
不容忽视的问题:行人检测器的泛化能力

极市导读
来自阿联酋起源人工智能研究院(IIAI)的研究者们发现现有的最先进的行人检测在跨库评估中的泛化能力却很差,为此本文提出了一种适用与面向自动驾驶的行人检测渐进式训练流程。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

文章地址:https://arxiv.org/pdf/2003.08799.pdf
阿联酋起源人工智能研究院(IIAI)的研究者发现现有的最先进的行人检测器尽管在库内评测中表现良好,然而在跨库评估中的泛化性能却不如那么没有为行人检测进行特殊设计的通用目标检测器。
1.简介
尽管已有的行人检测器已经取得了很好的性能,但我们仍然不知道它们在未知数据上的泛化能力。这个问题十分重要,因为实用的检测器应该可以在各种情况下使用。为此,在这篇论文中,我们对检测器的直接跨数据集的性能进行了全面的研究。我们发现现有的最先进的行人检测器尽管在同一数据集上进行训练和测试时表现良好,但在跨库评估中的泛化性能很差。我们发现了这种现象有两个原因。首先,它们的设计可能对传统的单数据集训练和测试有利,但是限制了它们的泛化能力。其次,训练数据集中的行人中不够密集,而且场景也不够丰富。
此外我们发现在直接跨库评测中那么没有为行人检测进行特殊设计的通用目标检测器的泛化性能超过了最新的行人检测器。我们还验证了通过网络爬虫收集的数据集可以作为行人检测方法的有效预训练来源。根据这个发现,我们提出了一种渐进式训练流程,并证明它非常适合面向自动驾驶的行人检测。因此,本文进行的研究表明,未来的行人检测器在设计时应该更加强调在交叉数据集上的泛化性能。
相关代码和模型开源在:https://github.com/hasanirtiza/Pedestron
2.研究动机
近些年,基于卷积神经网络(CNN)的行人检测器在一些数据集上已经十分接近人类,如图1(左)所示。但是,当前的一些行人检测方法在源数据集上展现出过拟合的迹象。如图1(右)所示,即使在相对较大的数据集上进行训练,当前的行人检测器也无法很好地泛化到其他(目标)行人检测数据集,这个问题限制了行人检测器在实际中的应用。
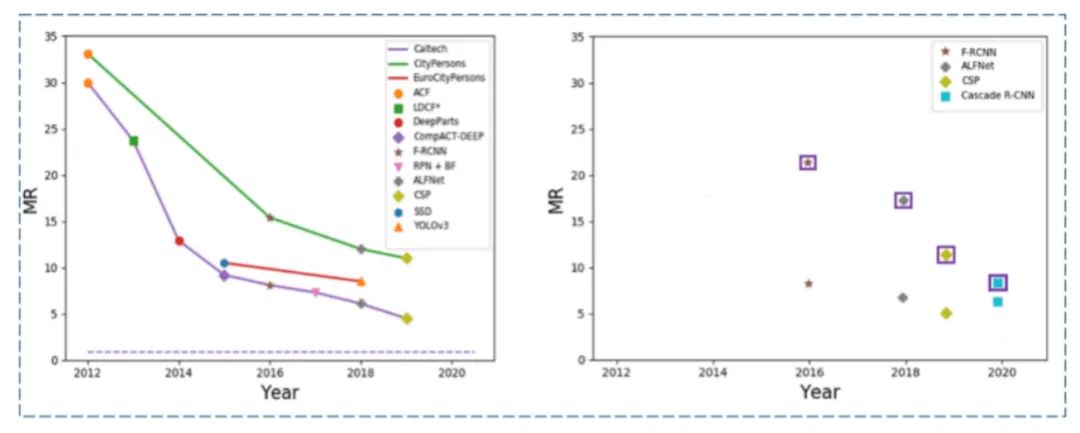
