
面试题:再谈Synchronized实现原理!
前言
线程安全是并发编程中的重要关注点。
造成线程安全问题的主要诱因有两点,一是存在共享数据(也称临界资源),二是存在多条线程共同操作共享数据。
为了解决这个问题,我们可能需要这样一个方案,当存在多个线程操作共享数据时,需要保证同一时刻有且只有一个线程在操作共享数据,其他线程必须等到该线程处理完数据后再进行。
在 Java 中,关键字 Synchronized可以保证在同一个时刻,只有一个线程可以执行某个方法或者某个代码块(主要是对方法或者代码块中存在共享数据的操作)。
下面来一起探索Synchronized的基本使用、实现机制。
文章首发在公众号(月伴飞鱼),之后同步到掘金和个人网站:xiaoflyfish.cn/
面试题来自:社招一年半面经分享(含阿里美团头条京东滴滴)
喜欢的话,之后会分享更多系列文章!
觉得有收获,希望帮忙点赞,转发下哈,谢谢,谢谢
用法
两类锁:
对象锁:包括方法锁(默认锁对象为this当前实例对象)和同步代码块锁(自己指定锁对象)。
类锁:指Synchronized修饰静态的方法或指定锁为Class对象。
当一个线程试图访问同步代码块时,它首先必须得到锁,而退出或抛出异常时必须释放锁。
给普通方法加锁时,上锁的对象是 this;
给静态方法加锁时,锁的是 class 对象;
给代码块加锁,可以指定一个具体的对象作为锁。
代码示例如下:
public class SynchronizedTest {
/**
* 修饰静态方法, 等同于下面注释的方法
*/
public synchronized static void test1() {
System.out.println("月伴飞鱼");
}
// public static void test1() {
// synchronized (SynchronizedTest.class){
// System.out.println("月伴飞鱼");
// }
// }
/**
* 修饰实例方法, 等同于下面注释的方法
*/
public synchronized void test2(){
System.out.println("月伴飞鱼");
}
// public void test2(){
// synchronized (this){
// System.out.println("月伴飞鱼");
// }
// }
/**
* 修饰代码块
*/
public void test3(){
synchronized (this){
System.out.println("月伴飞鱼");
}
}
}
多线程访问同步方法的几种情况:
两个线程同时访问一个对象的同步方法。
由于同步方法锁使用的是this对象锁,同一个对象的this锁只有一把,两个线程同一时间只能有一个线程持有该锁,所以该方法将会串行运行。
两个线程访问的是两个对象的同步方法。
由于两个对象的this锁互不影响,Synchronized将不会起作用,所以该方法将会并行运行。
两个线程访问的是Synchronized的静态方法。
Synchronized修饰的静态方法获取的是当前类模板对象的锁,该锁只有一把,无论访问多少个该类对象的方法,都将串行执行。
同时访问同步方法与非同步方法
非同步方法不受影响。
访问同一个对象的不同的普通同步方法。
由于this对象锁只有一个,不同线程访问多个普通同步方法将串行运行。
同时访问静态Synchronized和非静态Synchronized方法
静态Synchronized方法的锁为class对象的锁,非静态Synchronized方法锁为this的锁,它们不是同一个锁,所以它们将并行运行。
使用优化
大家在使用synchronized关键字的时候,可能经常会这么写:
synchronized (this) {
...
}
它的作用域是当前对象,锁的就是当前对象,谁拿到这个锁谁就可以运行它所控制的代码。
当有一个明确的对象作为锁时,就可以这么写,但是当没有一个明确的对象作为锁,只想让一段代码同步时,可以创建一个特殊的变量(对象)来充当锁:
public class Demo {
private final Object lock = new Object();
public void methonA() {
synchronized (lock) {
...
}
}
}
这样写没问题。但是用new Object()作为锁对象是否是一个最佳选择呢?
