
天猫超市作为综合性商城,包含多个工厂的品牌种类,因此成为月饼购买者的首选。
3
销量前十产品
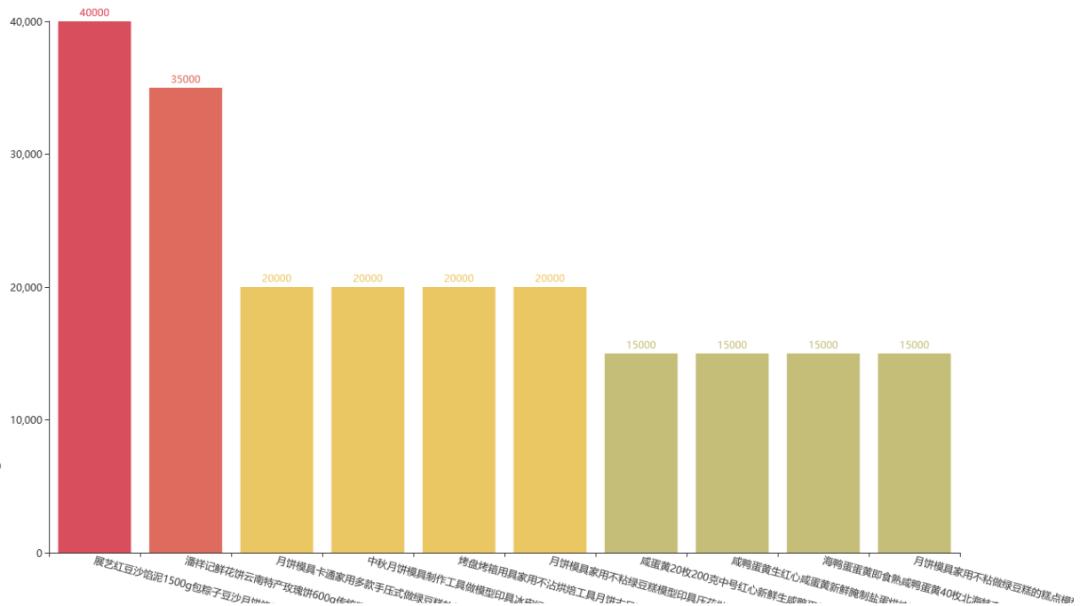
从单个销量前十的图中可以看到,非旺季时间排名第一的竟是月饼模具。出乎意料,排名第二的是鲜花月饼。
4
全国销量图(非旺季)
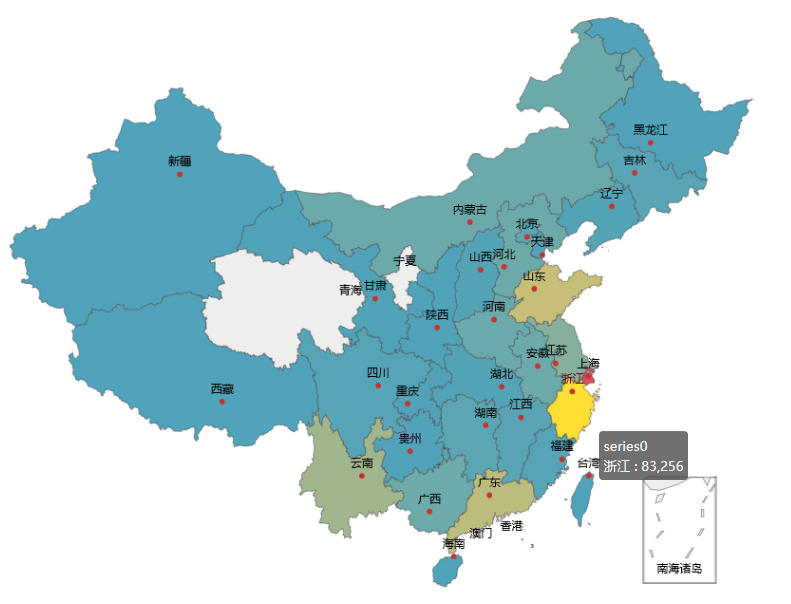
因为非旺季,月销量到2.5w的很少。只有上海地区的月销量有3.6w,而包邮省份江浙地区的销量仅有3w和5w,而四川和重庆地区的月销量只有5k和2k。
python代码
数据爬取:
代码块
# -*- coding: utf-8 -*-
from selenium import webdriver
import time
import csv
import re
# 搜索商品,获取商品页码
def search_product(key_word):
# 定位输入框 browser.find_element_by_id("q").send_keys(key_word)
# 定义点击按钮,并点击
browser.find_element_by_class_name('btn-search').click()
# 最大化窗口:为了方便我们扫码
browser.maximize_window()
# 等待15秒,给足时间我们扫码
time.sleep(15)
# 定位这个“页码”,获取“共100页这个文本”
page_info = browser.find_element_by_xpath('//div[@class="total"]').text
# 需要注意的是:findall()返回的是一个列表,虽然此时只有一个元素它也是一个列表。
page = re.findall("(\d+)",page_info)[0]
return page
# 获取数据
def get_data():
# 通过页面分析发现:所有的信息都在items节点下
items = browser.find_elements_by_xpath('//div[@class="items"]/div[@class="item J_MouserOnverReq "]')
for item in items:
# 参数信息
pro_desc = item.find_element_by_xpath('.//div[@class="row row-2 title"]/a').text
# 价格
pro_price = item.find_element_by_xpath('.//strong').text
# 付款人数
buy_num = item.find_element_by_xpath('.//div[@class="deal-cnt"]').text
# 旗舰店
shop = item.find_element_by_xpath('.//div[@class="shop"]/a').text
# 发货地
address = item.find_element_by_xpath('.//div[@class="location"]').text
#print(pro_desc, pro_price, buy_num, shop, address)
with open('{}.csv'.format(key_word), mode='a', newline='', encoding='utf-8-sig') as f:
csv_writer = csv.writer(f, delimiter=',')
csv_writer.writerow([pro_desc, pro_price, buy_num, shop, address])
def main():
browser.get('https://www.taobao.com/')
page = search_product(key_word)
print(page)
get_data()
page_num = 1
while int(page) != page_num:
print("*" * 100)
print("正在爬取第{}页".format(page_num + 1))
browser.get('https://s.taobao.com/search?q={}&s={}'.format(key_word, page_num*44))
browser.implicitly_wait(15)
get_data()
page_num += 1
print("数据爬取完毕!")