在已有的文献中,高泛化性的行人检测并没有受到大家的关注。更重要的是,尚未有工作对行人检测器在跨库评测中所表现出的低性能进行研究或讨论。在本文中,我们认为较低的泛化性是由于以下原因造成的:当前最先进的行人检测器是针对目标数据集进行量身定制的,其总体设计偏向在目标数据集上进行优化,从而降低了它们的泛化性。其次,训练数据集中的行人不够密集并且场景也不够丰富。
目前,所有与自动驾驶相关的数据集都有至少三个局限性:
近年来,通过网络爬虫和监控摄像头收集了一些规模较大且多样化的数据集,例如CrowdHuman,WiderPerson和Wider Pedestrian。这些来自更丰富场景的数据集虽然解决了上述局限性,但是它们发挥作用的前提是当前的行人检测器具有消化大规模数据的能力。
在本文中,我们发现了当提供更大,更多样化的数据集时,现有的行人检测方法逊于通用物体检测方法。此外,我们提出了一种渐进式的训练方法,以更好地利用通用行人数据集,从而改善自动驾驶情况下的行人检测性能。我们表明,通过将模型从最大(但距目标域最远)到最小(但最接近目标域)的数据集上进行逐步微调,并且无需在目标数据集上进行训练,就可以在一些数据集上获得显著的性能提升。
3.实验
3.1 基线设置
我们选择了Cascade R-CNN 方法(R-CNN系列的扩展)作为基准方法,并进行了跨库测试。如表1所示,我们使用基线检测器搭配多个基础网络进行了测试。我们最终选择了性能最优的HRNet作为基础网络。
 表1 基线方法在使用不同基础网络时的性能
表1 基线方法在使用不同基础网络时的性能
3.2库内测试
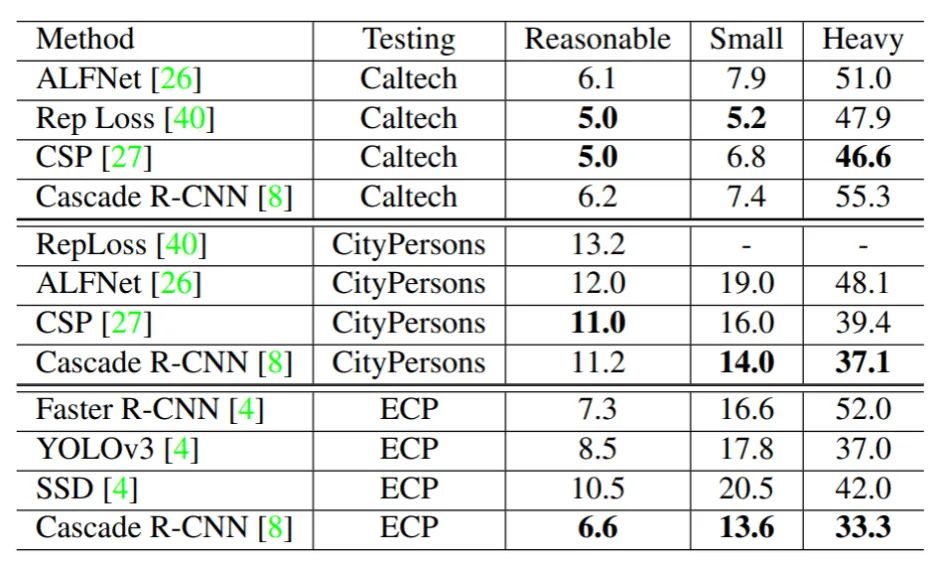
表2分别显示了在Caltech,CityPersons和ECP这三个自动驾驶数据集数据集上的测试结果。在Caltech和CityPersons数据集上,通用物体检测器Cascade R-CNN在没有使用特殊技巧的情况下,其性能可媲美现有的最好的为行人检测任务量身定制的算法。与其他方法相比,随着数据集大小的增加,我们基线的性能有着更大的提高。在最小的数据集(Caltech)上,我们基线的相对性能是最差的;而在最大的数据集(ECP)上,其相对性能是最好的。
3.3泛化能力
传统上,行人检测器通常使用经典的库内评估方法,就是在同一数据集上进行训练和测试。我们发现现有方法可能会过于拟合单个数据集,因此我们建议更加重视跨数据集评估,因为这可以测试算法在未知数据上的泛化能力。
3.4多种方法的跨数据集评估
