
如何在脱敏数据中使用BERT等预训练模型
前几天有朋友问了一下【小布助手短文本语义匹配竞赛】的问题,主要是两个;
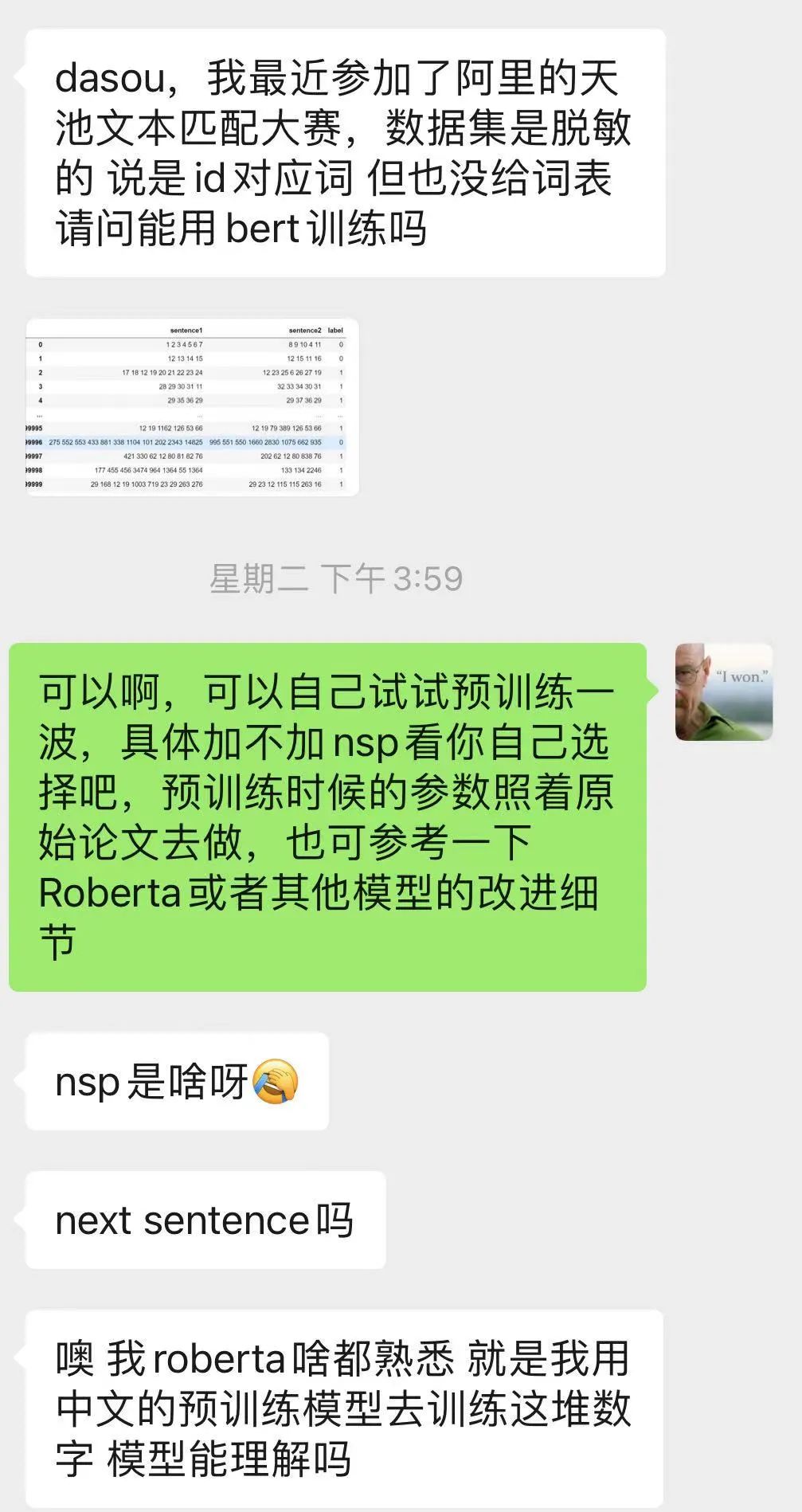
如何在脱敏数据中使用BERT;
基于此语料如何使用NSP任务;
比赛我没咋做,因为我感觉即使认真做也打不过前排大佬[囧],太菜了;不过我可以分享一下我自己的经验;
对于脱敏语料使用BERT,一般可以分为两种:
第一种就是直接从零开始基于语料训练一个新的BERT出来使用;
第二种就是按照词频,把脱敏数字对照到中文或者其他语言【假如我们使用中文】,使用中文BERT做初始化,然后基于新的中文语料训练BERT;
大家可以先看一下当时我的回复:
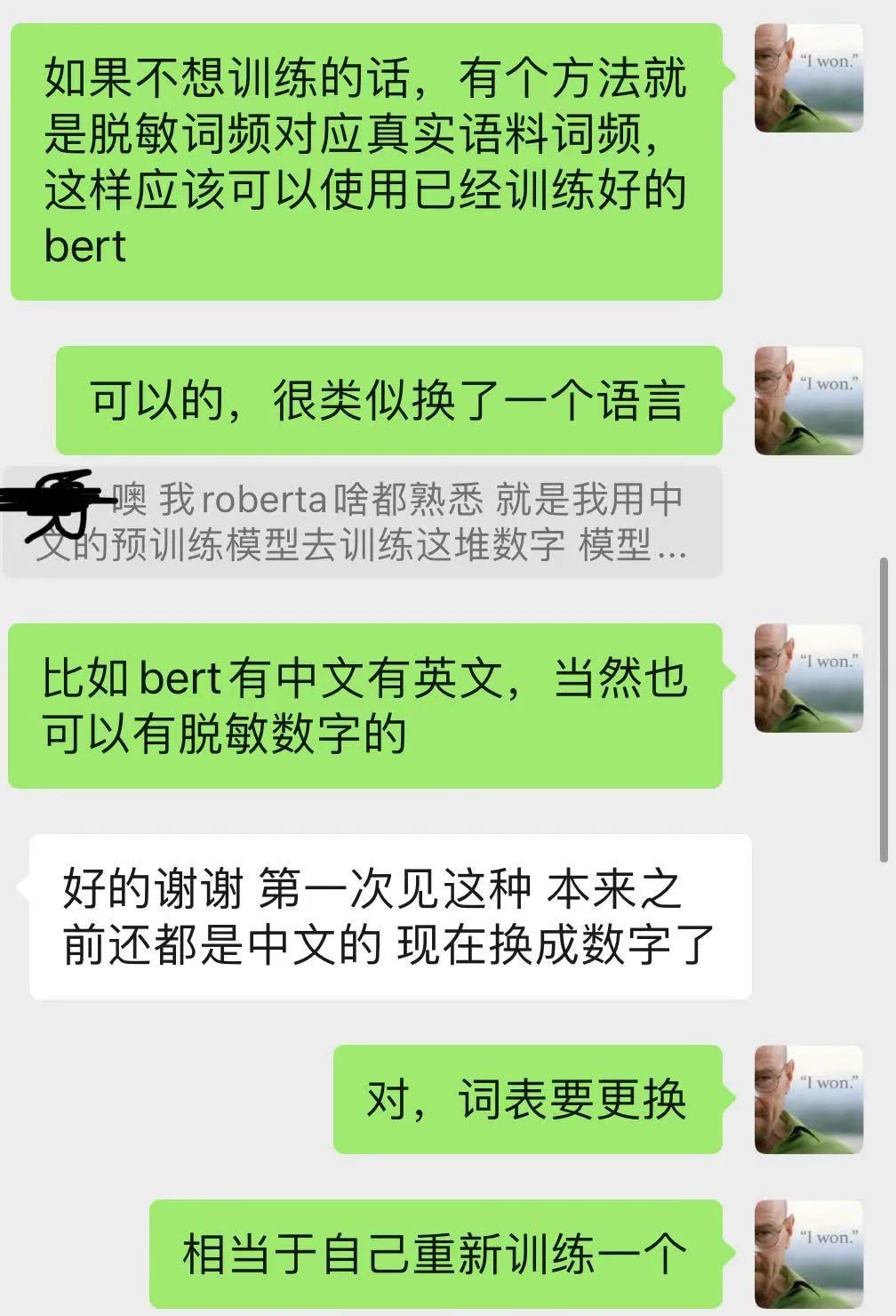
然后我发现很多朋友对于预训练模型其实理解的还是不深刻,很疑惑为什么在脱敏数据中也可以训练BERT等预训练模型;
其实这一点很容易理解,就像我截图中说到的:
最开始BERT是用英文语料训练出来的,然后有朋友基于中文语料开源了中文的BERT;
那么我的脱敏数字就是类似于中文的一种另外的语言,你可以看成是【X】语言,我们当然可以基于【X】语言的语料去训练一个新的BERT或者其他的预训练模型了;
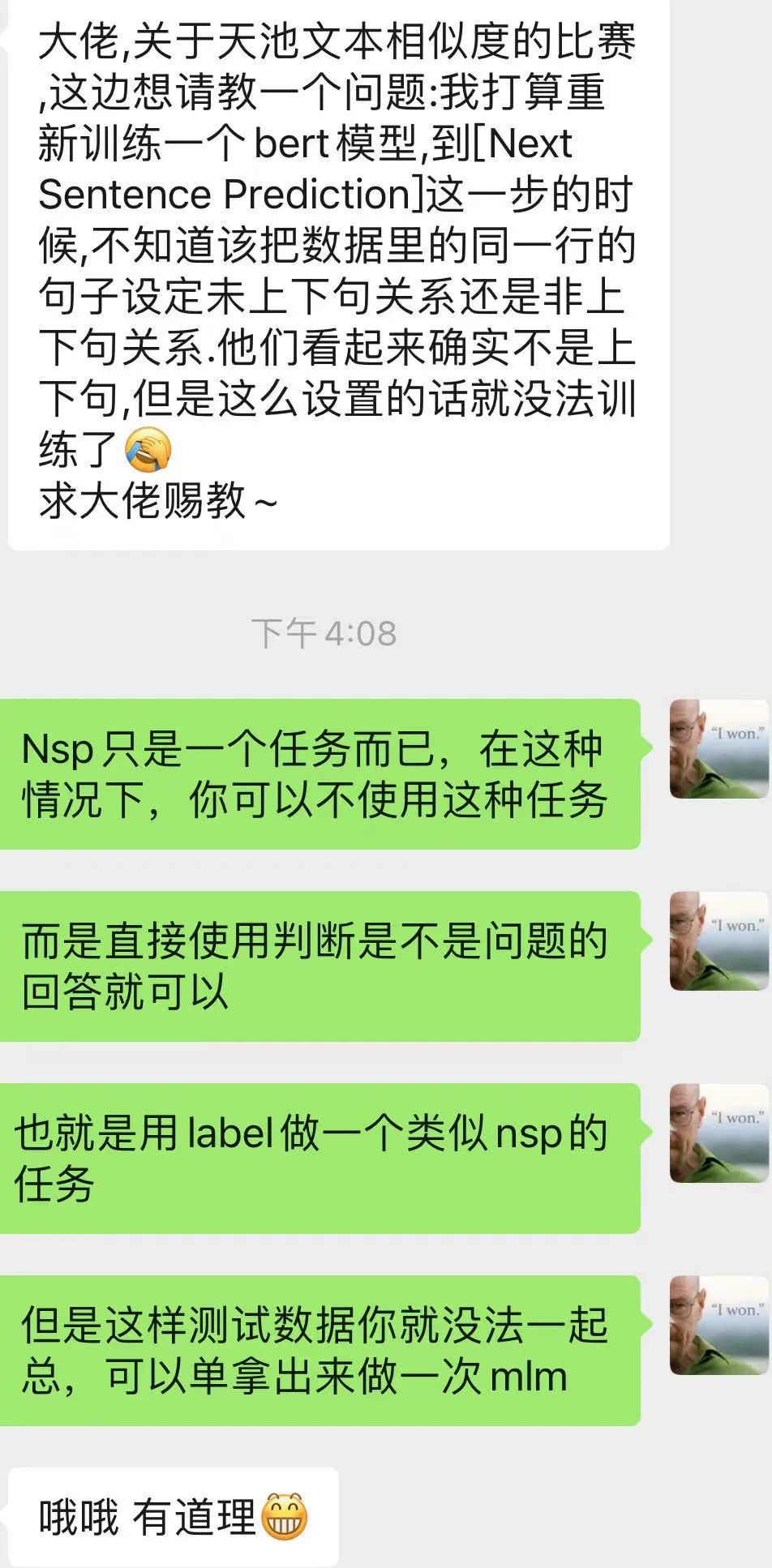
有的朋友谈到了NSP任务如何去使用的问题;
很明显,在当前这个任务中是一个文本匹配的形式;
