
初二学生写Python爬虫,爬取B站数据接口
1.初中生开发B站爬虫
B站爬虫,其实说简单是真的非常简单,它和正常的爬虫没有任何的区别,只是你需要调用一些他其他公开的接口就可以了,它的接口也是都是公开的。这个如果你学完了蚂蚁老师的课,我相信你肯定很快就可以写出来。我们废话不多说,直接来看代码

2.代码环节:
import csv#表格相关的库
import json#json库
import locale#locale库
import re#re库
import time#需要做延迟来防止被封ip所以我导入TIME库
import requests#爬虫相关的库
import configparser#configparser库
导入相关库 我需要导入到表格所以需要导入的库有点多
config = configparser.ConfigParser() # 类实例化
# 定义文件路径
f = open("数据文件.txt", encoding="utf-8")
f1 = f.read()
shuliang = re.search('!#!(.+?)@#@', f1).group(1)
dizhi = re.search('@#@(.+?)@!@', f1).group(1)
print(shuliang, dizhi)
获取由易语言生成出来的文件 =!#!22@#@C:\Users\Administrator\Desktop@!@ 这个是生成出来的 有2个数据 一个是运行目录还有一个是需要爬取的数量 我对数量进行了限制(在易语言上的限制 可以看到“如果真 (到整数 (编辑框1.内容) < 2 或 到整数 (编辑框1.内容) > 12)” 这个就是对他进行限制 在2和12的范围内)
##################################################
.版本 2
.如果真 (到整数 (编辑框1.内容) < 2 或 到整数 (编辑框1.内容) > 12)
信息框 (“建议不要超过12也不要小于2”, 0, , )
结束 ()
.如果真结束
.如果 (编辑框1.内容 = “”)
信息框 (“还未输入需要查询的数量”, 0, , )
.否则
写配置项 (取运行目录 () + “\数据文件.txt”, “”, “”, “!#!” + 编辑框1.内容 + “@#@” + 取运行目录 () + “@!@”)
写到文件 (取运行目录 () + “\py脚本1(查询+生成表格).exe”, #爬虫脚本py)
信息框 (“请等待黑色的框框消失即可 (-.-)”, 0, , )
运行 (取运行目录 () + “\py脚本1(查询+生成表格).exe”, 真, #普通激活)
.如果结束
.如果 (进程_是否存在 (“py脚本1(查询+生成表格).exe”))
.否则
删除文件 (取运行目录 () + “\py脚本1(查询+生成表格).exe”)
删除文件 (取运行目录 () + “\数据文件.txt”)
信息框 (“完成了 请在运行目录查看哦!”, 0, , )
结束 ()、
以上是易语言 生成出相关的配置文件让python去读取 来达到python和易语言交互的效果
####################################
headers = {'cookie': '{}',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/84.0.4147.105 Safari/537.36',
'referer': 'https://www.bilibili.com/v/fashion/makeup/?spm_id_from=333.5.b_7375626e6176.2',
'sec-fetch-dest': 'script',
'sec-fetch-mode': 'no-cors',
'sec-fetch-site': 'same-site'
}
def get_current_time(is_chinese=False):
if not is_chinese:
return time.strftime('%Y-%m-%d %H:%M:%S')
elif is_chinese:
locale.setlocale(locale.LC_CTYPE, 'chinese')
return time.strftime('%Y年%m月%d日%H时%M分%S秒')
进行对数据爬取
now_time = get_current_time(True)
def get_parse(result):
D = []
