
MLlib流设计,特征工程
小编推荐
来源:子雨大数据
http://dblab.xmu.edu.cn/blog
【版权声明】博客内容由厦门大学数据库实验室拥有版权,未经允许,请勿转载!
内容:MLlib流设计,特征工程
第 6 节 Spark MLlib
6.1 Spark MLlib简介 http://dblab.xmu.edu.cn/blog/1723-2/
(1)、Spark 机器学习库MLLib
MLlib是Spark的机器学习(Machine Learning)库,旨在简化机器学习的工程实践工作,并方便扩展到更大规模。MLlib由一些通用的学习算法和工具组成,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化原语和高层的管道API。具体来说,其主要包括以下几方面的内容:
算法工具:常用的学习算法,如分类、回归、聚类和协同过滤;
特征化工具:特征提取、转化、降维,和选择工具;
管道(Pipeline):用于构建、评估和调整机器学习管道的工具;
持久性:保存和加载算法,模型和管道;
实用工具:线性代数,统计,数据处理等工具。
Spark 机器学习库从 1.2 版本以后被分为两个包:
spark.mllib 包含基于RDD的原始算法API。Spark MLlib 历史比较长,在1.0 以前的版本即已经包含了,提供的算法实现都是基于原始的 RDD。
spark.ml 则提供了基于DataFrames 高层次的API,可以用来构建机器学习工作流(PipeLine)。ML Pipeline 弥补了原始 MLlib 库的不足,向用户提供了一个基于 DataFrame 的机器学习工作流式 API 套件。
使用 ML Pipeline API可以很方便的把数据处理,特征转换,正则化,以及多个机器学习算法联合起来,构建一个单一完整的机器学习流水线。这种方式给我们提供了更灵活的方法,更符合机器学习过程的特点,也更容易从其他语言迁移。Spark官方推荐使用spark.ml。如果新的算法能够适用于机器学习管道的概念,就应该将其放到spark.ml包中,如:特征提取器和转换器。开发者需要注意的是,从Spark2.0开始,基于RDD的API进入维护模式(即不增加任何新的特性),并预期于3.0版本的时候被移除出MLLib。因此,我们将以ml包为主进行介绍。
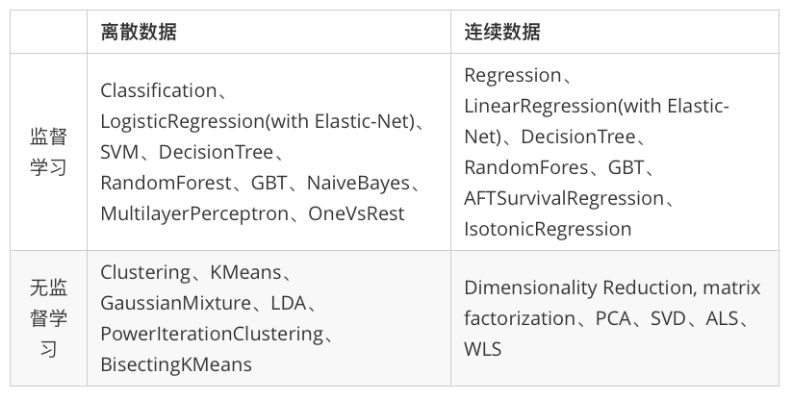
Spark在机器学习方面的发展非常快,目前已经支持了主流的统计和机器学习算法。纵观所有基于分布式架构的开源机器学习库,MLlib可以算是计算效率最高的。MLlib目前支持4种常见的机器学习问题: 分类、回归、聚类和协同过滤。下表列出了目前MLlib支持的主要的机器学习算法:
6.2 机器学习工作流 http://dblab.xmu.edu.cn/blog/1763-2/
1、工作流(ML Pipelines)例子
(1)、引入 pyspark 库
Spark2.0以上版本的pyspark创建一个名为spark的SparkSession对象,当需要手工创建时,SparkSession可以由其伴生对象的builder()方法创建出来,如下代码段所示:
# 引入 pyspark 库from pyspark.sql import SparkSessionspark = SparkSession.builder.master("local").appName("Word Count").getOrCreate()
from pyspark.ml import Pipelinefrom pyspark.ml.classification import LogisticRegressionfrom pyspark.ml.feature import HashingTF, Tokenizer
# Prepare training documents from a list of (id, text, label) tuples.training = spark.createDataFrame([(0, "a b c d e spark", 1.0),(1, "b d", 0.0),(2, "spark f g h", 1.0),(3, "hadoop mapreduce", 0.0)], ["id", "text", "label"])
tokenizer = Tokenizer(inputCol="text", outputCol="words")hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")lr = LogisticRegression(maxIter=10, regParam=0.001)
(2)、创建一个Pipeline
有了这些处理特定问题的转换器和评估器,接下来就可以按照具体的处理逻辑有序的组织PipelineStages 并创建一个Pipeline。
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])(3)、产生一个PipelineModel
现在构建的Pipeline本质上是一个Estimator,在它的fit()方法运行之后,它将产生一个PipelineModel,它是一个Transformer。
model = pipeline.fit(training)(4)、构建测试数据
我们可以看到,model的类型是一个PipelineModel,这个管道模型将在测试数据的时候使用。所以接下来,我们先构建测试数据。
test = spark.createDataFrame([(4, "spark i j k"),(5, "l m n"),(6, "spark hadoop spark"),(7, "apache hadoop")], ["id", "text"])
(5)、生成我们所需要的预测结果
然后,我们调用我们训练好的PipelineModel的transform()方法,让测试数据按顺序通过拟合的工作流,生成我们所需要的预测结果。
