
synchronized关键字的原理刨析
点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
前言
关于synchronized原理解析,我们首先要分析一下对象都有哪些东西,对象头到底存储了什么,synchronzied关键字到底是如何进行锁膨胀的,在使用过程中同步方法块和同步代码块到底有什么区别,在回头看synchronized的使用。针对的时JDK1.6之后的版本的synchronized深度分析。
前期准备
为输出对象头导入jar
<dependency>
<groupId>org.openjdk.jolgroupId>
<artifactId>jol-coreartifactId>
<version>0.11version>
dependency>设置偏向锁的启动延迟
#关闭偏向锁(为什么要关闭偏向锁,有什么好处嘛,这个问题先不做回答)
-XX:-UseBiasedLocking
#设置偏向锁的一个启动延迟
-XX:BiasedLockingStartupDelay=0对象
对象中有哪些部分
新建一个对象,进行main方法输出
public class A {
int status=0;
boolean flag=true;
}public static void main(String[] args) {
a=new A(); System.out.println(ClassLayout.parseInstance(a).toPrintable());
}输出的一个对象信息(当前的操作系统是一个64位的,32位的是不一样的)
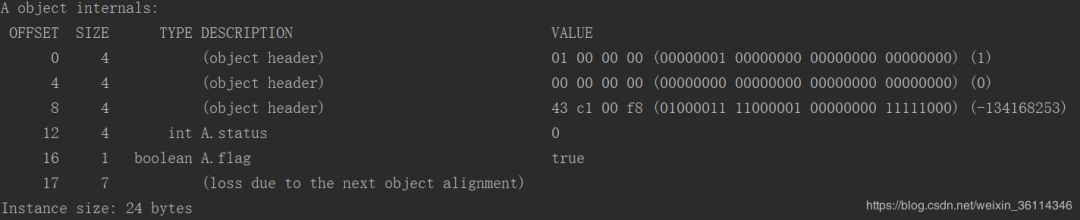
从这个上面看,我们可以分析出包含96bit(12byte*8)的对象头和两个属性(status,flag)字段属性。这些都属于对象数据,int 类型的数据我们知道,占用4个byte,1个boolean值得可以使用1个byte去表示,那么为什么后面还出现了7个byte,这是因为jvm在分配内存的时候只能是8的一个倍数。所以就出现了7个byte。
所以我们小小的总结一下。
一个对象中包含对象头,实列数据,对象填充.
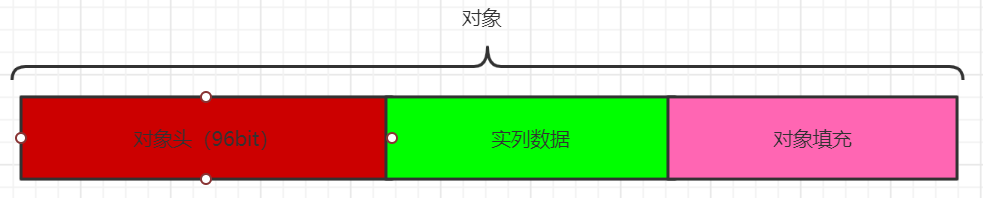
对象头有哪些东西
通过文档查找来验证