我在StackOverFlow看到这么一篇文章:object-vs-byte0-as-lock
大意就是用new byte[0]作为锁对象更好,会减少字节码操作的次数。
public class Demo {
private final byte[] lock = new byte[0];
}
具体细节大家,可以看看这篇文章,算提供一种思路吧!
实现原理
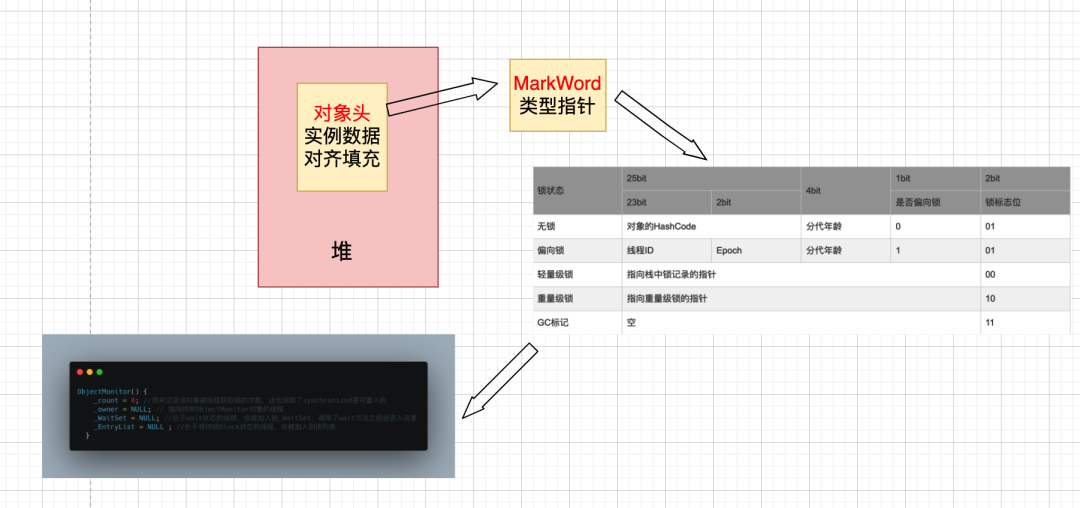
因为Synchronized锁的是对象,在讲解原理之前先介绍下对象结构相关知识。
HotSpot虚拟机中,对象在内存中存储的布局可以分为三块区域:对象头、实例数据和对齐填充。
对象头
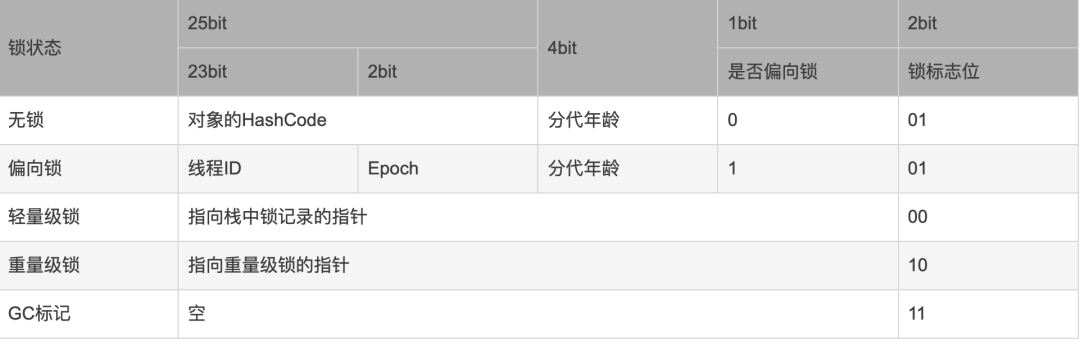
对象头包括两部分信息:运行时数据Mark Word和类型指针
如果对象是数组对象,那么对象头占用3个字宽(Word)(需要记录数组长度),如果对象是非数组对象,那么对象头占用2个字宽(1word = 2Byte = 16bit)
对象头的类型指针指向该对象的类元数据,虚拟机通过这个指针可以确定该对象是哪个类的实例
Mark Word
用于存储对象自身的运行时数据, 如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等等,它是实现轻量级锁和偏向锁的关键。
这部分数据的长度在32位和64位的虚拟机(暂不考虑开启压缩指针的场景)中分别为32个和64个Bits。
Synchronized锁对象就存储在MarkWord中,下面是MarkWord的布局:
32位虚拟机
实例数据
实例数据就是在程序代码中所定义的各种类型的字段,包括从父类继承的
对齐填充
由于HotSpot的自动内存管理要求对象的起始地址必须是8字节的整数倍,即对象的大小必须是8字节的整数倍,对象头的数据正好是8的整数倍,所以当实例数据不够8字节整数倍时,需要通过对齐填充进行补全
意思是每次分配的内存大小一定是8的倍数,如果对象头+实例数据的值不是8的倍数,那么会重新计算一个较大值,进行分配
底层实现
下面的代码,在命令行执行 javac,然后再执行javap -v -p,就可以看到它具体的字节码。
可以看到,在字节码的体现上,它只给方法加了一个 flag:ACC_SYNCHRONIZED。
synchronized void syncMethod() {
System.out.println("syncMethod");
}
synchronized void syncMethod();
descriptor: ()V
flags: ACC_SYNCHRONIZED
Code:
stack=2, locals=1, args_size=1
0: getstatic #4
3: ldc #5
5: invokevirtual #6
8: return
我们再来看下同步代码块的字节码。可以看到,字节码是通过 monitorenter 和monitorexit 两个指令进行控制的。
void syncBlock(){
