
微软提出MiniViT | 把DeiT压缩9倍,性能依旧超越ResNet等卷积网络


Vision Transformer由于其较高的模型性能在计算机视觉领域受到广泛关注。然而,Vision Transformer受到大量参数的影响,限制了它们在内存有限的设备上的适用性。为了缓解这一问题,本文提出了一种新的压缩框架MiniViT,MiniViT能够在保持相同性能的同时实现了Vision Transformer的参数缩减。
MiniViT的核心思想是将连续Vision TRansformer Block的权重相乘。更具体地说,使权重跨层共享,同时对权重进行转换以增加多样性。Weight distillation也被应用于将知识从Large-scale ViT模型转移到权重复用的紧凑模型。综合实验证明了
MiniViT的有效性,MiniViT可以将预训练的Swin-B Transformer的尺寸减少48%,同时在ImageNet上Top-1准确率提高了1.0%。此外,使用单层参数,MiniViT能够将DeiT-B压缩9.7倍,从86M到9M的参数,而不会严重影响性能。最后,通过MiniViT在下游基准上的性能来验证其可迁移性。

1简介
大规模预训练的Vision TRansformer,如ViT, CvT和Swin,由于其高性能和下游任务的优越性能,最近引起了极大的关注。然而,它们通常涉及巨大的模型尺寸和大量的训练数据。例如,ViT需要使用3亿张图像来训练一个带有6.32亿参数的巨大模型,才实现了图像分类的最先进性能。同时,Swin使用2-3亿个参数,并在ImageNet-22K上进行了预训练,以在下游检测和分割任务上取得良好的性能。
数以亿计的参数消耗了相当大的存储和内存,这使得这些模型不适合涉及有限计算资源的应用程序,如边缘和物联网设备,或者需要实时预测的任务。最近的研究表明,大规模的预训练模型是过度参数化的。因此,在不影响这些预训练模型性能的情况下,消除冗余参数和计算开销是必要的。
权重共享是一种简单且有效的减少模型尺寸的技术。神经网络中权重共享的最初想法是在20世纪90年代由LeCun和Hinton提出的,最近被重新发明用于自然语言处理(NLP)中的Transformer模型压缩。最具代表性的工作是ALBERT,它引入了一种跨层权重共享的方法,以防止参数的数量随着网络深度的增加而增长。该技术可以在不严重影响模型性能的情况下显著降低模型尺寸,从而提高参数效率。然而,Weight sharing在Vision Transformer压缩中的有效性尚未得到很好的探索。
为了验证这一点,作者在DeiT-S和Swin-B Transformer上执行跨层权重共享。出乎意料的是,这种直接使用权重共享带来了2个严重的问题:
训练不稳定:作者观察到,
Weight sharing across transformer layers使训练变得不稳定,甚至随着共享层数量的增加,导致训练坍塌;性能下降:
权重共享Vision Transformer的性能与Vision Transformer相比有明显下降。例如,虽然权重共享可以将模型参数的数量减少4倍,但是它还是带来了Swin-s Transformer精度下降5.6%,。