我们在CityPersons和Caltech上对五个最新的行人检测器和我们的基线(Cascade RCNN)进行了跨数据集评估。此外,未了突出设计上的偏置对泛化性的影响,我们还加入了使用/未使用行人检测专用技巧的Faster R-CNN作为对比。
 表3 跨库评测。A→B表示在A数据集训练,在B数据集评测。
表3 跨库评测。A→B表示在A数据集训练,在B数据集评测。
如表3所示,在跨库测试中所有方法均出现了性能下降。但是相较于专用的行人检测器,Cascade R-CNN展现出更好的泛化性。此外,为行人检测专门改进的Faster R-CNN在跨数据集中的表现要比原始的Faster R-CNN差。两者之间的唯一区别是针对目标集进行的设计调整,这突显了订制的行人检测器的设计偏置。与Caltech相比,CityPersons是一个相对多样化且密集的数据集,因此跨库性能下降无法与数据集规模和人群密度联系在一起。
3.5自动驾驶数据集上的泛化性
如表4所示,即使在像ECP这样大的训练数据集和像Caltech这样小的测试集上,与现有的行人检测器CSP相比,通用物体检测方法总是能够更好地学习行人的通用特征表示。此外,大规模且密集的自动驾驶数据集提供了更好的泛化能力。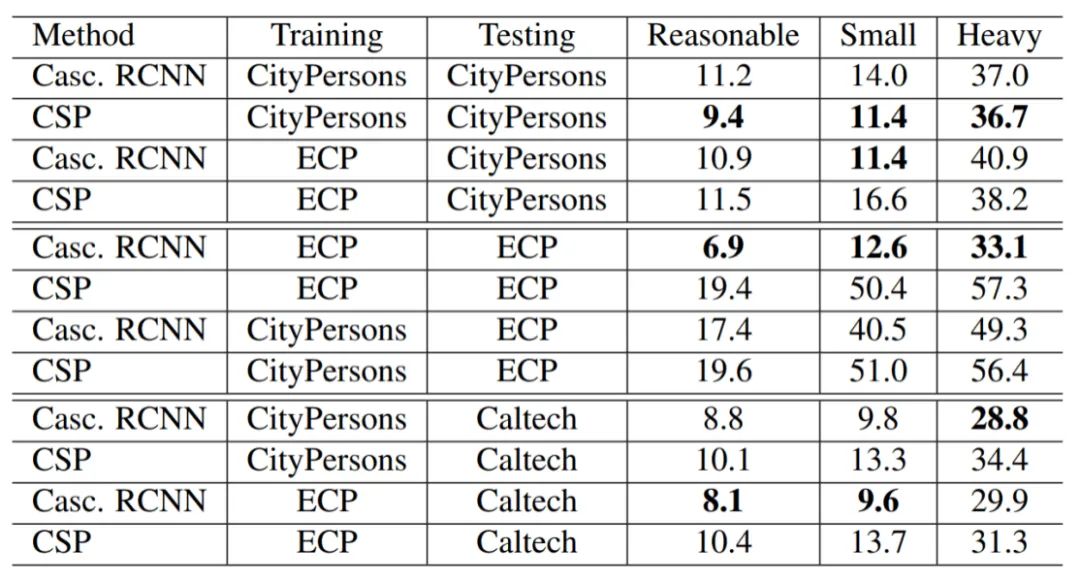 表4 Casc. RCNN 和CSP在自动驾驶数据集上的跨库评测结果。两个方法均使用了HRNet作为基础网络。
表4 Casc. RCNN 和CSP在自动驾驶数据集上的跨库评测结果。两个方法均使用了HRNet作为基础网络。
3.6多样化的行人检测数据库对模型泛化的作用
在本节中,我们研究了多样化且密集的数据集如何改善泛化。表5给出了CrowdHuman和Wide Pedestrian数据集作为训练数据时,Cascade R-CNN 和CSP(HRNet作为基础网络)的性能。我们得出的结论是,当在多样化且密集的数据集上训练并在小型自动驾驶数据集(例如Caltech)测试时,即使训练集离目标域很远也能有好的性能。但是,在大规模测试集的情况下,在接近目标域的数据上进行训练更为有效。通用物体检测方法(例如Cascade RCNN)比行人检测器(例如CSP)更能从多样化且密集的数据集中受益。
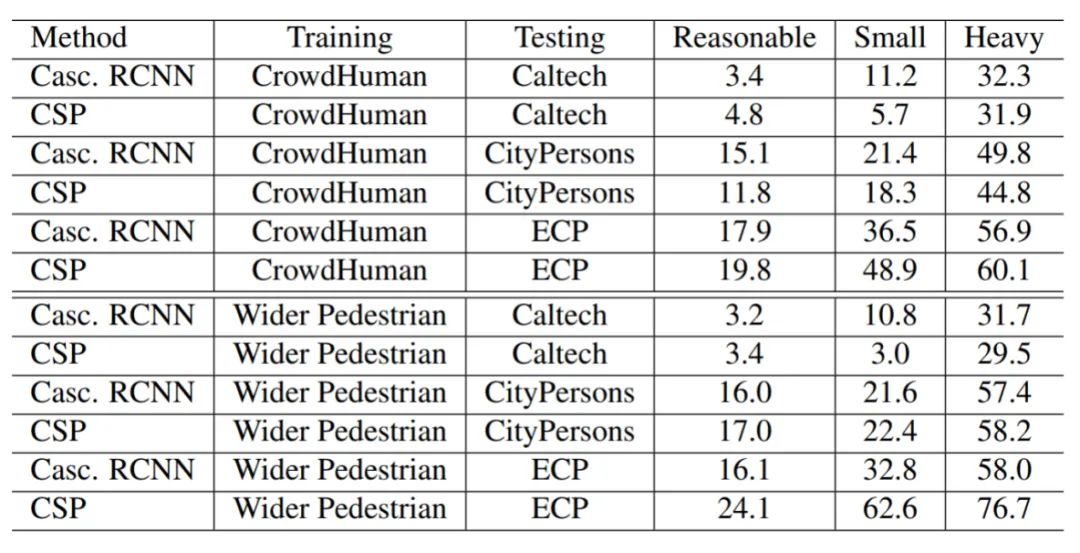 表5 使用CrowHuman和Wider Pedestrian的测试结果
表5 使用CrowHuman和Wider Pedestrian的测试结果
3.7 渐进训练