jvm底层一个是基于C/C++来实现的,查看版本java -version 可以知道jvm的实现是HotSport来实现的jvm规范和标准的。通过openjdk的官方文档 [https://openjdk.java.net/groups/hotspot/docs/HotSpotGlossary.html]查看对于对象头的一个定义。

说了一下包含两部分,mark word 和 klass pointer(这个对象对应的class类指针地址) 两部分。在open Jdk的源码中有一个markOop的文件中说明了在64bit的操作系统中,mark word 占用了64位的。所以我们得出一个结论。

那么此时我们知道了,对象头中包含了 这个对象对应的class类的类型,Gc age,hashcode , synchronized关键字的同步状态。
对象头再深入分析

这里的klass word 为什么是32bit呢,因为在jvm中如果开启了指针压缩(1.8默认开启的)就会对对象头进行压缩。所以看到是32bit,如果关闭就会看到是64bit。
关闭指针压缩
-XX:-UseCompressedOops锁的一个状态分析
new 对象A
public static void main(String[] args) {
a=new A();
System.out.println(ClassLayout.parseInstance(a).toPrintable());
a.hashCode();
System.out.println(ClassLayout.parseInstance(a).toPrintable());
}
第一次打印这个对象A的情况(没有计算a的hashcode)无锁可偏向,就是没有线程来获取这把锁,也没有计算hashcode。
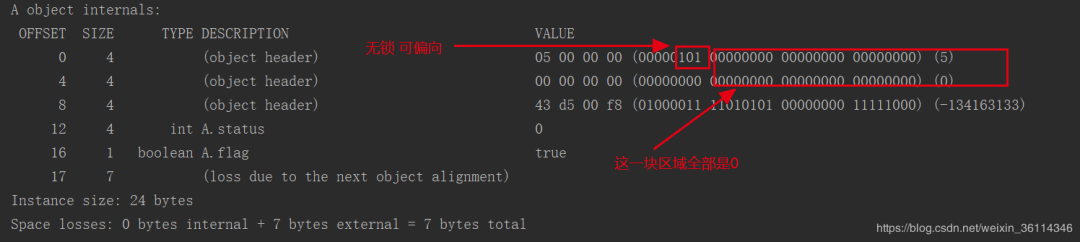
全部为0的就是没有HashCode 或者 线程ID 是空的。
第二次打印这个对象A的情况(计算了a的hashcode),无锁不可偏向,没有线程来获取这把锁,但是计算了hashcode。
并设置了HashCode 到mark word 中。
当我们的代码变成这样下面这样时,我们在看这个对象头的中mark word 的一个锁的状态。
public static void main(String[] args) {
a=new A();
System.out.println(ClassLayout.parseInstance(a).toPrintable());