为了调查这些结果的潜在原因,作者分析了训练过程中梯度的ℓ2-范数以及模型权重前后的中间特征表征之间的相似性。作者发现,在不同层上完全相同的权重是问题的主要原因。特别是,在权重共享过程中,不同Transformer Block中的层归一化不应该完全相同,因为不同层的特征具有不同的尺度和统计量。同时,梯度的ℓ2-范数变大,并在不同层间波动,导致训练不稳定。
最后,Central Kernel Alignment(CKA)值(一个流行的相似性度量)在最后几层显著下降,表明模型在权重共享前后生成的特征图相关性较小,这可能是性能下降的原因。
在本文中提出了一种新的技术,称为Weight Multiplexing,来解决上述问题。Weight Multiplexing由Weight Transformation和Weight Distillation两个组件组成,共同压缩预训练好的Vision Transformer。
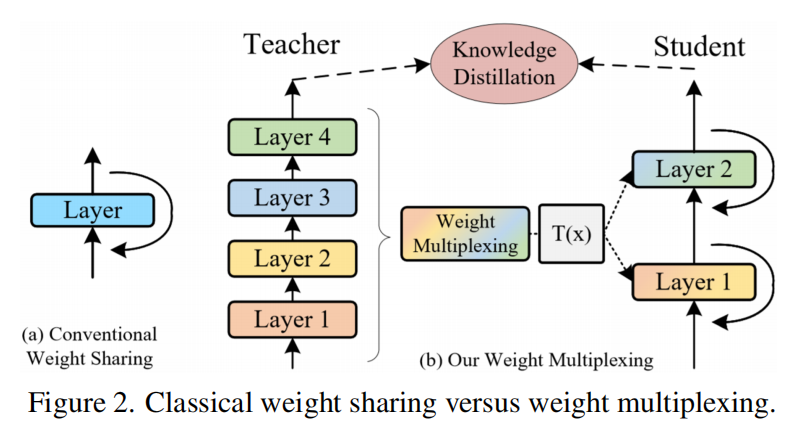
Weight Transformation的关键思想是对共享的权值进行转换,使不同层的权值略有不同,如图2所示。该操作不仅可以促进参数的多样性,而且还可以提高训练的稳定性。
更具体地说,对每个权重共享Transformer Layer的多头自注意力(MSA)模块和多层感知器(MLP)模块进行了简单的线性变换。每一层都包含单独的变换矩阵,因此MLP对应的注意力权重和输出在不同层间是不同的。与共享相同的参数相比,不同层的层归一化也是分开的。因此,可以让Weight Sharing Transformer网络的优化变得更加稳定。
为了防止性能下降,作者进一步用Weight Distillation设计了Weight Multiplexing,这样嵌入在预训练的模型中的信息可以转移到权重共享的小模型中,这就可以产生更紧凑和更轻的模型。与之前仅依赖于Prediction-Level蒸馏的工作相比,本文的方法同时考虑了Attention-Level和Hidden-State蒸馏,允许较小的模型更好地模拟原始预训练的大型教师模型的行为。
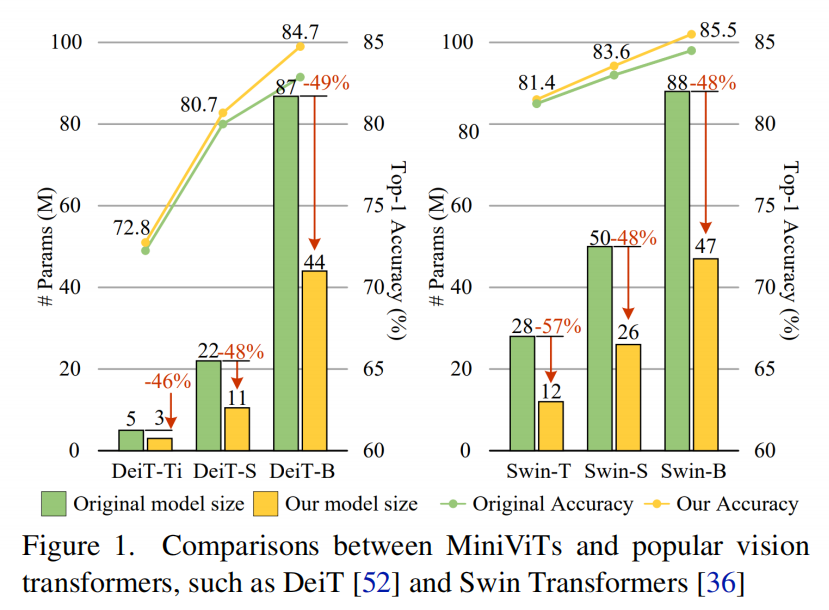
实验表明,Weight Multiplexing方法在Baseline上实现了明显的精度提高,并将预训练好的Vision Transformer压缩了2倍。例如,通过提出的Weight Multiplexing,12层的Mini-Swin-B模型比24层Swin-B高0.8%。此外,具有9M参数的MiniDeiT-B在ImageNet上达到了79.8%的Top-1位精度,比DeiT-B小9.7倍。用本文的方法压缩得到的12M微型模型可以很好地迁移到下游目标检测,在COCO验证集上实现了48.6的AP,这与使用28M参数的原始Swin-T相当。
主要贡献
系统地研究了
权重共享在Vision Transformer中的有效性,并分析了权重共享带来问题的原因;提出了一种新的通用
Vision Transformer压缩框架MiniViT。实验结果表明,MiniViT可以在不损失精度的前提下获得较大的压缩比。此外,MiniViT的性能也可以很好地迁移到下游任务。
2师从何处?
