
(附论文)CVPR2021:上下文和注意力机制提升小目标检测
点击左上方蓝字关注我们

论文:
https://arxiv.org/pdf/1912.06319.pdf
1
简要

2
背景


3
新框架分析
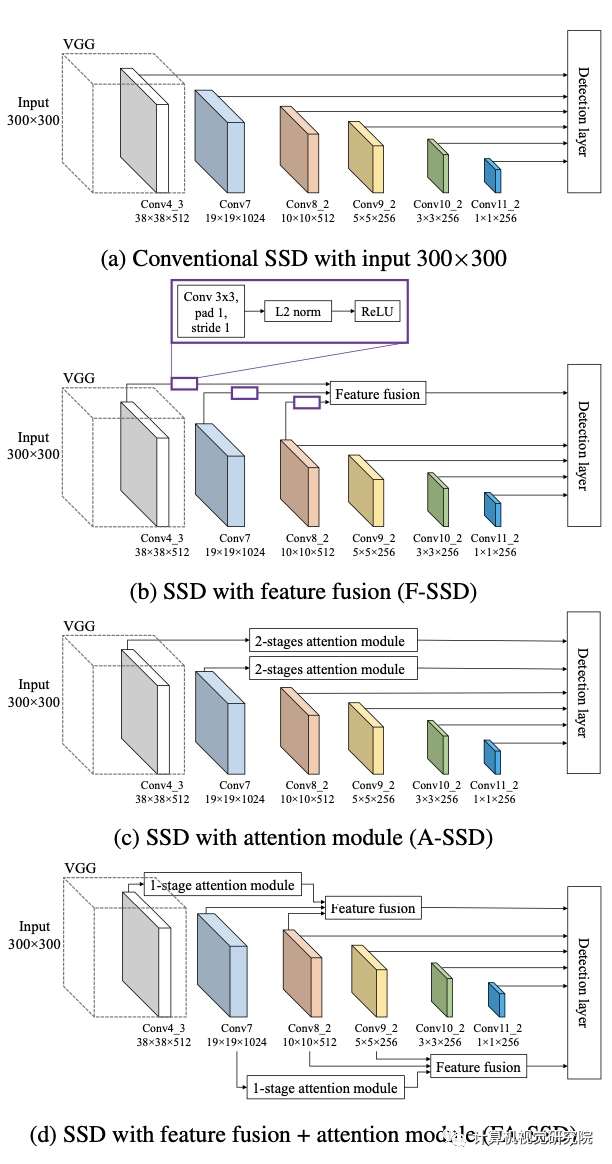
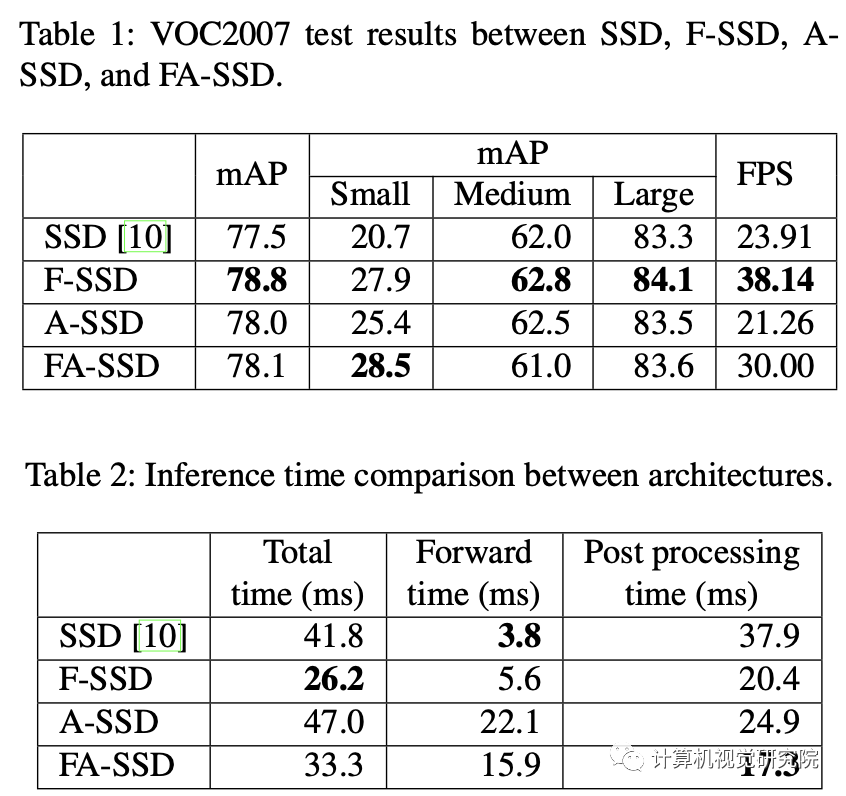
F-SSD: SSD with context by feature fusion
为了为给定的特征图(目标特征图)在我们想要检测目标的位置提供上下文,研究者将其与目标特征层更高层次的特征图(上下文特征)融合。例如,在SSD中,给定我们来自conv4_3的目标特性,我们的上下文特征来自两层,它们是conv7和conv8_2。
