
Convolutional stem is all you need! 探究ViT优化不稳定的本质原因

极市导读
本文证明了ViT模型的优化不稳定是由于ViT的patchify stem的非常规大步长、大卷积核引起的。仅仅通过将ViT的patchify stem修改成convolutional stem,就能够提高ViT的稳定性和鲁棒性,非常的简单实用。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
之前的一些研究发现,ViT的优化要求十分苛刻,不仅需要精确的learning rate和weight decay,还需要使用AdamW优化器,并且收敛非常的慢。其中最近的MoCov3中提到ViT架构会导致训练过程中出现衰退现象。
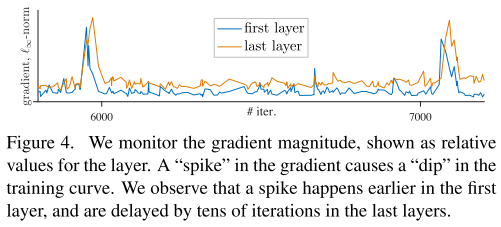
MoCov3通过绘制first layer和last layer的梯度范数,发现first layer的尖峰出现的比last layer更早,从而推测出patch projection是产生衰退的关键,于是通过固定住patch projection(即本文的patchify stem)的参数,缓解了衰退现象。
相比之前hybrid CNN/ViT的研究,本文的重点是探究ViT优化不稳定的本质原因,convoluational stem替换patchify stem对于ViT优化稳定性的影响。
本文发现,用convoluational stem替换patchify stem后,大约使用5个convolution就可以在SGD优化器上优化,精度不会大幅度下降,并且对于learning rate和weight decay参数不敏感,训练的收敛速度更快。另外,在模型复杂性(1G到36G)和数据集规模(ImageNet-1k到ImageNet-21k)的大范围内,ImageNet的top-1精度可以持续提升。
Early convolutions help transformers see better
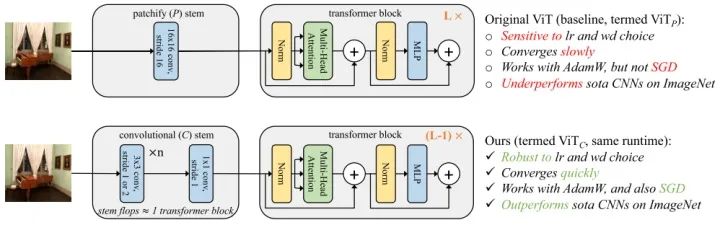
ViT_P原始的ViT将输入图片划分成无重叠的pxp个patch,然后对每个patch进行patch projection转化成d为的feature vector。假设输入的图片尺寸为224x224,每个patch的尺寸为p=16,那么patch的数量为14x14,patch projection等价于一个16x16大小,步长为16的大卷积核。本文为了方便起见,将ViT构造成1GF,2GF,4GF,8GF等设置,记作 模型。本文将ViT的patchify stem替换成convolutional stem,记作 模型。
Convolutional stem design
为了跟patchify stem的输出维度对齐,convolutional stem通过3x3卷积快速下采样到14x14。具体的,设置4个3x3大小,步长为2的卷积和一个1x1,步长为1的卷积,至少需要5个卷积,convolutional stem的输出可以和patchify stem的输出维度保持一致。为了使 和 总体计算量保持一致, 通过改变通道数保证convolutional stem的计算量约等于1个 transformer block,然后减去后面的一个transformer block。