items = result['data']['list']
for item in items:
# 内容id
id = item['aid']
# 用户id
ids = item['owner']['mid']
# 用户昵称
name = item['owner']['name']
# 标题
title = item['title']
# 归属
tname = item['tname']
# 封面
pic = item['pic']
# 发布时间
times = item['pubdate']
timearray2 = time.localtime(times)
time2 = time.strftime('%Y-%m-%d', timearray2)
# 观看人数
view = item['stat']['view']
# 弹幕数
danmaku = item['stat']['danmaku']
# 点赞数
like = item['stat']['like']
# 投币数
coin = item['stat']['coin']
# 收藏数
favorite = item['stat']['favorite']
# 分享数
share = item['stat']['share']
# 评论数
reply = item['stat']['reply']
# 当前时间
time3 = time.strftime('%Y-%m-%d', time.localtime(time.time()))
data = [id, ids, name, title, tname, pic, time2, view, danmaku, like, coin, favorite, share, reply, time3]
print(data)
D.append(data)
save(D)
生成出表格 然后导入爬取下来的数据
def save(data):
with open(str(now_time) + '采集' + '.csv', 'a', newline='', encoding='gb18030') as file:
write = csv.writer(file)
write.writerows(data)
然后我们把这个文件生成出来
def main():
li = ['视频ID', '用户ID', '作者名字', '视频标题', '视频分区', '视频封面', '发布时间', '观看人数', '弹幕数量', '点赞数', '投币数量', '收藏数量', '分享数量', '评论数',
'当前时间']
with open(str(now_time) + '采集' + '.csv', 'a', newline='', encoding='gb18030') as file:
write = csv.writer(file)
write.writerow(li)
kks = shuliang
for i in range(1, int(kks)):
url = 'https://api.bilibili.com/x/web-interface/popular?ps=20&pn={}'.format(i)
print(url)
response = requests.get(url, headers=headers).text
result = json.loads(response)
get_parse(result)
# print()
# OK了 代码部分搞定了
把爬取下来的赋值 然后把数据给上面的内个导入表
我另外还写了个易语言的东西 因为我不会pyqt 他需要配合易语言才能完美运行 我已经把整个项目的所有源码全部都放到一个网盘上了 大家需要的话可以自取:https://www.aliyundrive.com/s/fbGcrnpMzjQ 由于百度网盘太慢了所以我用的是阿里云盘 我才疏学浅所以写代码可能有一些bug如果我发现都我都会更新的
#补充一下
我爬取下来的都是通过B站的一个公开的接口 这个接口上面的是没有排名的只有各种数据 所以爬取下来的顺序都是乱的 但是都是热门上面的 下面是表格的截图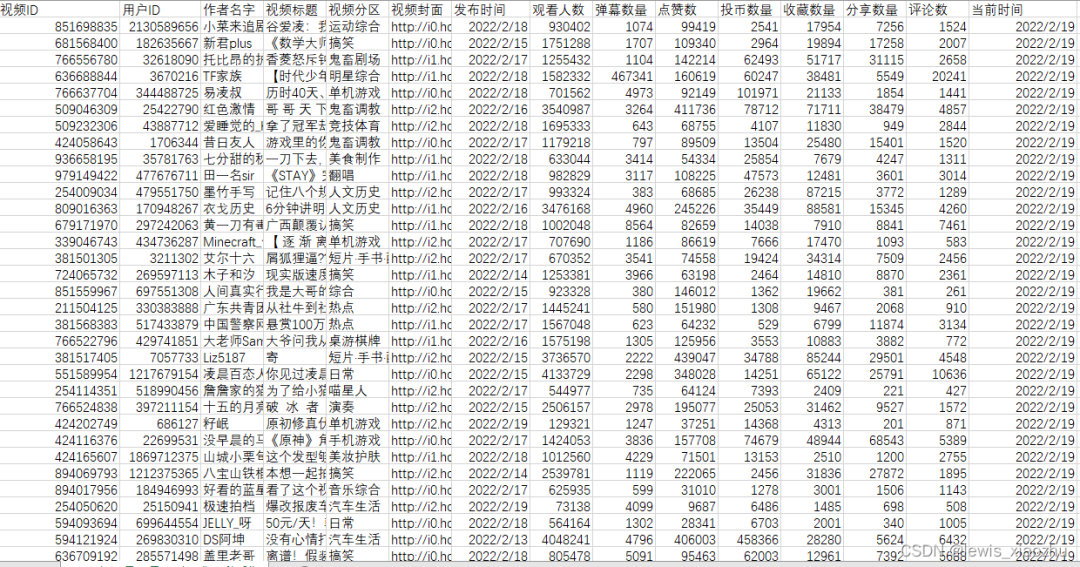
3.后言
肯定会有人问我一个初中生是怎么样学会这些代码的?而且在这么短的时间内就会学会这么多的知识并不是说我有什么超能力,只是努力加上一个好的老师,在这里啊,我就非常非常推荐蚂蚁老师,他的课干货十足,通俗易懂,可以非常快速的学会高级的知识!
最后,推荐蚂蚁老师的Python课程:
如果购买课程,加微信:ant_learn_python
找蚂蚁老师,进群、领资料