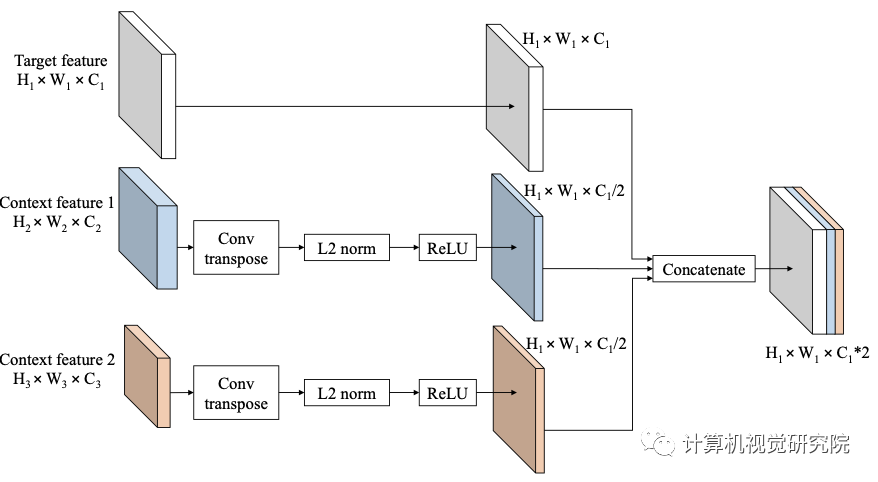
虽然新框架的特征融合可以推广到任何目标特征和任何更高的特征。然而,这些特征图具有不同的空间大小,因此研究者提出了如上图所示的融合方法。在通过连接特征进行融合之前,对上下文特征执行反卷积,使它们具有与目标特征相同的空间大小。将上下文特征通道设置为目标特征的一半,因此上下文信息的数量就不会超过目标特征本身。仅仅对于F-SSD,研究者还在目标特征上增加了一个额外的卷积层,它不会改变空间大小和通道数的卷积层。
此外,在连接特征之前,标准化步骤是非常重要的,因为不同层中的每个特征值都有不同的尺度。因此,在每一层之后进行批处理归一化和ReLU。最后通过叠加特征来连接目标特征和上下文特征。