prediction = model.transform(test)selected = prediction.select("id", "text", "probability", "prediction")for row in selected.collect():rid, text, prob, prediction = rowprint("(%d, %s) --> prob=%s, prediction=%f" % (rid, text, str(prob), prediction))
运行结果
(4, spark i j k) --> prob=[0.1596407738787475,0.8403592261212525], prediction=1.000000(5, l m n) --> prob=[0.8378325685476744,0.16216743145232562], prediction=0.000000(6, spark hadoop spark) --> prob=[0.06926633132976037,0.9307336686702395], prediction=1.000000(7, apache hadoop) --> prob=[0.9821575333444218,0.01784246665557808], prediction=0.000000
6.3 特征抽取、转化和选择 http://dblab.xmu.edu.cn/blog/1709-2/
6.3.1、TF-IDF (HashingTF and IDF) http://dblab.xmu.edu.cn/blog/1766-2/
概念请看:
Datawhale-NLP实践——Task2.1-2.2 TF-IDF原理及实现 https://mp.weixin.qq.com/s?__biz=MzAxMTU5Njg4NQ==&mid=100000463&idx=2&sn=bba5bd250758e02fb1b4e065a236f4d4
1)、引入 pyspark 库
Spark2.0以上版本的pyspark创建一个名为spark的SparkSession对象,当需要手工创建时,SparkSession可以由其伴生对象的builder()方法创建出来,如下代码段所示:
# 引入 pyspark 库from pyspark.sql import SparkSessionspark = SparkSession.builder.master("local").appName("Word Count").getOrCreate()
2)、导入TFIDF所需要的包
首先,导入TFIDF所需要的包:
from pyspark.ml.feature import HashingTF,IDF,Tokenizer3) 创建数据
准备工作完成后,我们创建一个简单的DataFrame,每一个句子代表一个文档。
sentenceData = spark.createDataFrame([(0, "I heard about Spark and I love Spark"),(0, "I wish Java could use case classes"),(1, "Logistic regression models are neat")]).toDF("label", "sentence")4) 分词
在得到文档集合后,即可用tokenizer对句子进行分词
tokenizer = Tokenizer(inputCol="sentence", outputCol="words")wordsData = tokenizer.transform(sentenceData)
5)、把句子哈希成特征向量
得到分词后的文档序列后,即可使用HashingTF的transform()方法把句子哈希成特征向量,这里设置哈希表的桶数为2000。
hashingTF = HashingTF(inputCol="words", outputCol="rawFeatures", numFeatures=20)featurizedData = hashingTF.transform(wordsData)
可以看到,分词序列被变换成一个稀疏特征向量,其中每个单词都被散列成了一个不同的索引值,特征向量在某一维度上的值即该词汇在文档中出现的次数。
6)、训练模型
最后,使用IDF来对单纯的词频特征向量进行修正,使其更能体现不同词汇对文本的区别能力,IDF是一个Estimator,调用fit()方法并将词频向量传入,即产生一个IDFModel。
idf = IDF(inputCol="rawFeatures", outputCol="features")idfModel = idf.fit(featurizedData)
很显然,IDFModel是一个Transformer,调用它的transform()方法,即可得到每一个单词对应的TF-IDF度量值。
rescaledData = idfModel.transform(featurizedData)rescaledData.select("label", "features").show()
+-----+--------------------+|label| features|+-----+--------------------+| 0|(20,[0,5,9,13,17]...|| 0|(20,[2,7,9,13,15]...|| 1|(20,[4,6,13,15,18...|+-----+--------------------+
可以看到,特征向量已经被其在语料库中出现的总次数进行了修正,通过TF-IDF得到的特征向量,在接下来可以被应用到相关的机器学习方法中。
6.3.2、特征抽取:Word2Vec http://dblab.xmu.edu.cn/blog/1766-2/
概念请看:
Task 6.1. 文本表示:从one-hot到word2vec https://mp.weixin.qq.com/s?__biz=MzAxMTU5Njg4NQ==&mid=100000893&idx=2&sn=3eed143ba5dd759dc61a496acf2f9496
# 引入 pyspark 库from pyspark.sql import SparkSessionspark = SparkSession.builder.master("local").appName("Word Count").getOrCreate()from pyspark.ml.feature import Word2Vec
documentDF = spark.createDataFrame([("Hi I heard about Spark".split(" "), ),("I wish Java could use case classes".split(" "), ),("Logistic regression models are neat".split(" "), )], ["text"])
3)、模型构建
新建一个Word2Vec,显然,它是一个Estimator,设置相应的超参数,这里设置特征向量的维度为3,Word2Vec模型还有其他可设置的超参数,具体的超参数描述可以参见这里。
word2Vec = Word2Vec(vectorSize=3, minCount=0, inputCol="text", outputCol="result")4)、读入训练数据,用fit()方法生成一个Word2VecModel
model = word2Vec.fit(documentDF)5)、利用Word2VecModel把文档转变成特征向量
result = model.transform(documentDF)for row in result.collect():text, vector = rowprint("Text: [%s] => \nVector: %s\n" % (", ".join(text), str(vector)))
Text: [Hi, I, heard, about, Spark] =>Vector: [-0.02481612414121628,0.030189220979809764,-0.043382836133241655]Text: [I, wish, Java, could, use, case, classes] =>Vector: [-0.015328743628093174,0.01850887880261455,0.041017367687475464]Text: [Logistic, regression, models, are, neat] =>Vector: [-0.020753448456525804,-0.046902849525213244,0.031090765446424487]
(3)、特征抽取–CountVectorizer http://dblab.xmu.edu.cn/blog/1769-2/
1)、 首先,导入CountVectorizer所需要的包
from pyspark.ml.feature import CountVectorizer2)、假设我们有如下的DataFrame,其包含id和words两列,可以看成是一个包含两个文档的迷你语料库
df = spark.createDataFrame([(0, "a b c".split(" ")),(1, "a b b c a".split(" "))], ["id", "words"])
3)、随后,通过CountVectorizer设定超参数,训练一个CountVectorizer,这里设定词汇表的最大量为3,设定词汇表中的词至少要在2个文档中出现过,以过滤那些偶然出现的词汇
# fit a CountVectorizerModel from the corpus.cv = CountVectorizer(inputCol="words", outputCol="features", vocabSize=3, minDF=2.0)
4)、在训练结束后,可以通过cv对DataFrame进行fit,获得到模型的词汇表
model = cv.fit(df)# 使用这一模型对DataFrame进行变换,可以得到文档的向量化表示
result = model.transform(df)result.show(truncate=False)
+---+---------------+-------------------------+|id |words |features |+---+---------------+-------------------------+|0 |[a, b, c] |(3,[0,1,2],[1.0,1.0,1.0])||1 |[a, b, b, c, a]|(3,[0,1,2],[2.0,2.0,1.0])|+---+---------------+-------------------------+
for row in result.collect():id,text, vector = rowprint("Id:{%s}=> \nText: [%s] => \nVector: %s\n" % (str(id),", ".join(text), str(vector)))
Id:{0}=>Text: [a, b, c] =>Vector: (3,[0,1,2],[1.0,1.0,1.0])Id:{1}=>Text: [a, b, b, c, a] =>Vector: (3,[0,1,2],[2.0,2.0,1.0])
(3)、特征变换–标签和索引的转化(Python版) http://dblab.xmu.edu.cn/blog/1770-2/
Spark ML包中提供了几个相关的转换器,例如:StringIndexer、IndexToString、OneHotEncoder、VectorIndexer,它们提供了十分方便的特征转换功能,这些转换器类都位于org.apache.spark.ml.feature包下。
