
JUC并发编程之Synchronized关键字详解

对了,后续我也会对ReenLock锁进行一个源码分析,大家伙可以敬请期待。
public class StaticTest01 {/*** 静态方法加锁,它的锁就是加在 StaticTest01.class 上* 因为是静态方法,所以是通过类进行调用的,那么锁就加在类上面*/public synchronized static void decrStock() {System.out.println("上锁");}}
public class StaticTest02 {/*** 非静态方法加锁,因为非静态,所以需要进行 new对象,然后才能使用该方法* 那么锁就是加在 new 对象的这个对象上,例如:StaticTest02 syn = new StaticTest02();* 那么锁就是加在 syn 这个对象上*/public synchronized void decrStock() {System.out.println("上锁");}}
public class StaticTest03 {private static Object object = new Object();/*** 非静态方法代码块加锁,那么锁就是加在 object 这个成员变量上* 可以针对一部分代码块,而非整个方法*/public void decrStock() {synchronized (object) {System.out.println("上锁");}}}
需要注意的是:synchronized关键字被编译成字节码后会被翻译成monitorenter 和 monitorexit 两条指令分别在同步块逻辑代码的起始位置与结束位置。
synchronized在JVM里的实现都是 基于进入和退出Monitor对象来实现方法同步和代码块同步,虽然具体实现细节不一样,但是都可以通过成对的MonitorEnter和MonitorExit指令来实现。
基于字节码文件,来看看同步块代码与同步方法它们之间的区别
public class StaticTest03 {private static Object object = new Object();/*** 非静态方法代码块加锁,那么锁就是加在 object 这个成员变量上* 只不过代码块,可以针对一部分代码块,而非整个方法*/public void decrStock() {synchronized (object) {System.out.println("上锁");}}}
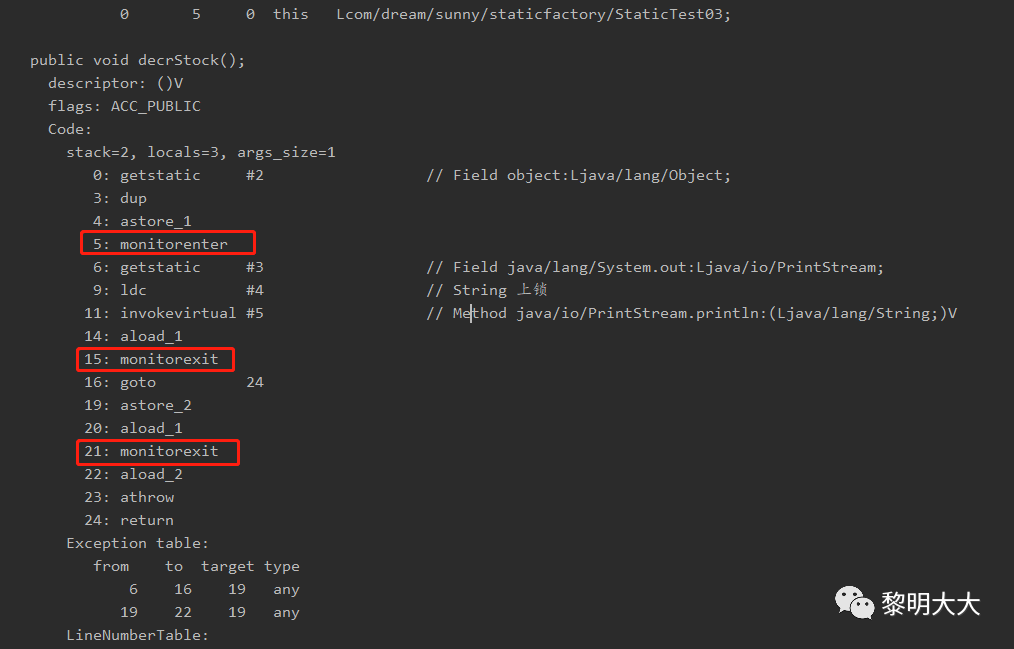
monitorexit,指令出现了两次,第1次为同步正常退出释放锁;第2次为发生异步退出释放锁;
