
原因的原因不是原因,结果的结果不是结果

导读:人生难料,世事无常,大多是“原因”和“结果”之间的纠缠。

01
故事A
某地空气极好,但是当地死于呼吸系统疾病的患者数量,却名列全国前几位。
故事B
我有个亲戚,开服装厂,行业每况愈下,总说要关门。去年底好容易接了几个大单,年初因为疫情,订单被砍掉了一大半!
A面:我们应该看得更长远; B面:我们应该立足当下,做好眼前的事情。

假设有人吓走了一只鸽子。 鸽子飞走的时候,惊到了一位正在穿越街道的路人。 路人驻足观望,结果导致一辆正在朝他骑过来的自行车不得不在最后一秒急转车头。 自行车避让行人后,正好骑到了一辆出租车行驶的车道上。 出租车为了避让自行车,结果撞上了一个消防栓。 消防栓出水导致附近一栋大楼的地下室被淹,破坏了地下室的供电设施。
虽然吓走鸽子是启动整个原因链的原因,我们也可以认为是吓走鸽子这件事导致了后面的一系列事件,但很少有人会认为吓走鸽子的那个人应该对之后出现的一系列事件负责——即使很多人都同意是那个人引起了这一系列的事件。
一只蝴蝶在巴西轻拍翅膀,可以导致一个月后德克萨斯州的一场龙卷风。

若一个经济学的特性被用作经济指标,那这项指标最终一定会失去其功能,因为人们会开始玩弄这项指标。

人类对因果的“幻觉”; 误将“相关性”当作“因果性”; 因果之间距离过大; 混淆了原因和结果; 对条件概率的混乱; 人类的无知和科学的局限; 过于依赖确定性; “自上而下”的习惯思维。
虽然我们能观察到一件事物随着另一件事物而来,我们却并不能观察到这两件事物之间的关联。
我们无从得知因果之间的关系,只能得知某些事物总是会连结在一起,而这些事物在过去的经验里又是从不曾分开过的。 我们并不能看透连结这些事物背后的理性为何,我们只能观察到这些事物的本身,并且发现这些事物总是透过一种经常的连结而被我们在想像中归类。

已知:美国400万被虐待的妻子中只有1432名被其丈夫杀死。 所以:辛普森杀死妻子的概率只有1432/400万,即1/2500。 因此:辛普森杀死妻子的概率是非常低的事件,即辛普森几乎不可能杀死他的妻子。
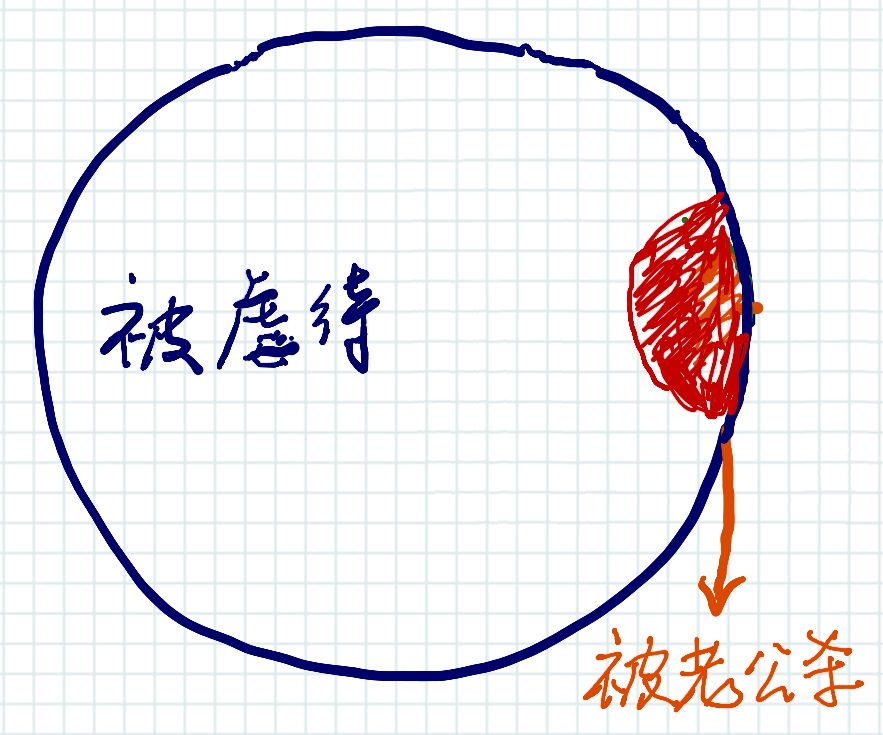
因为我们讨论的是被谋杀的被虐待妻子,所以绿色圆圈被包含在蓝色圆圈内; 因为并不是所有被谋杀的妻子都是被丈夫杀害的,所以红色圆圈被包含在绿色圆圈内,“问号”部分表示那些被别人谋杀的被丈夫虐待的妻子。