2.1 Vision Transformer
Transformer虽然最初是为NLP设计的,但最近在计算机视觉方面也显示出了巨大的潜力。Vision Transformer首先将输入图像分割成一系列被称为Token的2D Patch。然后,使用线性投影或堆叠的CNN层将这些Patch展开并转换为d维向量(也称为Patch Embeddings)。为了保留位置信息,Positional Embeddings被添加到Patch Embeddings中。然后将组合的Embeddings输入到Transformer编码器。最后,使用一个线性层来产生最终的分类。
Transformer编码器由MSA和MLP的交替组成。在每个块前后分别应用层归一化(LN)和残差连接。详细说明MSA和MLP块如下。
1、MSA
设M为Head的数量,也称为自注意力模块。给定输入序列,在第k个Head中,通过线性投影生成Query、Key和Value,分别用、和表示,其中N是Token的数量。D和d分别是Patch Embeddings和Q-K-V矩阵的维数。然后,计算序列中每个位置的所有值的加权和。这些权重被称为注意力权重,用表示,是基于序列中2个元素之间的成对相似性,即
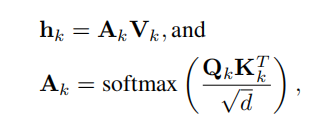
其中,对输入矩阵的每一行进行softmax(·)操作。最后,将一个全连接层应用于所有Head的输出的连接。
2、MLP
MLP块由2个FC层组成,其激活函数用σ(·)表示,通常为GELU。设为MLP的输入。MLP的输出可以表示为
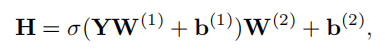
其中,、、、分别为第1层和第2层的权重和偏差。通常设置d'>d。
2.2 Weight Sharing
权重共享是一种简单而有效的提高参数效率的方法。其核心思想是跨层共享参数,如图2(a)所示从数学上讲,权重共享可以表述为一个Transformer Block f(即一个共享层)的递归更新:
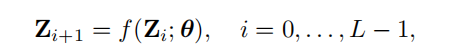
其中为序列在第i层中嵌入的特征,L为层总数,θ为各层间Transformer Block的共享权值。
很多研究工作在自然语言Transformer模型中探索并验证了权重共享的有效性。它可以防止参数的数量随着网络深度的增加而增加,而不会严重影响性能,从而提高参数的效率。
3青出于蓝
3.1 Weight Multiplexing