a.hashCode();
System.out.println(ClassLayout.parseInstance(a).toPrintable());
lock();
new Thread(()->{
lock();
}).start();
}
public static void lock(){
synchronized (a){
System.out.println("线程名称=="+Thread.currentThread().getName());
System.out.println(ClassLayout.parseInstance(a).toPrintable());
}
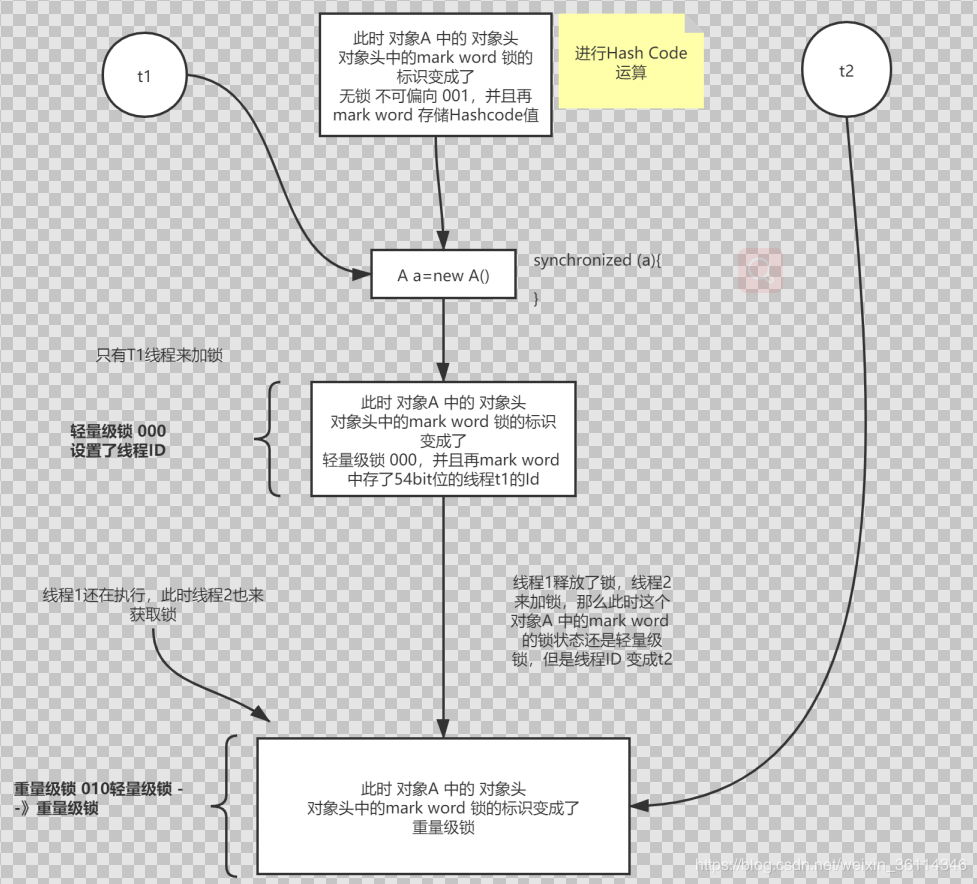
}main线程来进行加锁操作,main线程第一次来加锁,直接变成了轻量级锁,这是为什么呢,不应该是偏向锁嘛。
这是因为:对这个对象A进行了一个hashcode计算,那么hashcode占据了56个bit,锁的一个状态就变成了无锁,不可偏向状态。没有办法进行偏向,第一个线程来获取锁的时候就会变成轻量级锁。
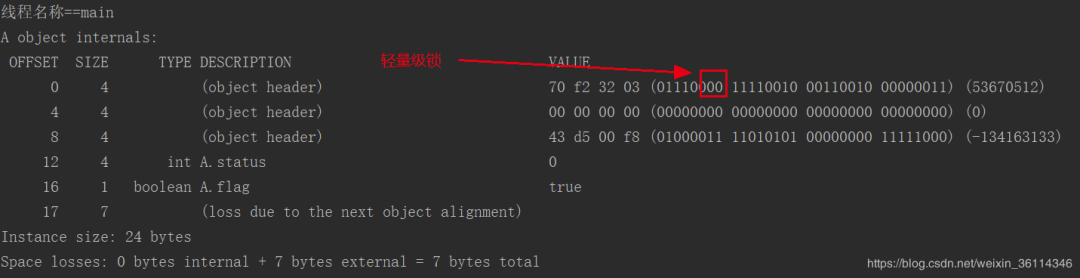
此时我们把计算hashcode注释掉
public static void main(String[] args) {
a=new A();
System.out.println(ClassLayout.parseInstance(a).toPrintable());
lock();
new Thread(()->{
lock();
}).start();
}
public static void lock(){
synchronized (a){
System.out.println("线程名称=="+Thread.currentThread().getName());
System.out.println(ClassLayout.parseInstance(a).toPrintable());
}
}
————————————————
版权声明:本文为CSDN博主「只穿T恤的程序员」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
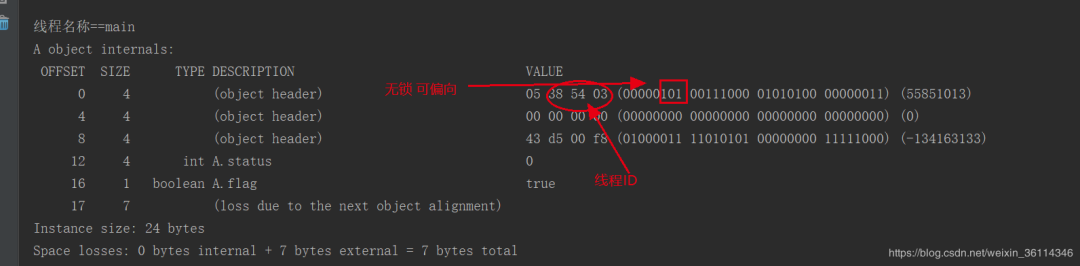