通过上面两段描述,我们应该能很清楚的看出Synchronized的实现原理,Synchronized的语义底层是通过一个monitor的对象来完成,其实wait/notify等方法也依赖于monitor对象,这就是为什么只有在同步的块或者方法中才能调用wait/notify等方法,否则会抛出java.lang.IllegalMonitorStateException的异常的原因。
接着来看同步方法:
public class StaticTest02 {/*** 非静态方法加锁,因为非静态,所以需要进行 new对象,然后才能使用该方法* 那么锁就是加在 new 对象的 这个 对象上,例如:StaticTest02 syn = new StaticTest02();* 那么锁就是加在 syn 这个对象上*/public synchronized void decrStock() {System.out.println("上锁");}}
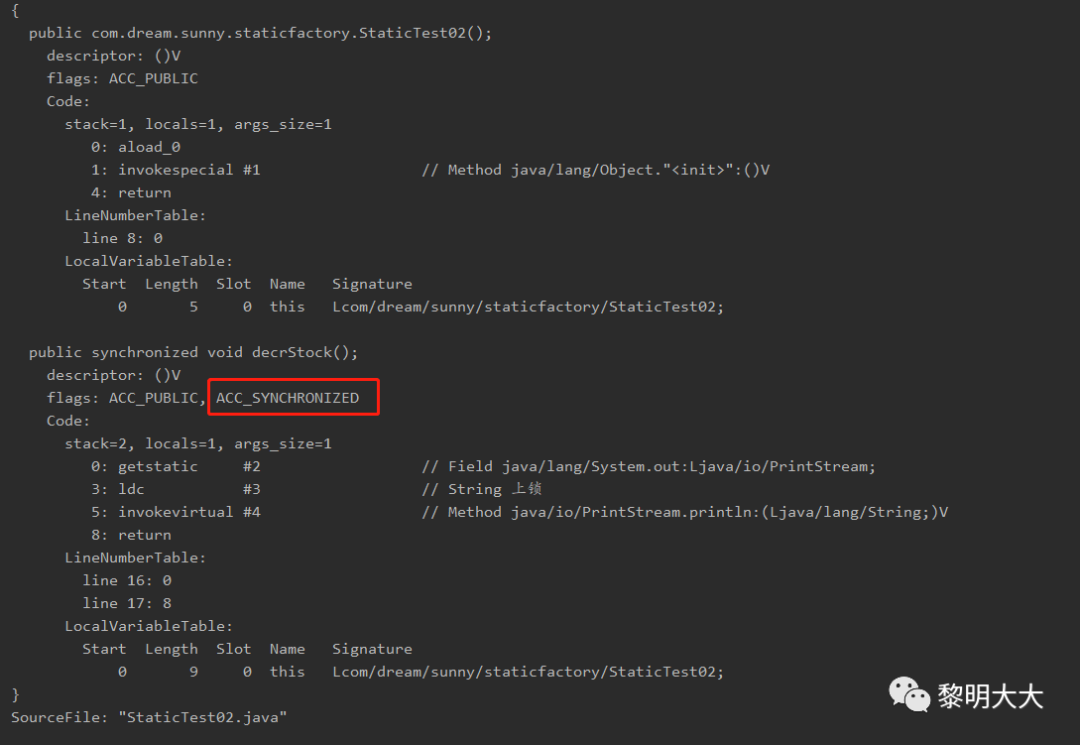
当方法调用时,调用指令将会检查方法的 ACC_SYNCHRONIZED 访问标志是否被设置,如果设置了,执行线程将先获取monitor,获取成功之后才能执行方法体,方法执行完后再释放monitor。在方法执行期间,其他任何线程都无法再获得同一个monitor对象。
两种同步方式本质上没有区别,只是方法的同步是一种隐式的方式来实现,无需通过字节码来完成。两个指令的执行是JVM通过调用操作系统的互斥原语mutex来实现,被阻塞的线程会被挂起、等待重新调度,会导致“用户态和内核态”两个态之间来回切换,对性能有较大影响。
我们前面也有说到,同步锁它是加在对象上的,那他在对象里面是如何存储的呢?来分析分析
在HotSpot虚拟机中,对象在内存中存储的布局可以分为三块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。
但看这段文字估计还有点懵,我在这里放上一张图片。

前面也说到了对象的组成部分,结合上图进行分析,在HotSpot虚拟机的对象头包括两部分信息,第一部分是“Mark Word”,用于存储对象自身的运行时数据, 如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等等,它是实现轻量级锁和偏向锁的关键,这部分数据的长度在32位和64位的虚拟机(暂不考虑开启压缩指针的场景)中分别为32个和64个Bits,为了节省内存,如果我们机器是64位系统,则jvm会自动开启指针压缩,将它压缩成32位,所以本文就基于32位来进行分析。
再继续放上,基于32位虚拟机的一个对象头表格
注意:对象头信息是与对象自身定义的数据无关的额外存储成本,但是考虑到虚拟机的空间效率,Mark Word被设计成一个非固定的数据结构以便在极小的空间内存存储尽量多的数据,它会根据对象的状态复用自己的存储空间,也就是说,Mark Word会随着程序的运行发生变化
说到这,前面我有说到jvm它默认开启了指针压缩,其实我们也可以手动将其关闭,主要看场景决定吧