由于不正确的假设、错误的因果联系、输入的噪声多于数据,以及未被预测到的人为因素,经济模型经常遭遇反复失败。预测被证明是不准确的。模型总是会低估风险,从而导致金融危机的爆发。
一种是理解不确定性的; 一种是不理解不确定性的。
首先《人生算法》是一本关于不确定性的书; 其次为什么有人愿意相信花几十块钱买本书可以“确保”人生富足?(别信图书封面......)
人们对于需要追求确定性的事情,例如投资,以及一些关乎幸福的关键决策,往往不假思索。 反倒对那些无法预料、需要伸手去触碰的事情思前想后。

演变就发生在我们身边。它是理解人类世界和自然世界如何变化的最佳途径。 人类制度、人工制品和习惯的改变,都是渐进的、必然的、不可抵挡的。
它遵循从一个阶段进入下一个阶段的叙述方式; 它慢慢推进而非大步跳跃; 它有自己自发的势头,不为外部所推动; 它心里没有什么目标,也没有具体的终点; 它基本上是靠试错产生的,而试错是自然选择的一种形式。
促使眼睛总对光做出反应的“视蛋白”分子,可以追溯到所有动物的共同祖先身上(海绵类动物除外)。 大约7亿年前,视蛋白基因复制了两次,产生了我们今天拥有的3种感光分子。 故此,眼睛演变的每一个阶段,从感光分子的发展、透镜和色觉的自然形成,都可以从基因的语言里直接读取。

极其复杂,棋局变化的可能性约等于2.08x10^170种,比整个宇宙里的原子数量还要多很多。 棋子都是一样的,反而更难评估优劣。 象棋越下棋子越少,围棋越下棋子越多。 围棋既有局部精确的计算,又有宏观局面模糊的判断。
围棋中没有等级概念,所有棋子都一样,围棋是筑防游戏,因此需要盘算未来。你在下棋的过程中,是棋盘在心中,必须要预测未来。小小一个棋子可撼动全局,牵一发动全身。