权重共享的潜力已经在自然语言处理中得到了证实;然而,其在Vision Transformer中的作用尚不清楚。为了检验这一点,作者直接将跨层权重共享应用于DeiT-S和Swin-B模型,并观察2个问题:
训练不稳定 性能下降
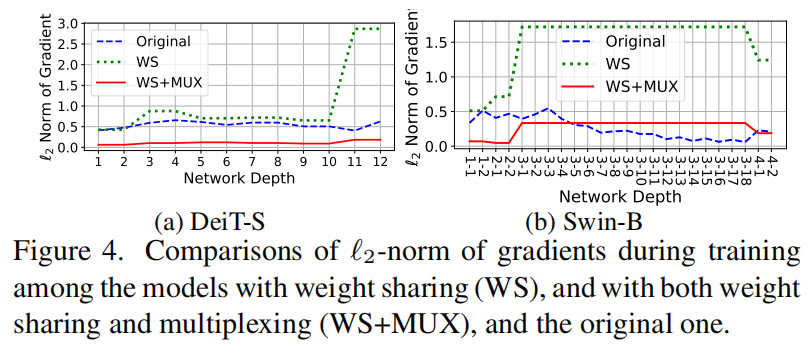
根据作者的实验分析,不同层之间权值的严格一致性是问题的主要原因。其中,权重共享后的梯度ℓ2-范数较大,在不同的Transformer Block内出现波动,如图4所示。
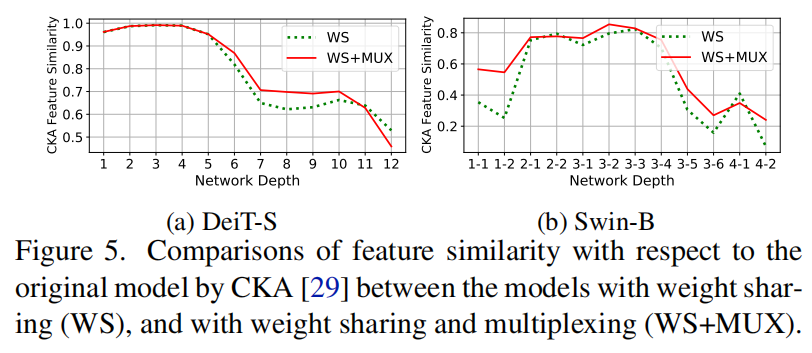
如图5所示,从CKA值可以看出,权重共享后模型生成的Feature map与原模型的相关性较小。为了解决这些问题,受到电信领域多路复用技术的启发,提出了一种新的Transformer Compression技术,Weight Multiplexing。它将多层权重组合为共享部分的单个权重,同时涉及转换和蒸馏,以增加权重的多样性。
更具体地说,如图2(b)所示,本文提出的权重复用方法包括:
在多个
Transformer Block之间共享权重,可以认为在复用时是一个组合过程;在每一层引入转换来模拟解复用;
运用知识蒸馏增加压缩前后模型之间特征表示的相似性。
根据Eq.(4),可以将权重复用重新表述如下:
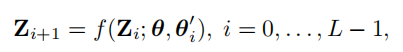
其中,表示第个Transformer Layer中Transformer Block的权值。请注意,中的参数数量远少于。
1、Weight Transformation
Weight Transformation是强加于注意力矩阵和前馈网络。这种转换允许每一层都是不同的,从而提高了参数多样性和模型表示能力。
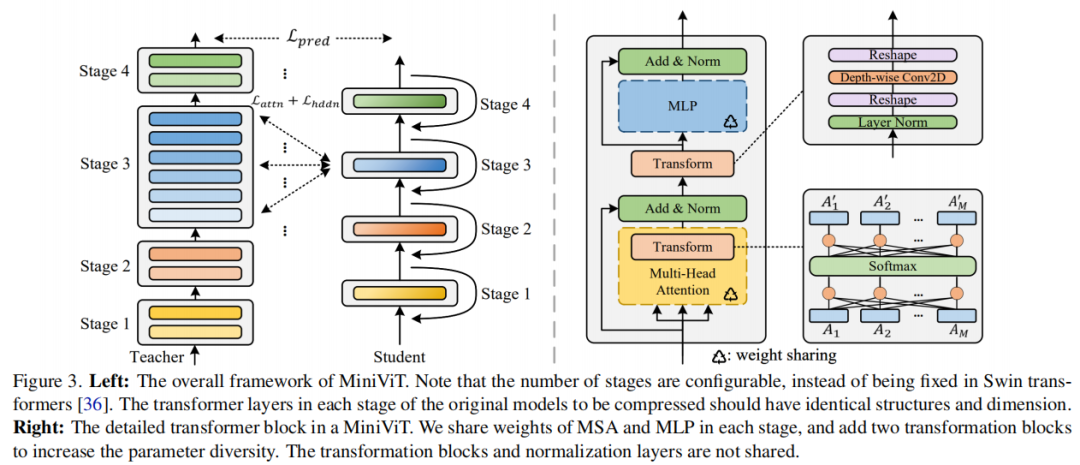
如图3(右)所示,各层之间不共享Transformation Kernels的参数,而原始Transformer中除了LayerNorm以外的所有其他层都是共享的。由于共享层占据了模型参数的绝大部分,权重复用后模型大小仅略有增加。
Transformation for MSA
为了提高参数的多样性,分别在Softmax模块前后插入了2个线性变换。
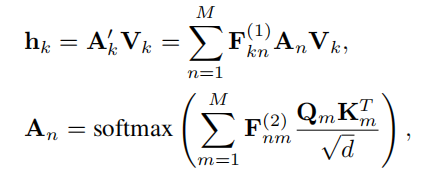
其中,分别为Softmax前后的线性变换。这种线性变换可以使每个注意力矩阵不同,同时结合注意力Head之间的信息来增加参数方差。
Transformation for MLP