手动设置-XX:+UseCompressedOops有了以上内容的铺垫,我们就可以来聊一聊偏向锁、轻量级锁、自旋锁,它们是什么东西,然后再来分析它们在对象头中产生了什么样的差异。
轻量级锁
自旋锁
锁的对象头分析:
<dependency><groupId>org.openjdk.jol</groupId><artifactId>jol-core</artifactId><version>0.10</version></dependency>
public class StaticTest04 {public static void main(String[] args) {Object o = new Object();System.out.println(ClassLayout.parseInstance(o).toPrintable());}}

以上图为例,将信息头反过来后,我们结合上面的表格查看,在最后的两位是 "01" ,是01则就是无所状态的标识
//对象头信息00000001 00000000 00000000 00000000//将信息返回来后00000000 00000000 00000000 00000001
public class StaticTest04 {public static void main(String[] args) {Object o = new Object();System.out.println(ClassLayout.parseInstance(o).toPrintable());synchronized (o) {System.out.println(ClassLayout.parseInstance(o).toPrintable());}}}

//加同步块后对象头信息01001000 11110010 11001110 00000010//倒序转换后的对象头信息00000010 11001110 11110010 01001000
public class StaticTest04 {public static void main(String[] args) throws InterruptedException {TimeUnit.SECONDS.sleep(5);Object o = new Object();System.out.println(ClassLayout.parseInstance(o).toPrintable());synchronized (o) {System.out.println(ClassLayout.parseInstance(o).toPrintable());}}}
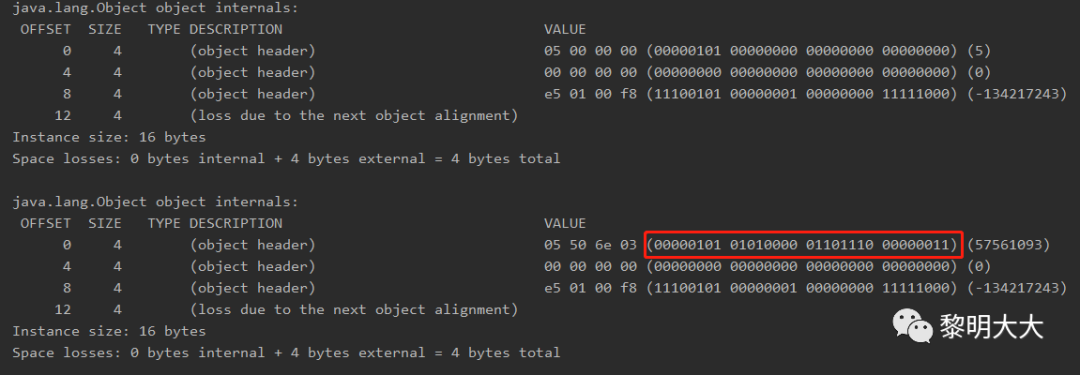
