
智能工厂中的计算机视觉技术
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
(文末有精彩计算机视觉技术图谱哦)
在生理学上,视觉(Vision)的产生都始于视觉器官感受细胞的兴奋,并于视觉神经系统对收集到的信息进行加工之后形成。我们人类通过视觉来直观地了解眼前事物的形体和状态,大部分人依靠视觉来完成做饭、越过障碍、读路牌、看视频以及无数其他任务。事实上,绝大多数人对外界信息的获取都是通过视觉完成的,而这个占比高达80%以上——这个比例并不是没有根据的,著名实验心理学家赤瑞特拉(Treicher)曾通过大量的实验证实:人类获取的信息的83%来自视觉,11%来自听觉,剩下的6%来自嗅觉、触觉、味觉。所以,对于人类来说,视觉无疑是最重要的一种感觉。
不仅人类是“视觉动物”,对于大多数动物来说,视觉也都起到十分重要的作用。通过视觉,人和动物感知外界物体的大小、明暗、颜色、动静,获得对机体生存具有重要意义的各种信息,通过这些信息能够得知,周围的世界是怎样的,以及如何和世界交互。
而在计算机视觉出现之前,图像对于计算机来说是黑盒的状态。一张图像对于计算机来说只是一个文件、一串数据。如果计算机、人工智能想要在现实世界发挥重要作用,就必须看懂图片!因此,半个世纪以来,计算机科学家一直在想办法让计算机也拥有视觉,从而产生了“计算机视觉”这个领域。
网络的迅速发展也令计算机视觉变得尤为重要。下图是2020年以来网络上新增数据量的走势图。灰色图形是结构化数据,蓝色图形是非结构化数据(大部分都是图片和视频)。可以很明显地发现,图片和视频的数量正在以指数级的速度疯狂增长。

▼
什么是计算机视觉
计算机视觉是人工智能领域的一个重要分支,简单来说,它要解决的问题就是:让计算机看懂图像或者视频里的内容。比如:图片里的宠物是猫还是狗?图片里的人是老张还是老王?视频里的人在做什么事情?更进一步地说,计算机视觉就是指用摄影机和电脑代替人眼对目标进行识别、跟踪和测量等,并进一步做图形处理,得到更适合人眼观察或传送给仪器检测的图像。作为一个科学学科,计算机视觉研究相关的理论和技术,试图建立能够从图像或者多维数据中获取高层次信息的人工智能系统。从工程的角度来看,它寻求利用自动化系统模仿人类视觉系统来完成任务。
计算机视觉的最终目标是使计算机能像人那样通过视觉观察和理解世界,具有自主适应环境的能力。但能真正实现计算机能够通过摄像机感知这个世界却是非常之难,因为虽然摄像机拍摄的图像和我们平时所见是一样的,但对于计算机来说,任何图像都只是像素值的排列组合,是一堆死板的数字。如何让计算机从这些死板的数字里面读取到有意义的视觉线索,是计算机视觉应该解决的问题。
不过随着技术的发展,计算机视觉技术已经可以解决越来越多的现实问题,而本文也附上了从传统到深度神经网络即AI人工智能的计算机视觉技术图谱。就是这些技术帮我们实现了一系列计算机视觉技术难题(具体的技术细节会在以后的章节和各位读者分享)。
▼
计算机视觉的典型任务

图像分类
图像分类是计算机视觉任务中的一个重要的概念,目标检测技术的发展之初也主要是通过图像分类思想来实现的。
图像分类
图像分类,顾名思义,即是输入一张图像,我们通过算法来输出这个图像的类别,例如判断出这张图像是猫或者狗。对于经典的Mnist数据集来说,这个数据集包括了0到9共10个数字的手写体图片,所以这就是一个典型的图像多分类问题,即将这些图片分为0到9共10个类别。传统的图像分类的主要步骤是进行特征提取,然后训练分类器。
2012年,基于神经网络的AlexNet网络提出,在2012年的ImageNet竞赛中夺得冠军。之后,更多的更深的神经网络被提出,比如优秀的vgg、GoogLeNet、ResNet等。
目标检测
目标检测是对图像中的目标进行分类和定位,如图所示,即找出图像中的三个目标,将其划分为“羊”这个类别,然后对每一只羊的位置进行定位,用边界框的形式将其位置标注出来,目标检测的应用非常广泛。

目标检测
目前目标检测领域的深度学习方法主要分为两类:两阶段的目标检测算法、单阶段目标检测算法。两阶段目标检测是指首先由算法生成一系列作为样本的候选框,再通过卷积神经网络进行样本分类。常见的两阶段算法有R-CNN、Fast R-CNN、Faster R-CNN等。单阶段目标检测算法不需要产生候选框,直接将目标框定位的问题转化为回归问题处理。常见的算法有YOLO系列算法、SSD算法等。
语义分割
语义分割是一种像素级别的分类,就是把图像中每个像素赋予一个类别标签(比如羊、草地等),对比图中的语义分割没有对草地和天空进行划分,只是单纯的将每一个像素划分为:是羊的像素;不是羊的像素。将羊的像素部分用颜色表示出来,我们一般将其称为二进制掩码,即一个0-1矩阵,其中羊的像素部分取值为1,不是羊的像素部分,取值为0。于是上述的图片如果使用语义分割算法进行图像分割,得到的二进制掩码如下图所示:

通过对掩码的解析,我们就可以知道当前图像中是否存在羊,以及羊处于什么位置。但是语义分割有一个局限性,比如如果一个像素被标记为橙色,那就代表这个像素所在的位置是一只羊,但是如果有两个都是橙色的像素,语义分割无法判断它们是属于同一只羊还是不同的羊。也就是说语义分割只能判断类别,无法区分个体。

语义分割
语义分割中的经典算法为全卷积网络FCN,通常CNN网络在卷积层之后会接上若干个全连接层,将卷积层产生的特征图映射成一个固定长度的特征向量。以AlexNet为代表的经典CNN结构适合于图像级的分类和回归任务。与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样,使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测,同时保留了原始输入图像中的空间信息,最后在上采样的特征图上进行逐像素分类。
语义分割领域中的经典算法有Deeplab系列算法、DFANet、BiseNet、ENet等。
实例分割
实例分割算法有点类似于语义分割和目标检测的结合,不过目标检测输出的是边界框的坐标,实例分割除了输出边界框的坐标,还会输出二进制掩码。实例分割和语义分割不同,它不需要对每个像素进行标记,它只需要找到感兴趣物体的边缘轮廓就行,实例分割是在像素级识别对象轮廓的任务。比如上图中的羊就是感兴趣的物体。我们可以看到每只羊都是不同的颜色的轮廓,因此我们可以区分出单个个体。

实例分割
经典的实例分割算法有Mask-RCNN算法、SOLO算法,以及提升速度的YOLACT算法、BlendMask算法等。
全景分割
全景分割最先由FAIR与德国海德堡大学联合提出,其任务是为图像中每个像素点赋予类别Label和实例ID,生成全局的、统一的分割图像。全景分割任务要求图像中的每个像素点都必须被分配给一个语义标签和一个实例ID。其中,语义标签指的是物体的类别,而实例ID则对应同类物体的不同编号。全景分割的一个重要的特征在于其对背景也进行了检测和分割。全景分割可以认为是语义分割和实例分割的结合。

全景分割
常见的全景分割算法有UPSNet、OANet、EfficientPS等。
计算机视觉任务目前的主要应用场景主要有:人脸识别、自动驾驶、人群计数、视频监控、文字识别、医学图像分割等。其应用领域涉及诸多行业。通过将图像的分类、识别、分割、跟踪等技术进行结合,可以在更多的行业场景中发挥作用。
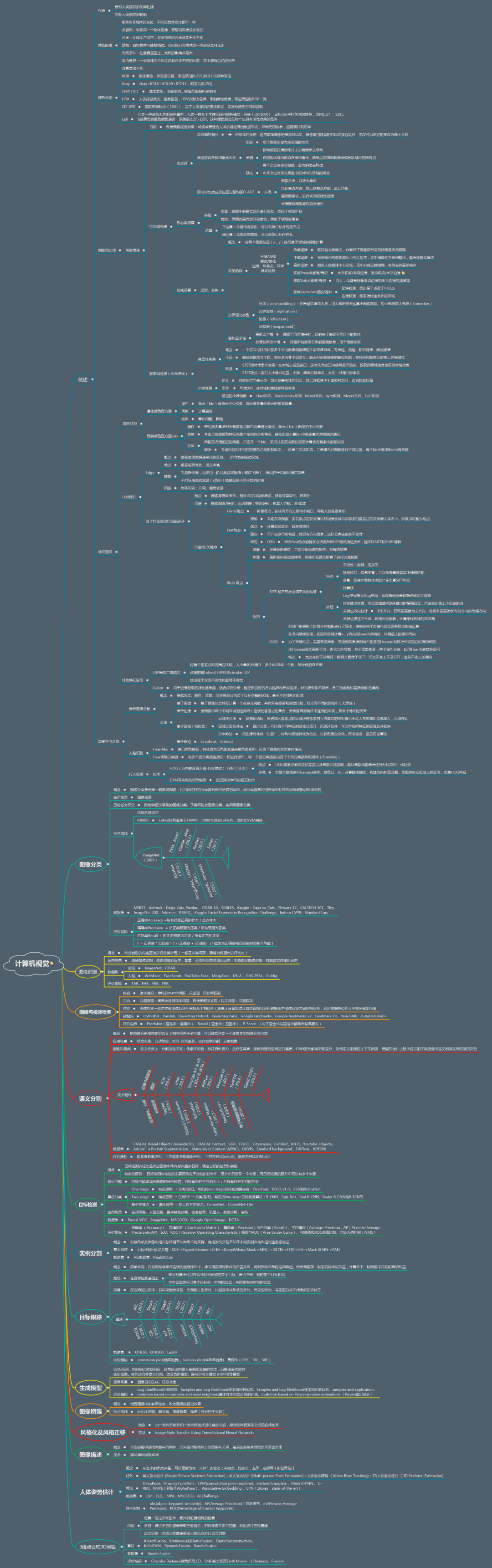
详细至极的计算机视觉技术图谱!
本文仅做学术分享,如有侵权,请联系删文。