语料不是我们自己有主动的去获取的能力,所以构造一个NSP任务的格式比较困难;
但是NSP任务仅仅是一种任务形式,我们完全可以基于训练语料构造一个是否匹配的任务,可以称之为类NSP任务;
基于此,测试数据是使用不了的,因为测试数据没有label;
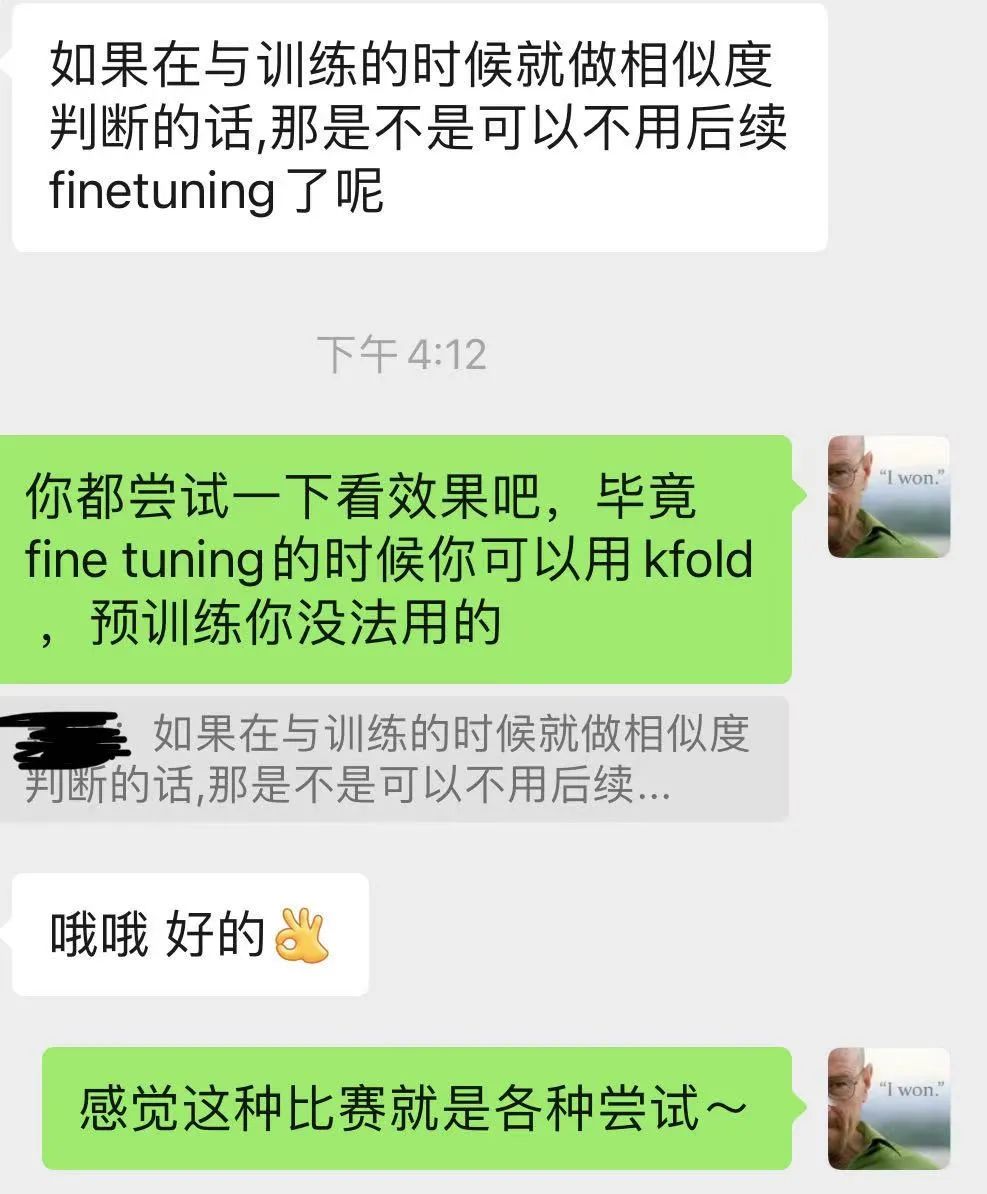
不过,我自己认为可以测试数据使用MLM任务,训练数据使用MLM+类NSP任务;
更加具体大家可以看我当时的回复:
评论