如表格所示,左边是 模型,右边是 模型,左右按行保持计算量近似相等。左边蓝色数字表示 相比于原始ViT的修改,右边的蓝色表示 相较于 移除1个transformer block的修改。
核心实验
本文通过3个稳定性实验,一个最佳性能实验完美展现了convolutional stem相较于patchify stem的优越性。4个结论:
1. 收敛更快
2. 可以使用SGD优化
3. 对learning rate和weight decay更稳定
4. 在ImageNet上提升了1-2个点
Training Length Stability
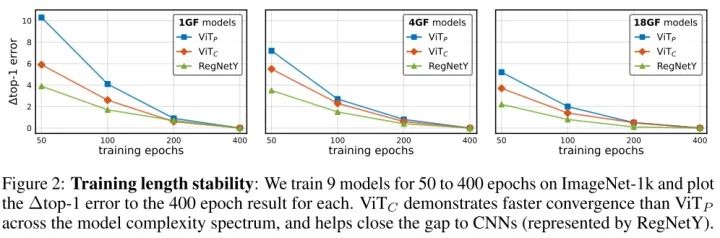
比起 , 的收敛速度更快。
Optimizer Stability
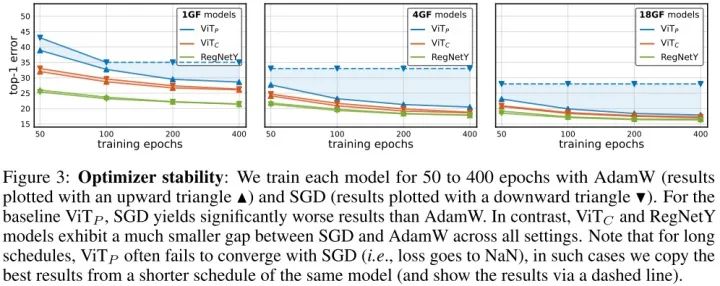
无论是AdamW还是SGD优化器,都能够稳定收敛。
Learning Rate and Weight Decay Stability
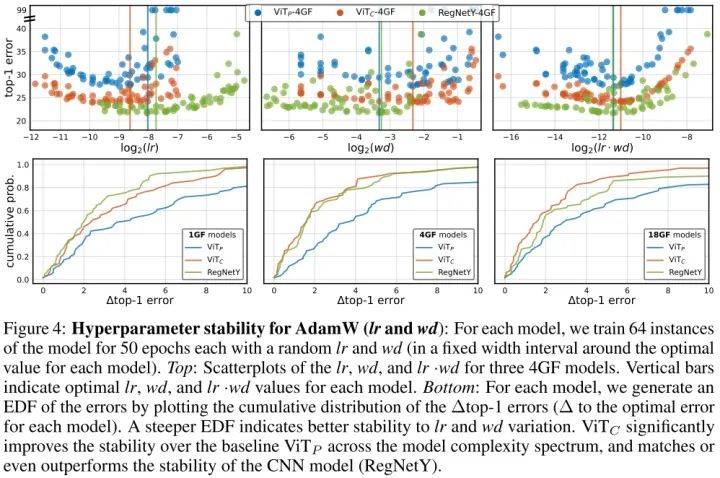
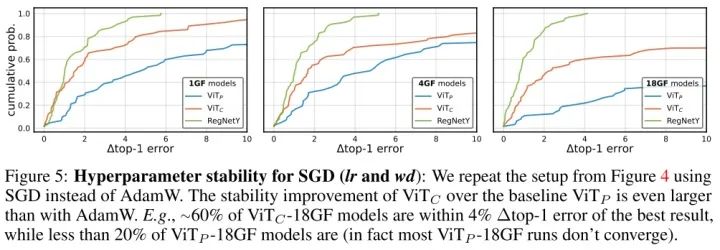
在改变learning rate和weight decay时,训练的稳定性都比 要好,并且跟CNN接近。
Peak Performance
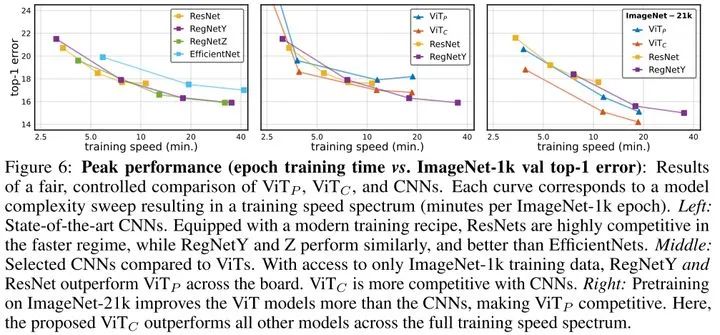
的最优性能都要优于 ,在ImageNet-1k时, 最优性能略差于RegNet,但是在ImageNet-21k时, 和 的最优性能都要好于RegNet。这也说明了大数据量下ViT更有优势。
总结
本文证明了ViT模型的优化不稳定是由于ViT的patchify stem的非常规大步长、大卷积核引起的。仅仅通过将ViT的patchify stem修改成convolutional stem,就能够提高ViT的稳定性和鲁棒性,非常的简单实用。但是为什么convolutional stem比patchify stem更好,还需要进一步的理论研究。最后作者还提到72GF的模型虽然精度有所改善,但是仍然会出现一种新的不稳定现象,无论使用什么stem,都会导致训练误差曲线图出现随机尖峰。
本文看似简单,但是如果能够找到Vison Transformer容易优化的通用方法是非常有意义的,ResNet就是找到了CNN容易优化的通用方法。
本文还有一句潜台词是,把ViT的patchify stem替换成convolutional stem,你们还可以继续刷点。
Reference
[1] Early Convolutions Help Transformers See Better
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