synchronized (Test.class){
}
}
void syncBlock();
descriptor: ()V
flags:
Code:
stack=2, locals=3, args_size=1
0: ldc #2
2: dup
3: astore_1
4: monitorenter
5: aload_1
6: monitorexit // 两个monitorexit是表示正常退出和异常退出的场景
7: goto 15
10: astore_2
11: aload_1
12: monitorexit
13: aload_2
14: athrow
15: return
Exception table:
from to target type
5 7 10 any
10 13 10 any
这两者虽然显示效果不同,但他们都是通过 monitor 来实现同步的。
其中在Java虚拟机(HotSpot)中,Monitor是由ObjectMonitor实现的,其主要数据结构如下(位于HotSpot虚拟机源码ObjectMonitor.hpp文件,C++实现的):
ObjectMonitor() {
_header = NULL;
_count = 0; // 用来记录该对象被线程获取锁的次数,这也说明了synchronized是可重入的
_waiters = 0,
_recursions = 0;
_object = NULL;
_owner = NULL; // 指向持有ObjectMonitor对象的线程
_WaitSet = NULL; // 处于wait状态的线程,会被加入到_WaitSet,调用了wait方法之后会进入这里
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ;
FreeNext = NULL ;
_EntryList = NULL ; // 处于等待锁block状态的线程,会被加入到该列表
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
}
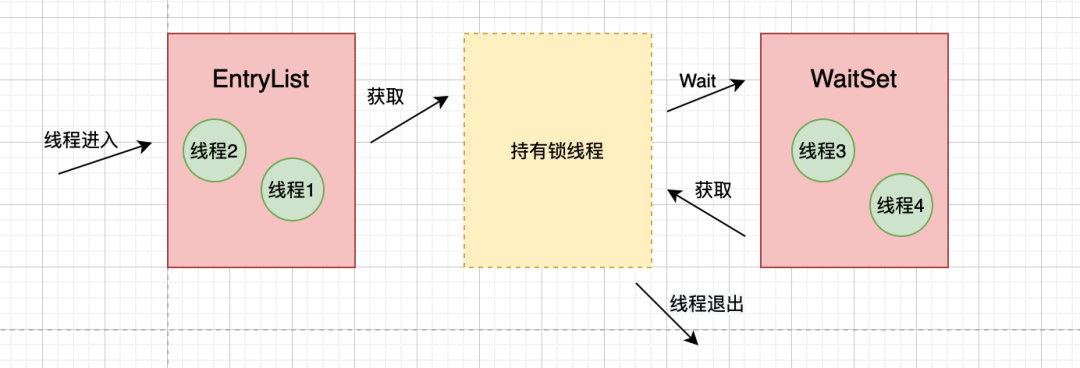
每个 Java 对象在 JVM 的对等对象的头中保存锁状态,指向 ObjectMonitor。
ObjectMonitor 保存了当前持有锁的线程引用,EntryList 中保存目前等待获取锁的线程,WaitSet 保存 wait 的线程。
还有一个计数器count,每当线程获得 monitor 锁,计数器 +1,当线程重入此锁时,计数器还会 +1。当计数器不为 0 时,其它尝试获取 monitor 锁的线程将会被保存到EntryList中,并被阻塞。
当持有锁的线程释放了monitor 锁后,计数器 -1。当计数器归位为 0 时,所有 EntryList 中的线程会尝试去获取锁,但只会有一个线程会成功,没有成功的线程仍旧保存在 EntryList 中。
详细流程:
加锁时,即遇到Synchronized关键字时,线程会先进入monitor的 _EntryList队列阻塞等待。如果monitor的 _owner为空,则从队列中移出并赋值与_owner。如果在程序里调用了wait()方法,则该线程进入 _WaitSet队列。我们都知道wait方法会释放monitor锁,即将_owner赋值为null并进入_WaitSet队列阻塞等待。这时其他在_EntryList中的线程就可以获取锁了。当程序里其他线程调用了notify/notifyAll方法时,就会唤醒 _WaitSet中的某个线程,这个线程就会再次尝试获取monitor锁。如果成功,则就会成为monitor的owner。当程序里遇到Synchronized关键字的作用范围结束时,就会将monitor的owner设为null,退出。
Java对象如何与Monitor关联
锁优化
相比于 JDK 1.5,在 JDK 1.6 中 HotSopt 虚拟机对 Synchronized 内置锁的性能进行了很多优化,包括自适应的自旋、锁消除、锁粗化、偏向锁、轻量级锁等。
自适应的自旋锁
在 JDK 1.6 中引入了自适应的自旋锁来解决长时间自旋的问题。
比如,如果最近尝试自旋获取某一把锁成功了,那么下一次可能还会继续使用自旋,并且允许自旋更长的时间;但是如果最近自旋获取某一把锁失败了,那么可能会省略掉自旋的过程,以便减少无用的自旋,提高效率。
锁消除
经过逃逸分析之后,如果发现某些对象不可能被其他线程访问到,那么就可以把它们当成栈上数据,栈上数据由于只有本线程可以访问,自然是线程安全的,也就无需加锁,所以会把这样的锁给自动去除掉。
锁粗化
按理来说,同步块的作用范围应该尽可能小,仅在共享数据的实际作用域中才进行同步,这样做的目的是为了使需要同步的操作数量尽可能缩小,缩短阻塞时间,如果存在锁竞争,那么等待锁的线程也能尽快拿到锁。
但是加锁解锁也需要消耗资源,如果存在一系列的连续加锁解锁操作,可能会导致不必要的性能损耗。
锁粗化就是将多个连续的加锁、解锁操作连接在一起,扩展成一个范围更大的锁,避免频繁的加锁解锁操作。
偏向锁/轻量级锁/重量级锁
JVM 默认会优先使用偏向锁,如果有必要的话才逐步升级,这大幅提高了锁的性能。
锁升级
锁的状态总共有四种,无锁状态、偏向锁、轻量级锁和重量级锁
随着锁的竞争,锁可以从偏向锁升级到轻量级锁,再升级的重量级锁,但是锁的升级是单向的,也就是说只能从低到高升级,不会出现锁的降级
从JDK 1.6中默认是开启偏向锁,可以通过-XX:-UseBiasedLocking来禁用偏向锁
偏向锁
在只有一个线程使用了锁的情况下,偏向锁能够保证更高的效率。
具体过程是这样的:当第一个线程第一次访问同步块时,会先检测对象头 Mark Word 中的标志位 Tag 是否为 01,以此判断此时对象锁是否处于无锁状态或者偏向锁状态。
线程一旦获取了这把锁,就会把自己的线程 ID 写到 MarkWord 中,在其他线程来获取这把锁之前,锁都处于偏向锁状态。
当下一个线程参与到偏向锁竞争时,会先判断 MarkWord 中保存的线程 ID 是否与这个线程 ID 相等,如果不相等,会立即撤销偏向锁,升级为轻量级锁。
轻量级锁
