
@synchronized锁原理的源码分析
回顾
在上一篇博客中,已经分析了第一次加锁,data是空的,最后会创建SyncData并绑定到当前线程上(一个线程只会绑定一个,并且绑定后不再改变),注意此时并没有保存到线程对应的缓存列表中。
源码分析
单线程情况
那么现在去看看第二次加锁,也就是断点在44行时,进行跟踪调试。

那么继续单步调式进入源码里面,断点在id2data方法里面再进行 lldb的调式进行分析。

从图中控制台 lldb的调试结果来看,第二次进行加锁时,data里面是有数据的了。那么继续过断点看看,缓存里面的情况:

此时缓存里面也有数据了,和上面打印的结果是一模一样,都是data = 0x0000000100837d40。然后会继续判断,传入对象是否是和缓存里面的一样。
if (data->object == object) {
// Found a match in fast cache.
uintptr_t lockCount;
result = data;
lockCount = (uintptr_t)tls_get_direct(SYNC_COUNT_DIRECT_KEY);
if (result->threadCount <= 0 || lockCount <= 0) {
_objc_fatal("id2data fastcache is buggy");
}
如果是同一个对象,就会获取lockCount,lockCount和threadCount是否小于等于 0进行判断,如果小于 0则会报错"id2data fastcache is buggy"
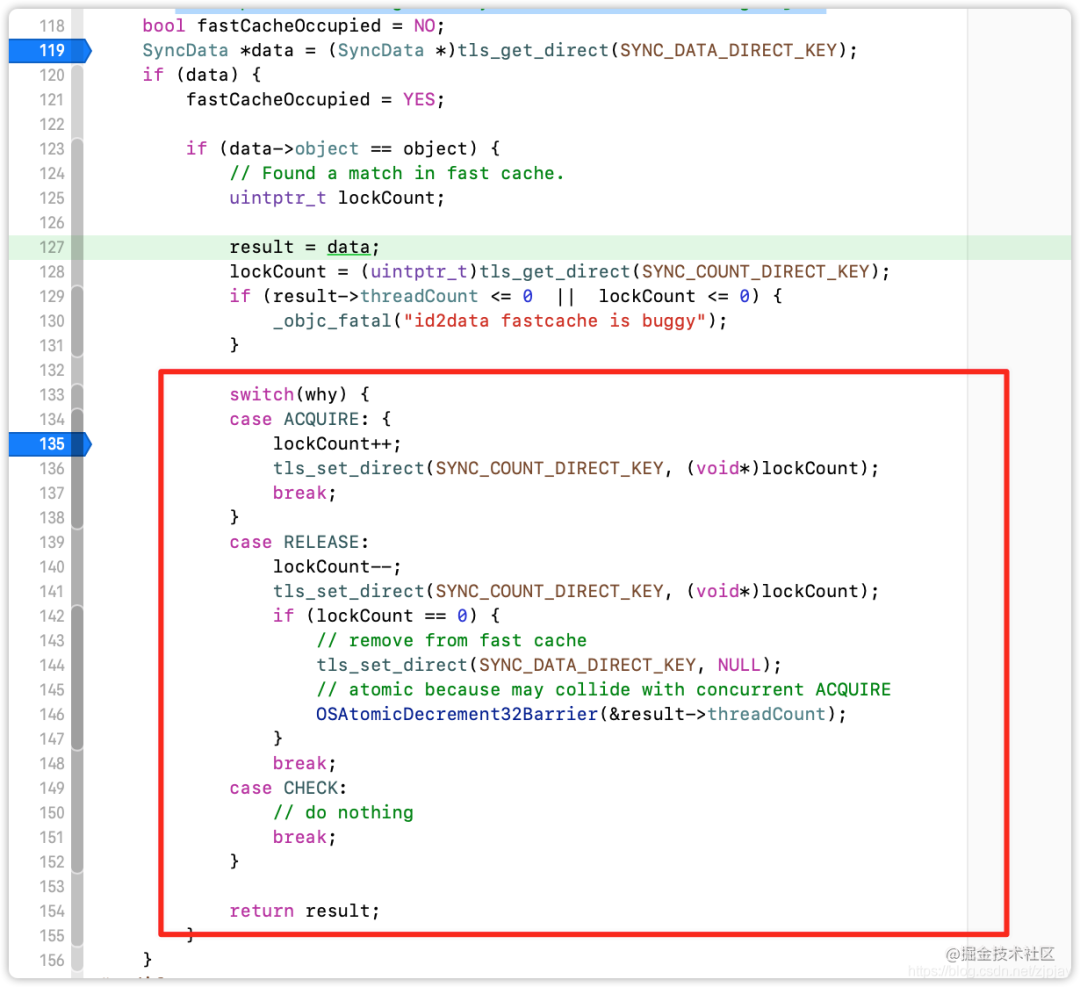
如果是ACQUIRE则会lockCount++,再进行锁一次,说明当前对象锁了两次,如下:

如何是RELEASE则会lockCount--,如果lockCount == 0,则会从线程空间缓存移除,这里也可以体现多线程的特性,从这句OSAtomicDecrement32Barrier(&result->threadCount)代码可以看出,这是对线程进行释放。
断点继续,看看第三次加锁的情况,如下:
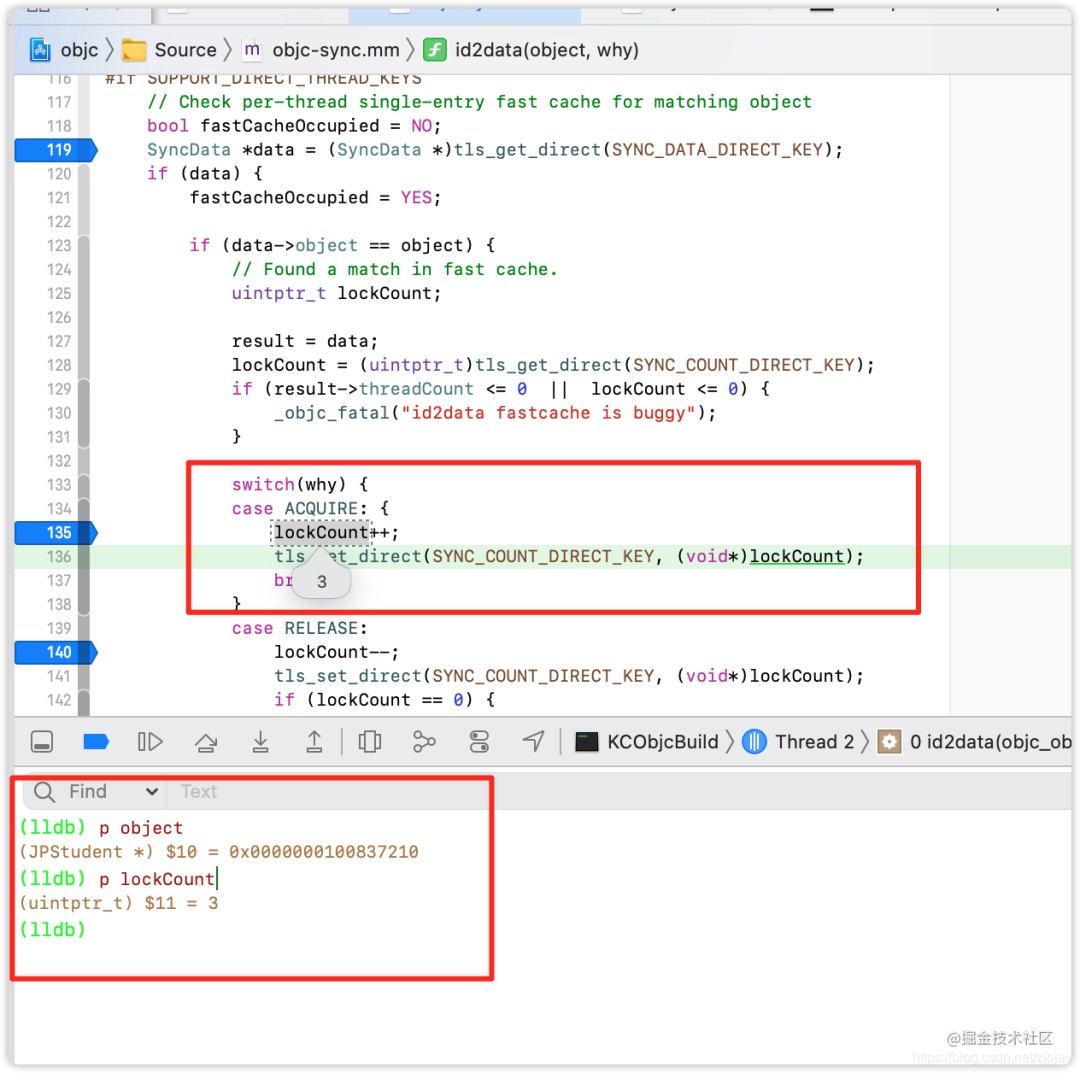
因为是对同一个对象,进行了重复的操作,加锁了3次,lockCount也是等于 3的,这也提现了拉链法,如下:
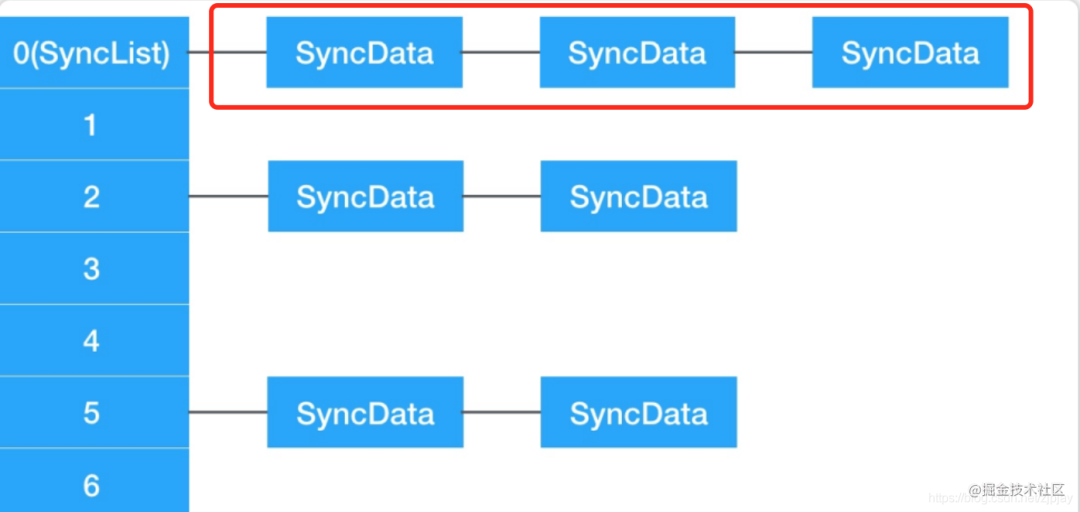
因为是同一个对象,每次加锁,都会创建一个SyncData,就一直往后拉着,通过一个链表来存。
以上都是对一个对象进行重复的递归加锁,那如果是不同对象呢?