围棋棋子除了颜色以外,完全一样,不像象棋那样分帅车兵马。 另外,围棋的棋子,落下之后就不能移动。 围棋棋子的效率和价值,是由棋子之间的空间关系而决定的。 就像搭宜家家具或者乐高玩具,即使空间位置对了,但如果顺序错了,也不行。
抛硬币的结果并不取决于以前抛硬币的结果,所以这不是马尔可夫理想的模型。 但是,如果增加一点依赖关系,使下一个事件取决于刚刚发生了什么,而不是整个系统如何影响了当前事件,又会怎么样呢? 每个事件的概率仅取决于先前事件的一系列事件被称为马尔可夫链。 预测天气就是一个例子:明天的天气肯定取决于今天的天气,但并不特别依赖于上周的天气。
马尔可夫模型构建的意义,是为了探寻未来的最优策略,以及马尔可夫性与历史总是不相关的,仅与当前状态有关。所以一切模型构建均是围绕未来进行展开的。 (本段来自网络)
起始状态是一个空的棋盘,棋手根据棋面(状态)选择落子点(动作)后,转换到下一个状态(转换概率为:其中一个状态的概率为 1,其他状态的概率为 0),局势的优劣是每个状态的回报。棋手需要根据棋面选择合适落子点,建立优势并最终赢下游戏。 (本段来自刘思乡)
环境可以是真实世界,电脑游戏,模拟,甚至棋盘游戏,比如围棋或象棋。就像人类一样,人工智能代理人从其行为的结果中学习,而不是从明确的教导中学习。 在深度强化学习中,智能体是由神经网络表示的。神经网络直接与环境相互作用。它观察环境的当前状态,并根据当前状态和过去的经验决定采取何种行动(例如向左、向右移动等)。根据采取的行动,AI智能体收到一个奖励(Reward)。奖励的数量决定了在解决给定问题时采取的行动的质量(例如学习如何走路)。智能体的目标是学习在任何特定的情况下采取行动,使累积的奖励随时间最大化。
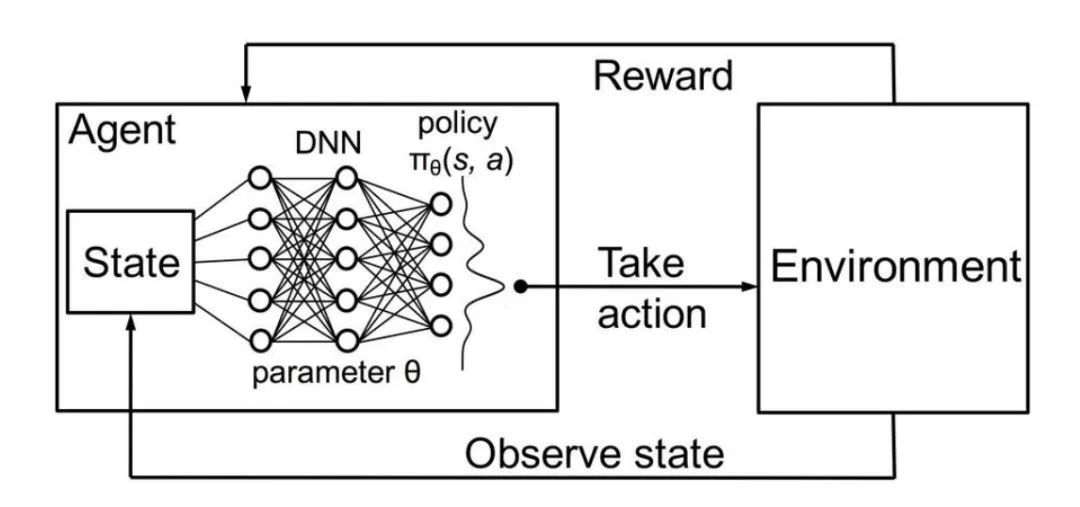
阿尔法狗每下的一盘棋,都是一次自我进化的学习过程,工作即学习,学习即工作; 阿尔法狗的唯一目标是终局胜负,因此而有强烈的使命感,钢铁般的意志,和石佛般的平常心(尽管它不需要这些形容词); 把每一手棋,都当作一个独立决策点,将当前的整个局面视为一个初始状态,根据当前局面,发现(模仿人的直觉)获胜概率较高的几手棋,并估算每一手棋的终局胜率; 从中选择最优决策; 等对方落子后,再次进入“初始状态”,根据更新的信息,重复以上动作,直至终局。
围棋应该自由舒展,妙趣横生地下。因此,我觉得应该把整个棋盘当做自己的舞台。

很长一段时间, 我的生活看似马上就要开始了, 真正的生活, 但是总有一些障碍阻挡着, 有些事得先解决, 有些工作还有待完成, 时间貌似够用, 还有一笔债务要去付清, 然后生活就会开始, 最后我终于明白, 这些障碍, 正是我的生活。
有死之人的思想必须让自身没入深深泉源的黑暗中,以便在白天能看到星星。
黑暗有黑暗的清澈,不过我们没有洞悉黑暗的眼睛。于是我们点亮了烛光,企图照亮整个宇宙。 然而,我们越来越固执于光明,在此光明中营造自己的家园,反而遗忘了那深不可测无边无际的黑暗,遗忘了我们本源的家。

延伸阅读《天才与算法》
推荐语:美、英两国双料院士马库斯·杜·索托伊先生作品。我们即将进入一个由算法主导世界,AI将在绘画、音乐、写作等向人类发起挑战,作者用数学帮我们理解算法及创造力的本质。
干货直达👇
评论