
10 行实现最短路算法
在上一篇文章当中我们讲解了bellman-ford算法和spfa算法,其中spfa算法是我个人比较常用的算法,比赛当中几乎没有用过其他的最短路算法。但是spfa也是有缺点的,我们之前说过它的复杂度是,这里的E是边的数量。但有的时候边的数量很多,E最多能够达到,这会导致超时,所以我们会更换其他的算法。这里说的其他的算法就是Dijkstra。
算法思想
在上一篇文章当中我们曾经说过Bellman-ford算法本质上其实是动态规划算法,我们的状态就是每个点的最短距离,策略就是可行的边,由于一共最多要松弛V-1次,所以整体的算法复杂度很高。当我们用队列维护可以松弛的点之后,就将复杂度降到了,也就是spfa算法。
Dijkstra算法和Bellman-ford算法虽然都是最短路算法,但是核心的逻辑并不相同。Dijkstra算法的底层逻辑是贪心,也可以理解成贪心算法在图论当中的使用。
其实Dijstra算法和Bellman-ford算法类似,也是一个松弛的过程。即一开始的时候除了源点s之外,其他的点的距离都设置成无穷大,我们需要遍历这张图对这些距离进行松弛。所谓的松弛也就是要将这些距离变小。假设我们已经求到了两个点u和v的距离,我们用dis[u]表示u到s的距离,dis[v]表示v的距离。
假设我们有dis[u] < dis[v],也就是说u离s更近,那么我们接下来要用一个新的点去搜索松弛的可能,u和v哪一个更有可能获得更好的结果呢?当然是u,所以我们选择u去进行新的松弛,这也就是贪心算法的体现。如果这一层理解了,算法的整个原理也就差不多了。
我们来整理一下思路来看下完整的算法流程:
我们用一个数组dis记录源点s到其他点的最短距离,起始时dis[s] = 0,其他值设为无穷大 我们从未访问过的点当中选择距离最小的点u,将它标记为已访问 遍历u所有可以连通的点v,如果dis[v] < dis[u] + l[u] [v],那么更新dis[v] 重复上述2,3两个步骤,直到所有可以访问的点都已经访问过
怎么样,其实核心步骤只有两步,应该很好理解吧?我找到了一张不错的动图,大家可以根据上面的流程对照一下动图加深一下理解。
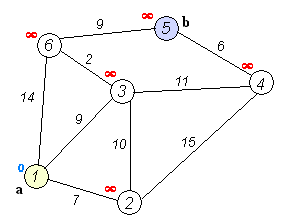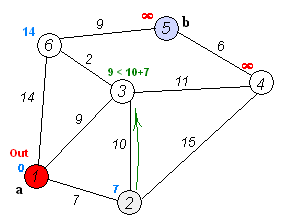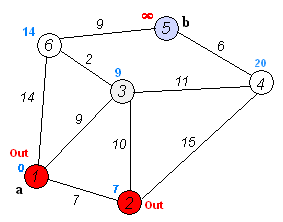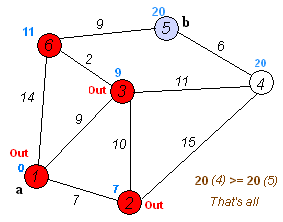
我们根据原理不难写出代码:
INF = sys.maxsize
edges = [[]] # 邻接表存储边
dis = [] # 记录s到其他点的距离
visited = {} # 记录访问过的点
while True:
mini = INF
u = 0
flag = False
# 遍历所有未访问过点当中距离最小的
for i in range(V):
if i not in visited and dis[i] < mini:
mini, u = dis[i], i
flag = True
# 如果没有未访问的点,则退出
if not flag:
break
visited[u] = True
for v, l in edges[u]:
dis[v] = min(dis[v], dis[u] + l)
虽然我们已经知道算法没有反例了,但是还是可以思考一下。主要的点在于我们每次都选择未访问的点进行松弛,有没有可能我们松弛了一个已经访问的点,由于它已经被松弛过了,导致后面没法拿来松弛其他的点呢?
其实是不可能的,因为我们每次选择的都是距离最小的未访问过的点。假设当前的点是u,我们找到了一个已经访问过的点v,是不可能存在dis[u] + l < dis[v]的,因为dis[v]必然要小于dis[u],v才有可能先于u访问。但是这有一个前提,就是每条边的长度不能是负数。
算法优化
和Bellman-ford算法一样,Dijkstra算法最大的问题同样是复杂度。我们每次选择一个点进行松弛,选择的时候需要遍历一遍所有的点,显然这是非常耗时的。复杂度应该是,这里的E是边的数量,Dijkstra中每个点只会松弛一次,也就意味着每条边最多遍历一次。
我们观察一下会发现,外面这层循环也就算了,里面这层循环很没有必要,我们只是找了一个最值而已。完全可以使用数据结构来代替循环查询,维护最值的场景我们也已经非常熟悉了,当然是使用优先队列。
使用优先队列之后这段代码会变得非常简单,同样也不超过十行,为了方便同学们调试,我把连带优先队列实现的代码一起贴上来。
import heapq
import sys
# 优先队列
class PriorityQueue:
def __init__(self):
self._queue = []
self._index = 0
def push(self, item, priority):
# 传入两个参数,一个是存放元素的数组,另一个是要存储的元素,这里是一个元组。
# 由于heap内部默认由小到大排,所以对priority取负数
heapq.heappush(self._queue, (-priority, self._index, item))
self._index += 1
def pop(self):
return heapq.heappop(self._queue)[-1]
def empty(self):
return len(self._queue) == 0
que = PriorityQueue()
INF = sys.maxsize
edges = [[], [[2, 7], [3, 9], [6, 14]], [[1, 7], [3, 10], [4, 15]], [[1, 9], [2, 10], [6, 2], [4, 11]], [[3, 11], [5, 6]], [[4, 6], [6, 9]], [[3, 2], [5, 9]]] # 邻接表存储边
dis = [sys.maxsize for _ in range(8)] # 记录s到其他点的距离
s = 1
que.push(s, 0)
dis[s] = 0
visited = {}
while not que.empty():
u = que.pop()
if u in visited:
continue
visited[u] = True
for v, l in edges[u]:
if v not in visited and dis[u] + l < dis[v]:
dis[v] = dis[u] + l
que.push(v, dis[v])
print(dis)
这里用visited来判断是否之前访问过的主要目的是为了防止负环的产生,这样程序会陷入死循环,如果确定程序不存在负边的话,其实可以没必要判断。因为先出队列的一定更优,不会存在之后还被更新的情况。如果想不明白这点加上判断也没有关系。
我们最后分析一下复杂度,每个点最多进入队列一次,加上优先队列的调整耗时,整体的复杂度是,比之前的复杂度要提速了很多,非常适合边很多,点相对较少的图。有时候spfa卡时间了,我们会选择Dijkstra。
今天的文章到这里就结束了,如果喜欢本文的话,请来一波三连,给我一点支持吧(关注、在看、点赞)。
- END -