if __name__ == '__main__':
key_word = "月饼"
browser = webdriver.Chrome()
main()
数据处理和可视化:
代码块
# 导包
import pandas as pd
import numpy as np
import re
# 导入爬取得到的数据
df = pd.read_csv("月饼.csv", engine='python', encoding='utf-8-sig', header=None)
df.columns = ["商品名", "价格", "付款人数", "店铺", "发货地址"]
df.head(10)
# 去除重复值
df.drop_duplicates(inplace=True)
# 处理购买人数为空的记录
df['付款人数']=df['付款人数'].replace(np.nan,'0人付款')
# 提取数值
df['num'] = [re.findall(r'(\d+\.{0,1}\d*)', i)[0] for i in df['付款人数']] # 提取数值
df['num'] = df['num'].astype('float') # 转化数值型
# 提取单位(万)
df['unit'] = [''.join(re.findall(r'(万)', i)) for i in df['付款人数']] # 提取单位(万)
df['unit'] = df['unit'].apply(lambda x:10000 if x=='万' else 1)
# 计算销量
df['销量'] = df['num'] * df['unit']
# 删除无发货地址的商品,并提取省份
df = df[df['发货地址'].notna()]
df['省份'] = df['发货地址'].str.split(' ').apply(lambda x:x[0])
# 删除多余的列
df.drop(['付款人数', '发货地址', 'num', 'unit'], axis=1, inplace=True)
# 重置索引
df = df.reset_index(drop=True)
df.head(10)
#df.to_csv('清洗完成数据.csv')
df1 = df.sort_values(by="价格", axis=0, ascending=False)
df1.iloc[:5,:]
import jieba
import jieba.analyse
txt = df['商品名'].str.cat(sep='。')
# 添加关键词
jieba.add_word('粽子', 999, '五芳斋')
# 读入停用词表
stop_words = []
with open('stop_words.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
stop_words.append(line.strip())
# 添加停用词
stop_words.extend(['logo', '10', '100', '200g', '100g', '140g', '130g'])
# 评论字段分词处理
word_num = jieba.analyse.extract_tags(txt,
topK=100,
withWeight=True,
allowPOS=())
# 去停用词
word_num_selected = []
for i in word_num:
if i[0] not in stop_words:
word_num_selected.append(i)
key_words = pd.DataFrame(word_num_selected, columns=['words','num'])
import pyecharts
print(pyecharts.__version__)
# 导入包
from pyecharts.charts import Bar
from pyecharts import options as opts
# 计算top10店铺
shop_top10 = df.groupby('商品名')['销量'].sum().sort_values(ascending=False).head(10)
# 绘制柱形图
bar0 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar0.add_xaxis(shop_top10.index.tolist())