//加同步块后对象头信息00000101 01010000 01101110 00000011//倒序转换后的对象头信息00000011 01101110 01010000 00000101
@Slf4jpublic class StaticTest05 {public static void main(String[] args) throws InterruptedException {TimeUnit.SECONDS.sleep(5);Object o = new Object();log.info(ClassLayout.parseInstance(o).toPrintable());new Thread(() -> {synchronized (o){log.info(ClassLayout.parseInstance(o).toPrintable());}}).start();TimeUnit.SECONDS.sleep(2);new Thread(() -> {synchronized (o){log.info(ClassLayout.parseInstance(o).toPrintable());}}).start();}}
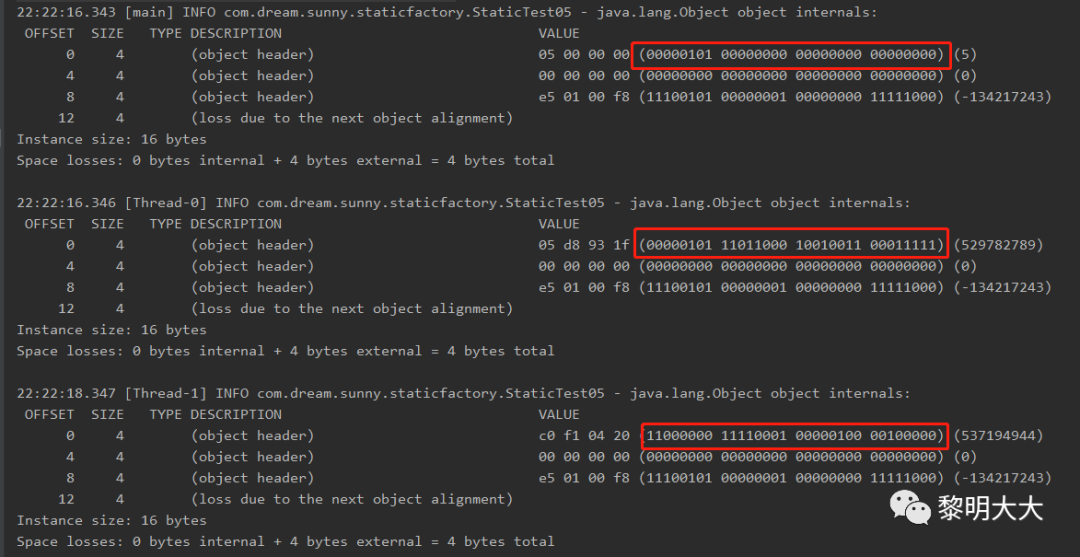
最后再来看看,如何晋升成的重量级锁的,先看代码
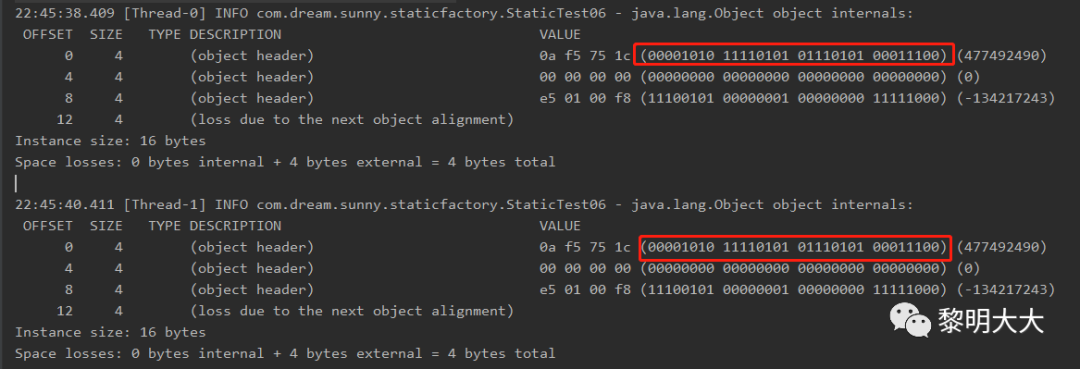
@Slf4jpublic class StaticTest06 {public static void main(String[] args) throws InterruptedException {TimeUnit.SECONDS.sleep(5);Object o = new Object();Thread threadA = new Thread(() -> {synchronized (o) {log.info(ClassLayout.parseInstance(o).toPrintable());try {//让线程晚点死亡TimeUnit.SECONDS.sleep(2);} catch (InterruptedException e) {e.printStackTrace();}}});Thread threadB = new Thread(() -> {synchronized (o) {log.info(ClassLayout.parseInstance(o).toPrintable());try {//让线程晚点死亡TimeUnit.SECONDS.sleep(2);} catch (InterruptedException e) {e.printStackTrace();}}});//两个线程同时启动,模拟并发同时请求threadA.start();threadB.start();}}