当锁处于轻量级锁的状态时,就不能够再通过简单地对比标志位 Tag 的值进行判断,每次对锁的获取,都需要通过自旋。
当然,自旋也是面向不存在锁竞争的场景,比如一个线程运行完了,另外一个线程去获取这把锁;但如果自旋失败达到一定的次数,锁就会膨胀为重量级锁。
重量级锁
重量级锁,这种情况下,线程会挂起,进入到操作系统内核态,等待操作系统的调度,然后再映射回用户态。系统调用是昂贵的,所以重量级锁的名称由此而来。
如果系统的共享变量竞争非常激烈,锁会迅速膨胀到重量级锁,这些优化就名存实亡。
如果并发非常严重,可以通过参数-XX:-UseBiasedLocking 禁用偏向锁,理论上会有一些性能提升,但实际上并不确定。
| 锁 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 偏向锁 | 加锁和解锁不需要额外的消耗,和执行非同步方法比仅存在纳秒级的差距 | 如果线程间存在锁竞争,会带来额外的锁撤销的消耗 | 基本没有线程竞争锁的场景 |
| 轻量级锁 | 竞争的线程不会阻塞,提高了程序的响应速度 | 如果始终得不到锁竞争的线程使用自旋会消耗CPU | 适用于少量线程竞争锁对象,且线程持有锁时间不长,追求响应时间的场景。 |
| 重量级锁 | 线程竞争不使用自旋,不会消耗CPU | 线程阻塞,响应时间缓慢 | 追求吞吐量。竞争比较激烈,锁持有时间较长的场景 |
常见面试题
Synchronized和Lock的区别:
Synchronized属于JVM层面,底层通过 monitorenter和 monitorexit 两个指令实现,Lock是API层面的东西,JUC提供的具体类Synchronized不需要用户手动释放锁,当Synchronized代码执行完毕之后会自动让线程释放持有的锁,Lock需要一般使用try-finally模式去手动释放锁 Synchronized是不可中断的,除非抛出异常或者程序正常退出,Lock可中断,使用 lockInterruptibly,调用interrupt方法可中断Synchronized是非公平锁,Lock默认是非公平锁,但是可以通过构造函数传入boolean类型值更改是否为公平锁 锁是否能绑定多个条件,Synchronized没有condition的说法,要么唤醒所有线程,要么随机唤醒一个线程,Lock可以使用condition实现分组唤醒需要唤醒的线程,实现精准唤醒 Synchronized 锁只能同时被一个线程拥有,但是 Lock 锁没有这个限制,例如在读写锁中的读锁,是可以同时被多个线程持有的,可是 Synchronized做不到 性能区别:在 Java 5 以及之前Synchronized的性能比较低,但是到了 Java 6 以后 JDK 对 Synchronized 进行了很多优化,比如自适应自旋、锁消除、锁粗化、轻量级锁、偏向锁等
最后
觉得有收获,希望帮忙点赞,转发下哈,谢谢,谢谢
微信搜索:月伴飞鱼,交个朋友,进面试交流群
公众号后台回复666,可以获得免费电子书籍

面试题:在日常工作中怎么做MySQL优化的?

美团面试题:缓存一致性,我是这么回答的!