另一方面,进一步对MLP进行了轻量级转换,以提高参数的多样性。特别地,设输入为,其中表示所有Token的嵌入向量的第1个位置。然后引入线性变换将Y转换为,其中是线性层的独立权重矩阵。然后是等式3被重新表述为:
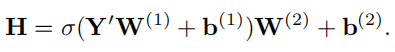
为了减少参数的数量并在变换中引入局域性,本文采用 理论上,通过这些转换, 为了压缩大型预训练模型并解决 Hinton等人证明了深度学习模型可以通过模仿训练过程中表现良好的教师模型的输出行为来获得更好的表现。作者利用这个想法来引入一个预测损失,如下所示: 其中,和分别是学生模型和教师模型预测的对数,T是控制对数平滑度的温度值。在实验中,设置T=1。CE表示交叉熵损失。 最近有研究表明,利用 首先在所有的 其中,表示的第n行。 类似地,可以生成隐藏状态的关系矩阵,即由MLP输出的特征。用表示 其中表示第n行,计算公式为。 根据作者的观察,仅使用 其中,β和γ分别为超参数,默认值分别为1和0.1。 给定一个预训练的 在这一步中使用所提出的 请注意,只有当教师模型和学生模型都是 如图4所示, 因此,不同层间共享的严格相同的权重会导致训练的不稳定性。然而, 在性能分析方面,在图5中对 采用 此外,当结合这3个组件时, 在表2中,在 结果表明, 如表3所示,与仅使用预测损失相比,额外的GT标签导致Swin的性能下降了0.3%,这是由于 [1].MiniViT: Compressing Vision Transformers with Weight Multiplexing Sparse R-CNN升级版 | Dynamic Sparse R-CNN使用ResNet50也能达到47.2AP CVPR2022 Oral | CosFace、ArcFace的大统一升级,AdaFace解决低质量图像人脸识 长按扫描下方二维码添加小助手。 可以一起讨论遇到的问题 扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!Depth-wise Convolutional来稀疏和共享每个权重矩阵中的权值,并且参数量只有比(K<权重共享层可以恢复预训练模型的行为,类似于解复用过程。这样可以缓解训练不稳定性和性能下降问题,因为这些问题在原始模型中没有观察到。类似的转换也被应用于提高没有权重共享的Transformer的性能,如Talking-heads Attention和CeiT。2、Weight Distillation
权重共享导致的性能下降问题,作者进一步采用权重蒸馏法将知识从大型模型转移到小型且紧凑的模型。考虑了Transformer Block的3种蒸馏方法:Prediction-Logit Distillation