A-SSD: SSD with attention module
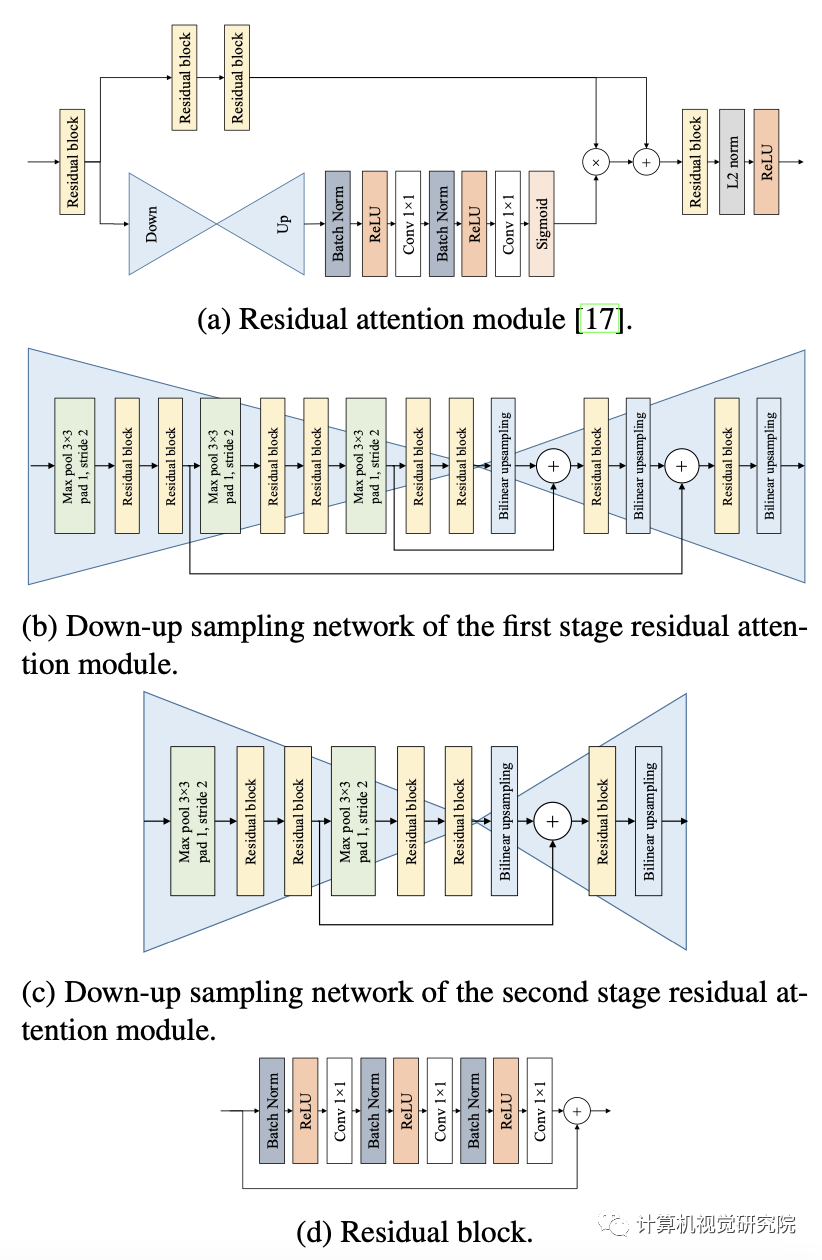
如上图,它由一个trunk分支和一个mask分支组成。trunk分支有两个残差块,每个块有3个卷积层,如上图d所示;mask分支通过使用残差连接执行下采样和上采样来输出注意图(图b为第一阶段和图c为第二阶段),然后完成sigmoid激活。残差连接使保持下采样阶段的特征。然后,来自mask分支的注意映射与trunk分支的输出相乘,产生已参与的特征。最后,参与的特征之后是另一个残差块,L2标准化,和ReLU。