原文链接:https://blog.csdn.net/weixin_36114346/article/details/107488920运行代码得到一个 main线程加锁之后,对象头中的锁的一个状态变成了无锁 可偏向,但是多了一个线程ID。
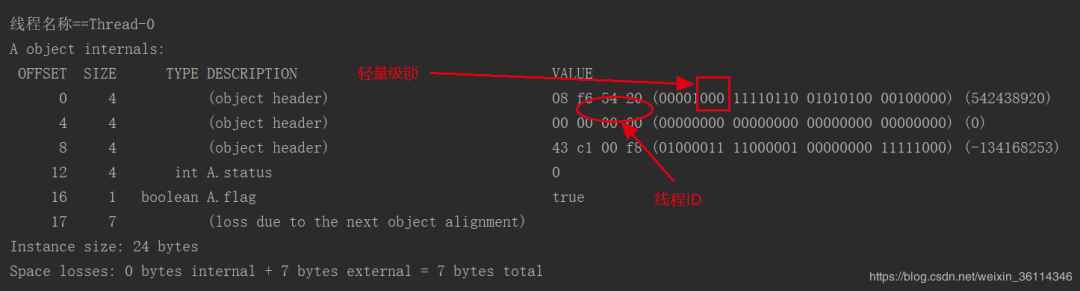
线程Thread-0运行的一个情况,此时线程Thread-0变成了轻量级锁,线程ID为thread-0,发生了一个锁的膨胀。
但是先需要撤销偏向锁,再把锁的状态变成轻量级锁,而轻量级锁是一个CAS操作。相对撤销偏向锁来说来消耗的性能要低的多。
当再执行一个线程Thread-1时,此时就变成了重量级锁。从轻量级锁变成了重量级锁。
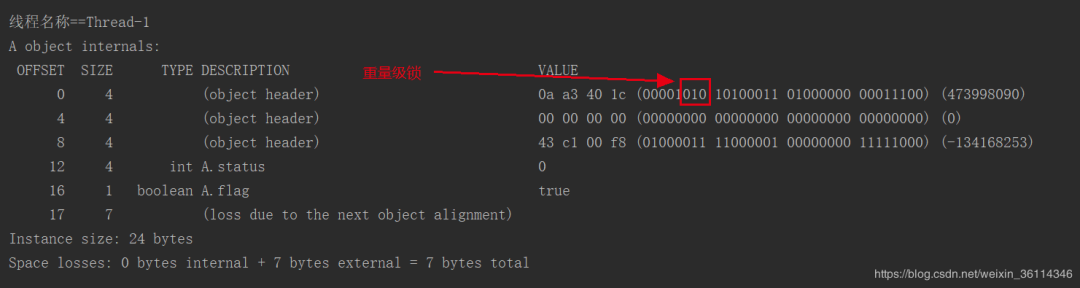
到这里我们分析完了一个锁的状态,包括锁膨胀情况。
画图总结锁的一个膨胀
没有进行HashCode运算的流程
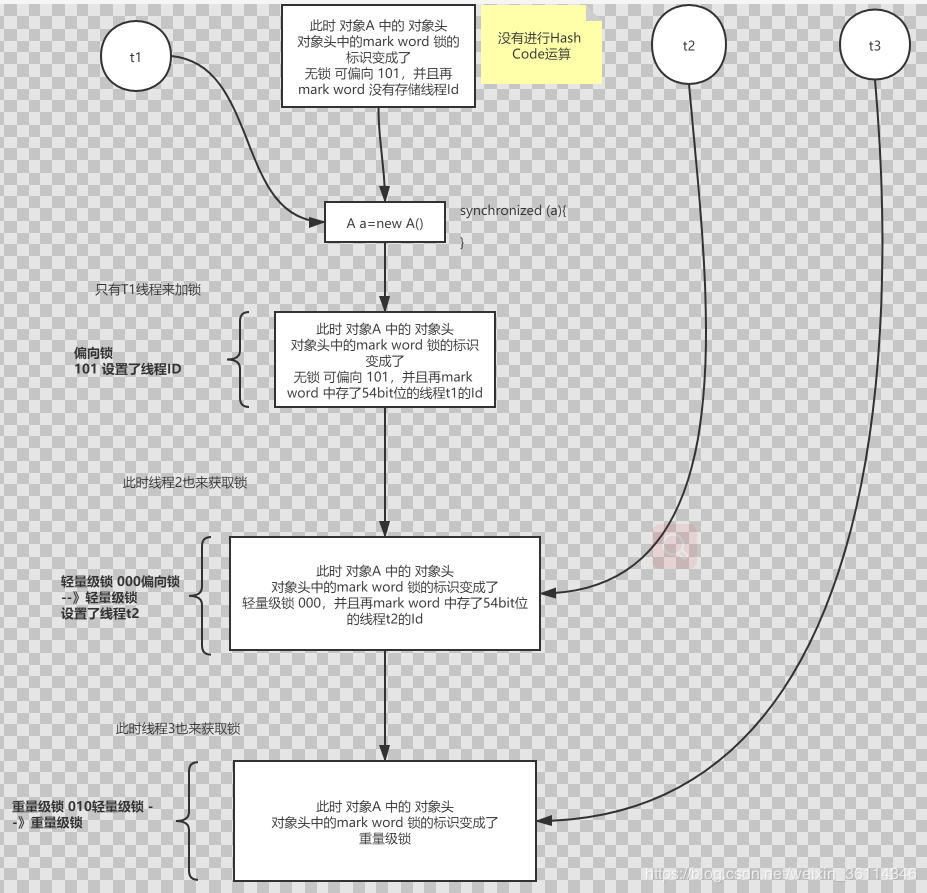
进行过HashCode运算的流程
基本使用
synchronzied加锁的对象为A,叫对象锁 ,修饰的是代码块,进入同步代码块之前要获取锁。
public static void lock(){
synchronized (a){
System.out.println("线程名称=="+Thread.currentThread().getName());
System.out.println(ClassLayout.parseInstance(a).toPrintable());
}
}synchronzied在静态方法上加锁,加锁的类型是这个方法对应的类锁。进入同步方法之前要获取锁。
public static synchronized void lock2(){
}synchronzied在实列方法上加锁,加锁的类型是这个方法对应的对象实列锁。进入同步方法之前要当前对象实列锁。
public synchronized void lock2(){
}————————————————
版权声明:本文为CSDN博主「只穿T恤的程序员」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:
https://blog.csdn.net/weixin_36114346/article/details/107488920


感谢点赞支持下哈 