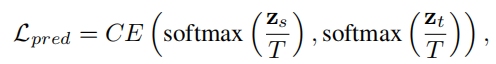
Self-Attention Distillation
Transformer Layer中的注意力图来指导学生模型的训练是有效。为了解决学生模型和教师模型之间由于Head num不同所导致的维度不一致问题,受Minilmv2启发,在MSA中对Query、Key和Value之间的关系应用了交叉熵损失。Head上附加矩阵。例如,定义,以同样的方式定义。为了简化符号,分别用、和来分别表示Q、K和V。然后,可以生成由定义的9个不同的关系矩阵。注意,是注意力矩阵a,Self-Attention Distillation损失可以表示为: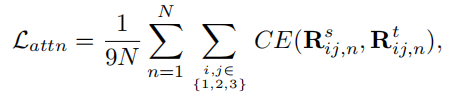
Hidden-State Distillation
Transformer Layer的隐藏状态,将基于关系矩阵的隐藏状态蒸馏损失定义为: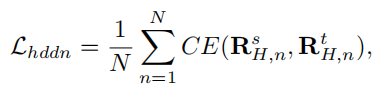
总的蒸馏损失
prediction soft labels比同时使用prediction soft labels + ground truth labels能够产生更好的性能,因此最终蒸馏目标函数表示为: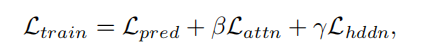
3.2 Compression Pipeline
阶段1:通过权重转换生成紧凑的架构
Vision Transformer模型,首先在共享每个相邻Transformer Layer中除了LayerNorm以外的参数。然后通过在Softmax层之前和之后插入一个线性层对每一层进行权值变换。此外,还为MLP引入了一个Depth-wise Convolutional。这些线性层和转换块的参数不共享。阶段2:用
Weight Distillation训练压缩后的模型Weight Distillation方法,将知识从大的预训练模型转移到小的模型。Transformer Block内部的这种精馏使得学生网络能够再现教师网络的行为,从而从大规模的预训练模型中提取出更多有用的知识。Transformer架构时,才会执行此操作。在其他情况下,学生和教师的结构是异质的,只保留Prediction-Logit Distillation。4实验
4.1 消融实验
1、Weight Sharing
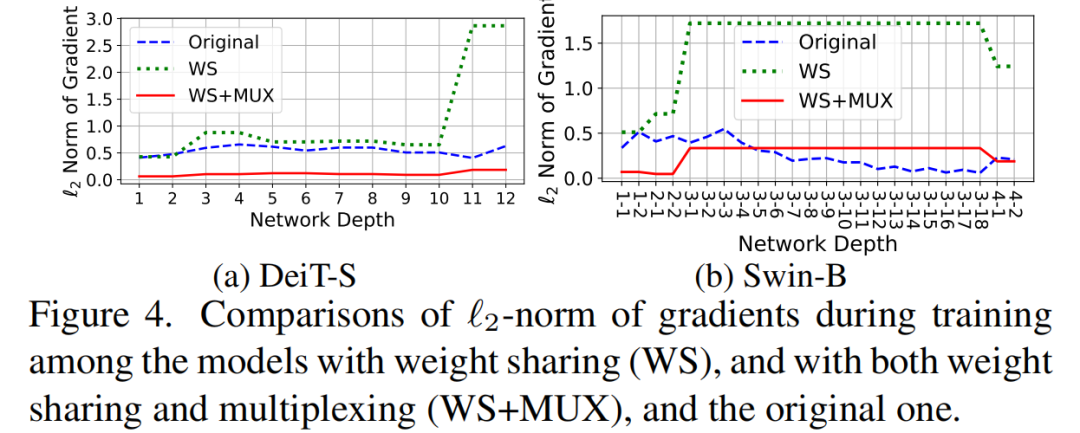