tion in SSD
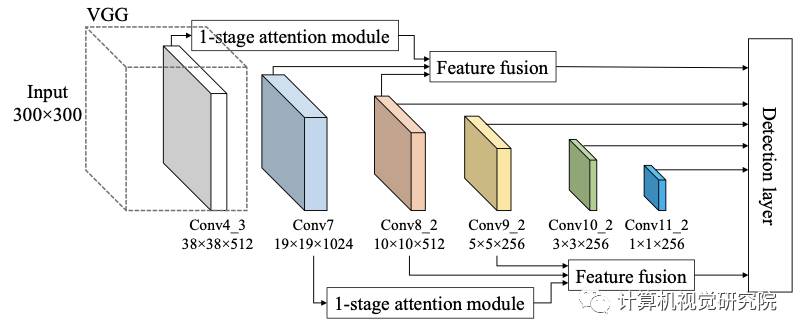
研究者提出了以上的两个特征的方法,它可以考虑来自目标层和不同层的上下文信息。与F-SSD相比,研究者没有在目标特征上执行一个卷积层,而是放置了one stage的注意模块,如下图所示。
4
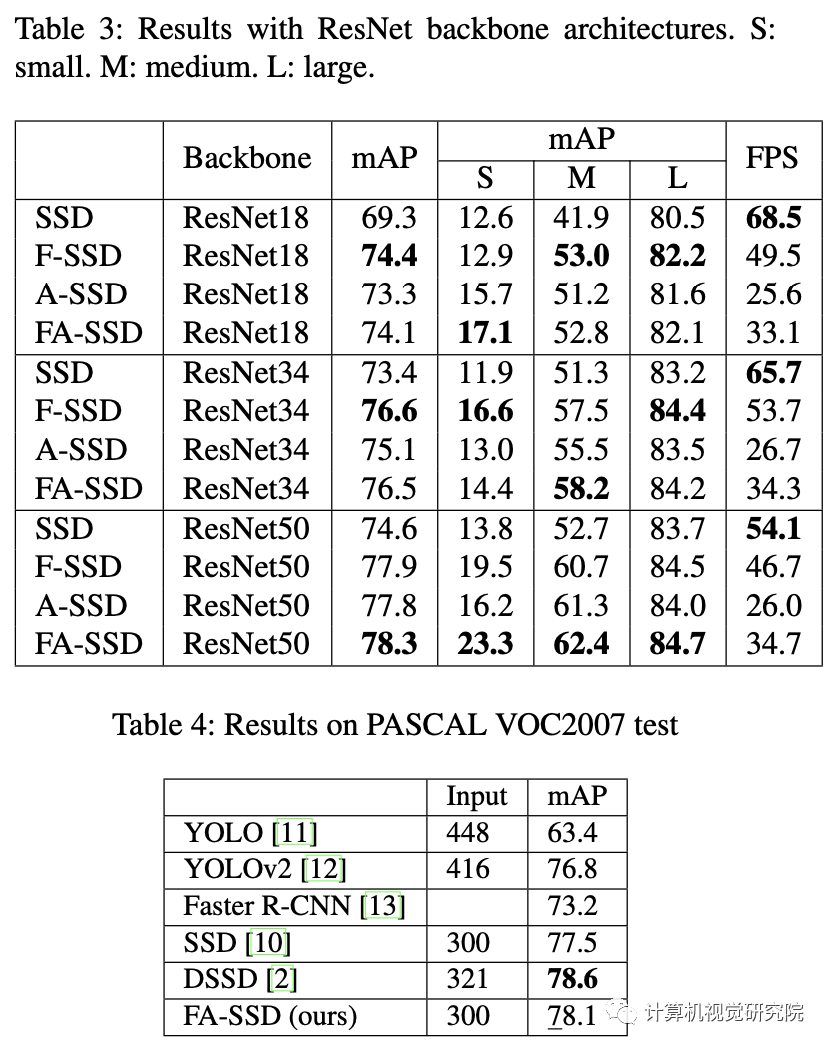
实验
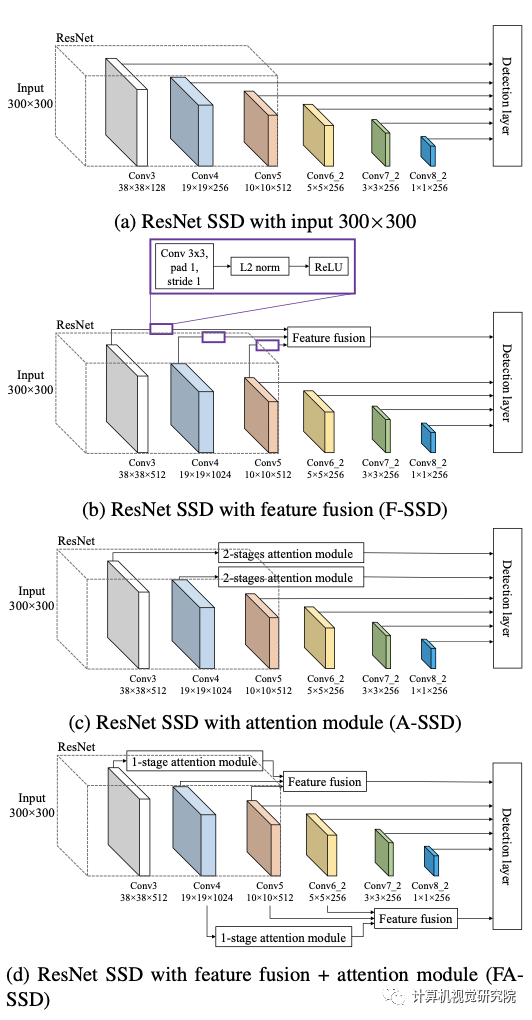
ResNet SSD with feature fusion + attention module (FA-
SSD)

红色框是GT,绿色框是预测的

END
整理不易,点赞三连↓