我们的实验表明,通过渐进式微调可以显着提高性能,该方法先从通用的多样化数据集(距离目标域较远)开始训练,然后在更接近目标域的数据集上微调。此外,我们也对比了将所有数据集合并起来(表6,第三和第四行),虽然也可以提高性能,但仍然比我们的渐进式训练稍差。结果表明过渐进式训练策略可以增强泛化能力,并且无需接触目标集。该方法让Cascade R-CNN在CityPersons上的性能达到了最优行列并在Caltech上取得最好的成绩。

3.8 轻量化模型
对于现实世界的应用,我们通过在各种密集数据集上进行预训练,让使用轻量级网络MobileNet的检测器也能在CityPersons上取得和目前最好的方法类似的性能。
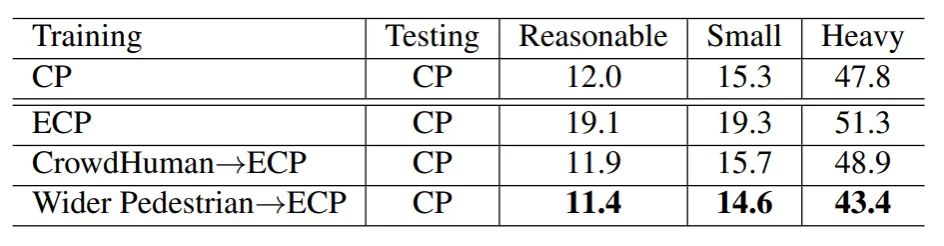
表7展示了使用MobileNet作为Cascade R-CNN的基础网络在CityPersons数据集上取得的结果。表7的第一行是MobileNet在CityPersons上进行训练和测试的结果,以作参考。直观地讲,MobileNet的表现要比HRNet差。但是,当MobileNet在CrowdHuman或Wider Pedestrian上进行了预训练,并在ECP上进行微调可以提高其性能。经过我们的渐进训练方法,即使是使用轻型网络,Cascade R-CNN 还是可与最先进的行人检测器CSP(ResNet- 50)相媲美。
4结论
受到自动驾驶场景下行人检测器在现有测试基准上的最新进展的鼓舞,我们使用标准的跨库测试方法评估了几种最先进的行人检测器的实际性能。我们得出的结论是,尽管在几个测试基准上取得了令人印象深刻的性能,但当前最先进的行人检测器无法在数据域发生偏移时取得好的性能,即使这些偏移很小。这是由于以下事实:当前最先进的行人检测器是为目标数据集量身定制的,并且它们的方法在设计时会引入对目标数据集的偏置,从而降低了它们的泛化性。相反,通用物体检测器更鲁棒,并且可以更好地泛化到新的数据集。我们进行了详尽的调查和验证,使用通用设计的通用物体检测器更能从包含多样化的场景和密集行人的大规模数据集中受益。此外,本文提出的渐进训练方法非常适合面向自动驾驶的行人检测。总之,我们在本文中的发现夯实了开发更具泛化能力的行人检测器的基础。
本文亮点总结
如果觉得有用,就请分享到朋友圈吧!
推荐阅读
2021-04-01
2021-03-18

2021-01-26

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