DeiT-S和Swin-B 权重共享后梯度的ℓ2-范数较大,说明权值大小变化较快。此外,权重共享还导致了不同层间的梯度范数的波动。这可能会导致不同的层的优化空间。特别是,一些层更新得很快,而其他部分几乎没有优化,这使得模型很可能收敛到一个糟糕的局部最优,甚至在训练中出现分歧。权值复用方法可以通过引入变换来提高参数多样性,从而降低梯度范数和提高层间的平滑度,促进更稳定的训练过程。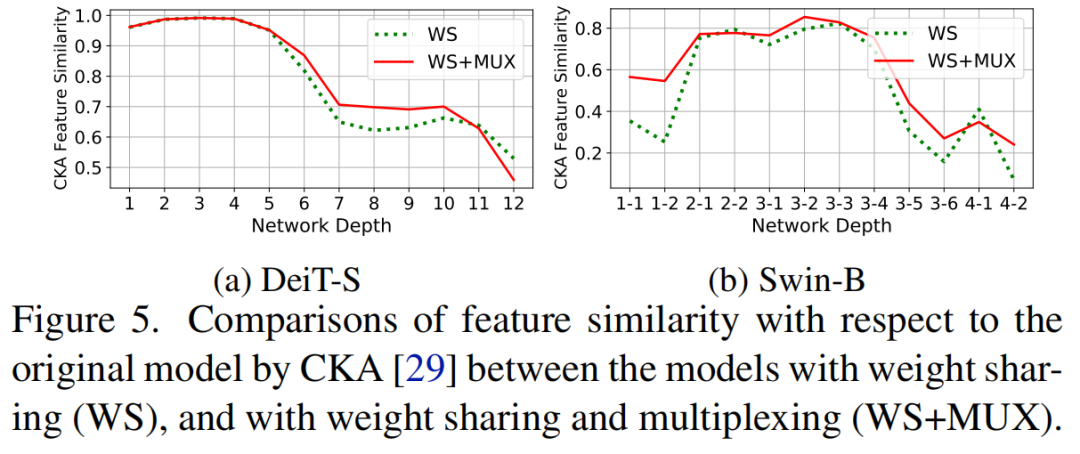
权值共享和权重复用之间的特征相似性与CKA进行了比较。CKA值越高,表示两个模型之间的特征表示越相似,从而获得相似的性能。可以观察到,DeiT和Swin在应用权重共享后都存在很大的特征表示偏差,特别是在最后几层,这可能是权重共享导致性能下降的原因之一。然而提出的权值复用方法可以提高相似性。2、Component-wise
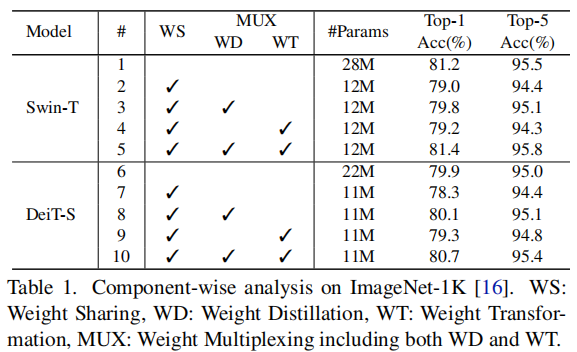
权值共享方法后,Swin-T和DeiT-S模型的参数数量减少了一半,精度也下降了2%。性能可以通过应用权重精馏或权重转换来提高,这表明了它们各自的有效性。值得注意的是权值变换只引入了少量的参数。MiniViT可以达到最好的精度,甚至超过原始的Swin-T和DeiT-S。3、Number of Sharing Blocks
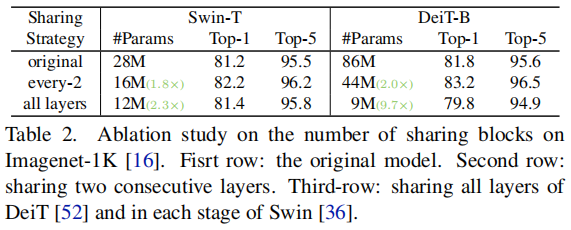
Swin-T或DeiT-B的每个阶段共享2个Block可以显著将参数量从28M减少到16M,86M减少到44M,而Top-1的精度提高了1%。在极端情况下,每个阶段的所有块都共享,Mini-Swin-T仍然可以以43%的参数优于原始模型。Mini-DeiT-B可以实现90%的参数降低,性能仅下降2%。Vision Transformer存在参数冗余,所提出的MiniViT可以有效地提高参数效率。此外,MiniViT是可配置的,以满足模型大小和性能的各种要求。4、Distillation Losses
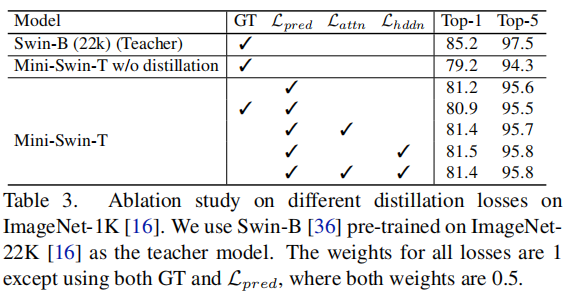
权值共享导致学习能力下降。此外,还观察到,在应用Self-Attention Distillation和Hidden-State Distillation后,精确度提高了约0.2%,表明提出的Distillation方法是有效性的。4.2 SoTA分类
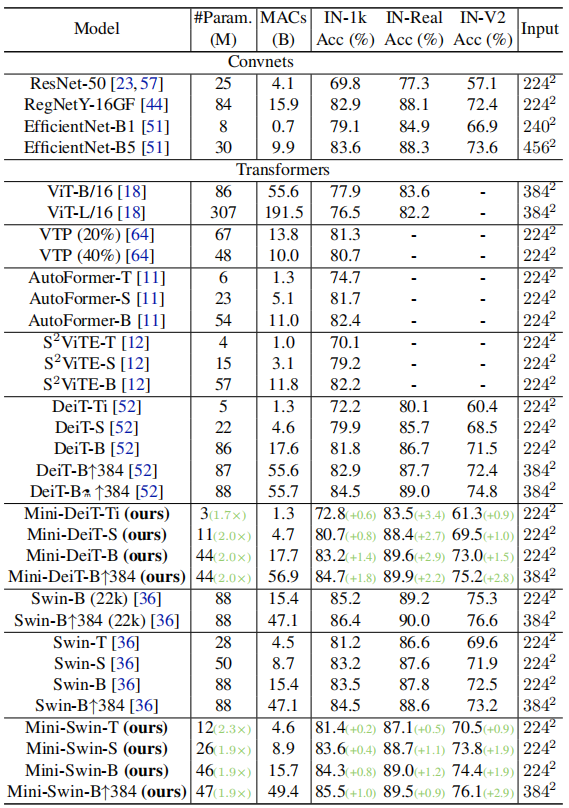
4.3 迁移学习

5参考
6推荐阅读
声明:转载请说明出处