不同对象也是类似的,就和上面那个结构图一样,每个对象会创建一个拉链,同一个对象的就存在一个链表里面,这里就不再进行举例了,感兴趣的老铁可以自行测试,源码戳这里
多线程递归情况
那么现在通过多线程加锁会怎么样呢?测试代码如下:

断点从 52 行开始,进入到源码里面跟踪调式,这时候进入id2data方法,此时哈希表中的数据个数为2,也就是外层线程添加的两个SyncData,如下图:
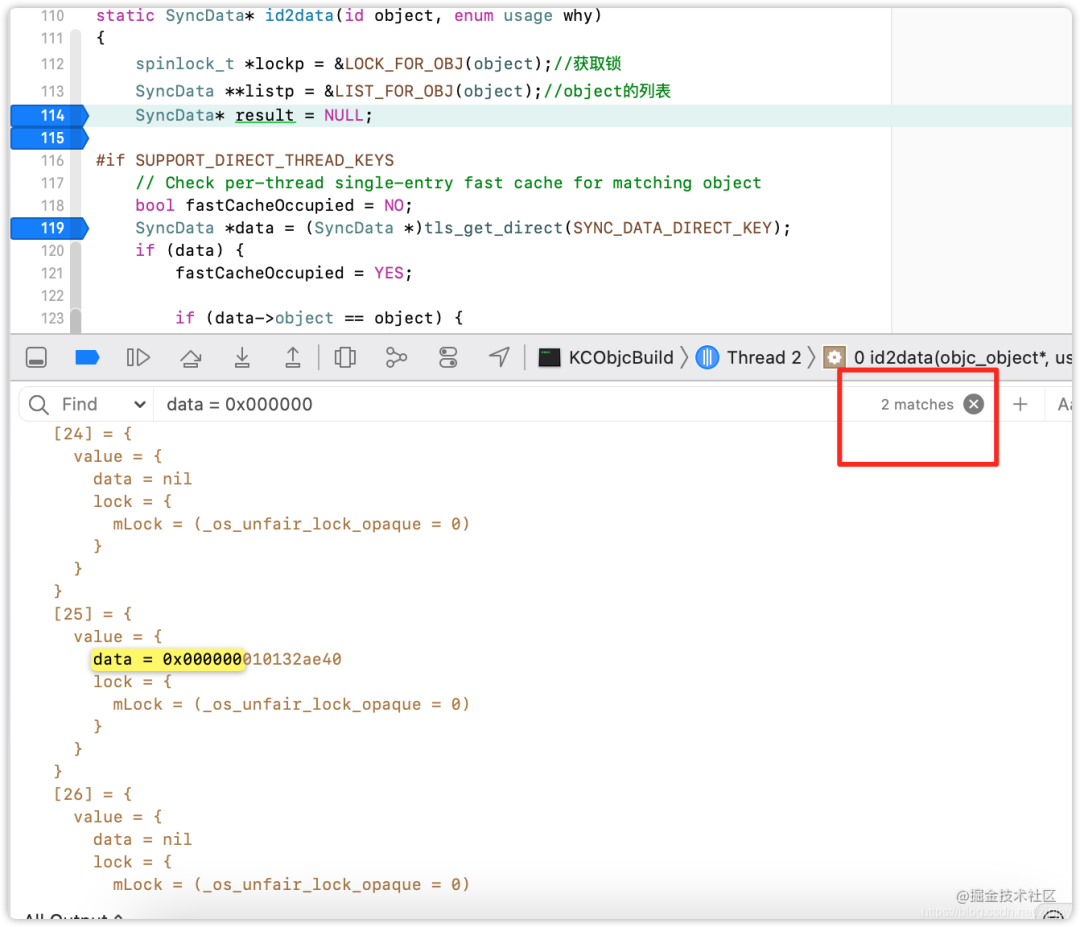
继续跟踪代码,从线程中获取其绑定的SyncData,此时为NULL,因为是新的线程,还没有加过锁,所以绑定数据为空,fastCacheOccupied=NO
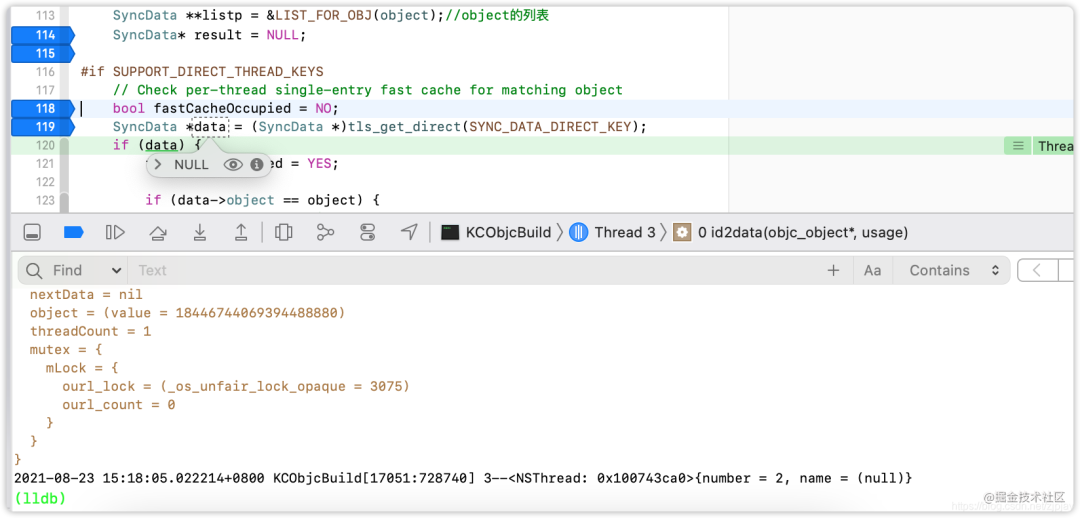
然后会继续往下走,接着从缓存列表fetch_cache中获取对应的·SyncData·,也是·NULL·,这里的缓存列表也是和线程一一对应的起来的,都是空。

继续跟踪流程,接着会进行线程threadCount++操作,如下图:

这里会从listp中获取对应的数据,在外层线程中,已经添加了jp和jp2对应的SyncData,这里是可以获取到的,并且会对多线程操作,使得threadCount加1操作,此时对应的线程数会从 1变成2,从上图调试打印的结果可以很明显的看到。
只要遇到新开线程,开始加锁,tls和cache一定是空,肯定是listp中查找,或者是创建。一个线程中第一个添加的object一定会绑定到tls中,并且在当前线程中不会改变。如果tls已经完成设置,之后添加的SyncData都会添加到缓存列表中。
objc_sync_exit流程和这个相反,同样会调用id2data方法,获取SyncData,对lockCount和threadCount进行减操作。如果count等于0,则会从相应的绑定关系和缓存列表中移除。
使用@synchronized的注意事项
参数不传 nil
参数最好传 self,方便存储和释放,如果是传入一个这种