bar0.add_yaxis('sales_num', shop_top10.values.tolist())
bar0.set_global_opts(title_opts=opts.TitleOpts(title='月饼商品销量Top10'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),
visualmap_opts=opts.VisualMapOpts(max_=shop_top10.values.max()))
bar0.render("月饼商品销量Top10.html")
from pyecharts.charts import Map
# 计算销量
province_num = df.groupby('省份')['销量'].sum().sort_values(ascending=False)
# 绘制地图
map1 = Map(init_opts=opts.InitOpts(width='1350px', height='750px'))
map1.add("", [list(z) for z in zip(province_num.index.tolist(), province_num.values.tolist())],
maptype='china'
)
map1.set_global_opts(title_opts=opts.TitleOpts(title='各省份月饼销量分布'),
visualmap_opts=opts.VisualMapOpts(max_=300000),
toolbox_opts=opts.ToolboxOpts()
)
map1.render("各省份月饼销量分布.html")
from pyecharts.charts import Pie
def price_range(x): #按照淘宝推荐划分价格区间
if x <= 22:
return '22元以下'
elif x <= 115:
return '22-115元'
elif x <= 633:
return '115-633元'
else:
return '633元以上'
df['price_range'] = df['价格'].apply(lambda x: price_range(x))
price_cut_num = df.groupby('price_range')['销量'].sum()
data_pair = [list(z) for z in zip(price_cut_num.index, price_cut_num.values)]
print(data_pair)
# 饼图
pie1 = Pie(init_opts=opts.InitOpts(width='1350px', height='750px'))
# 内置富文本
pie1.add(
series_name="销量",
radius=["35%", "55%"],
data_pair=data_pair,
label_opts=opts.LabelOpts(formatter='{{b}—占比{d}%}'),
)
pie1.set_global_opts(legend_opts=opts.LegendOpts(pos_left="left", pos_top='30%', orient="vertical"),
toolbox_opts=opts.ToolboxOpts(),
title_opts=opts.TitleOpts(title='不同价格区间的月饼销量占比'))
pie1.render("不同价格区间的月饼销量占比.html")
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType
# 词云图
word1 = WordCloud(init_opts=opts.InitOpts(width='1350px', height='750px'))
word1.add("", [*zip(key_words.words, key_words.num)],
word_size_range=[20, 200],
shape=SymbolType.DIAMOND)
word1.set_global_opts(title_opts=opts.TitleOpts('月饼商品名称词云图'),
toolbox_opts=opts.ToolboxOpts())
word1.render("月饼商品名称词云图.html")
推荐阅读
(点击标题可跳转阅读)
转了吗 赞了吗 在看吗



评论