运行结果图,从图中我们看到,我们的对象头中的锁是不是已经成了重量级锁了,那么再来看看这段代码它是怎么模拟的,首先我们需要知道重量级锁它是在锁竞争非常激烈的时候才成为的,这段代码模拟的是,我启动两个线程,第一个线程对对象进行加锁,然后睡眠两秒,模拟程序在处理业务,然后第二个线程一直在等待第一个线程释放锁,在等待的过程中,会触发自旋锁,如果自旋锁达到了阈值,则会直接让第二个线程进行阻塞,从而线程2晋升为重量级锁
当然synchronized在1.6版本优化中还加了两个细节点的优化,例如锁粗化、锁消除这两个点。
锁粗化:
例如以下这段代码的极端情况
public class Test06 {public static void main(String[] args) {Object o = new Object();synchronized (o) {//业务逻辑处理System.out.println("锁粗化1");}synchronized (o) {//业务逻辑处理System.out.println("锁粗化2");}synchronized (o) {//业务逻辑处理System.out.println("锁粗化3");}}}
上面的代码是有三块需要同步操作的,但在这三块需要同步操作的代码之间,需要做业务逻辑的工作,而这些工作只会花费很少的时间,那么我们就可以把这些工作代码放入锁内,将三个同步代码块合并成一个,以降低多次锁请求、同步、释放带来的系统性能消耗,合并后的代码如下:
public class Test06 {public static void main(String[] args) {Object o = new Object();synchronized (o) {//业务逻辑处理System.out.println("锁粗化1");//业务逻辑处理System.out.println("锁粗化2");//业务逻辑处理System.out.println("锁粗化3");}}}
public class Test07 {public static void main(String[] args) {method();}public static void method() {Object o = new Object();synchronized (o) {System.out.println("锁消除");}}}
分析上面这段代码,前面说到过锁消除的依据是逃逸分析,当线程在调用我们的方法的时候,会对该方法进行逃逸分析,发现该方法里的对象不会被其他线程所共享,那么它会认为在里面进行加synchronized没有任何用处,所以最后会底层会将进行优化,将synchronized进行删除。那么这就是锁消除啦。
我是黎明大大,我知道我没有惊世的才华,也没有超于凡人的能力,但毕竟我还有一个不屈服,敢于选择向命运冲锋的灵魂,和一个就是伤痕累累也要义无反顾走下去的心。
如果您觉得本文对您有帮助,还请关注点赞一波,后期将不间断更新更多技术文章