JPStudent *jp = [[JPStudent alloc]init]的,这个 jp是一个临时的变量,如果有个多个这种,就会有多个拉链,耗费内存和性能,只使用一个self 就只有一个拉链,虽然真机环境下,只有 8`个,但是已经够用了,即便不够用,系统也会及时释放回收的。

在之前的博客中进行的@synchronized测试,为什么模拟器下性能比真机差呢?就是上图中 64的原因,模拟器拉链比较多,耗费内存和性能。
总结
1: synchronized 哈希表 - 拉链法 存储SyncData
2: sDataLists里面是一个 array存储的是 SyncList,SyncList 里面是绑定的object
3: objc_sync_enter / exit 对称 递归锁
4: 两种存储 : TLS/ Cache
5: 第⼀次的时候 SyncData 才用头插法 -链表 ,标记 thracount = 1
6: 然后下次再进来会判断是不是同⼀个对象
7: 是同一个对象TLS --> lockCount ++
8: 不是同一个的话TLS 找不到 就会去创建一个SyncData 则threadCount ++
9: objc_sync_exit 的话就是lockCount-- 和 threadCount--
@synchronized : 可重⼊递归 、多线程
1: 多线程是通过TLS 保障 threadCount 有多少条线程对这个锁对象加锁
2: 可重入递归是通过lockCount ++ 来表示进来锁了多少次
补充TLS
线程局部存储(Thread Local Storage,TLS): 是操作系统为线程单独提供的私有空间,通常只有有限的容量。Linux系统下通常通过pthread库中的 pthread_key_create()、 pthread_getspecific()、 pthread_setspecific()、 pthread_key_delete()等方法。