值得注意的是,用于特征转换的转换器和其他的机器学习算法一样,也属于ML Pipeline模型的一部分,可以用来构成机器学习流水线,以StringIndexer为例,其存储着进行标签数值化过程的相关 超参数,是一个Estimator,对其调用fit(..)方法即可生成相应的模型StringIndexerModel类,很显然,它存储了用于DataFrame进行相关处理的 参数,是一个Transformer(其他转换器也是同一原理) 下面对几个常用的转换器依次进行介绍。
1)、StringIndexer
StringIndexer转换器可以把一列类别型的特征(或标签)进行编码,使其数值化,索引的范围从0开始,该过程可以使得相应的特征索引化,使得某些无法接受类别型特征的算法可以使用,并提高诸如决策树等机器学习算法的效率。
索引构建的顺序为标签的频率,优先编码频率较大的标签,所以出现频率最高的标签为0号。 如果输入的是数值型的,我们会把它转化成字符型,然后再对其进行编码。
首先,引入必要的包,并创建一个简单的DataFrame,它只包含一个id列和一个标签列category:
from pyspark.ml.feature import StringIndexerdf = spark.createDataFrame([],[])
随后,我们创建一个StringIndexer对象,设定输入输出列名,其余参数采用默认值,并对这个DataFrame进行训练,产生StringIndexerModel对象:
indexer = StringIndexer(inputCol="category", outputCol="categoryIndex")model = indexer.fit(df)
随后即可利用该对象对DataFrame进行转换操作,可以看到,StringIndexerModel依次按照出现频率的高低,把字符标签进行了排序,即出现最多的“a”被编号成0,“c”为1,出现最少的“b”为0。
+---+--------+-------------+| id|category|categoryIndex|+---+--------+-------------+| 0| a| 0.0|| 1| b| 2.0|| 2| c| 1.0|| 3| a| 0.0|| 4| a| 0.0|| 5| c| 1.0|+---+--------+-------------+
2)、IndexToString
与StringIndexer相对应,IndexToString的作用是把标签索引的一列重新映射回原有的字符型标签。
其主要使用场景一般都是和StringIndexer配合,先用StringIndexer将标签转化成标签索引,进行模型训练,然后在预测标签的时候再把标签索引转化成原有的字符标签。当然,你也可以另外定义其他的标签。
首先,和StringIndexer的实验相同,我们用StringIndexer读取数据集中的“category”列,把字符型标签转化成标签索引,然后输出到“categoryIndex”列上,构建出新的DataFrame。
from pyspark.ml.feature import IndexToString, StringIndexerdf = spark.createDataFrame([(0, "a"), (1, "b"), (2, "c"), (3, "a"), (4, "a"), (5, "c")],["id", "category"])indexer = StringIndexer(inputCol="category", outputCol="categoryIndex")model = indexer.fit(df)indexed = model.transform(df)
随后,创建IndexToString对象,读取“categoryIndex”上的标签索引,获得原有数据集的字符型标签,然后再输出到“originalCategory”列上。最后,通过输出“originalCategory”列,可以看到数据集中原有的字符标签。
converter = IndexToString(inputCol="categoryIndex", outputCol="originalCategory")converted = converter.transform(indexed)converted.select("id", "categoryIndex", "originalCategory").show()
+---+-------------+----------------+| id|categoryIndex|originalCategory|+---+-------------+----------------+| 0| 0.0| a|| 1| 2.0| b|| 2| 1.0| c|| 3| 0.0| a|| 4| 0.0| a|| 5| 1.0| c|+---+-------------+----------------+
3)、OneHotEncoder
独热编码(One-Hot Encoding) 是指把一列类别性特征(或称名词性特征,nominal/categorical features)映射成一系列的二元连续特征的过程,原有的类别性特征有几种可能取值,这一特征就会被映射成几个二元连续特征,每一个特征代表一种取值,若该样本表现出该特征,则取1,否则取0。
One-Hot编码适合一些期望类别特征为连续特征的算法,比如说逻辑斯蒂回归等。
首先创建一个DataFrame,其包含一列类别性特征,需要注意的是,在使用OneHotEncoder进行转换前,DataFrame需要先使用StringIndexer将原始标签数值化:
from pyspark.ml.feature import OneHotEncoder, StringIndexerdf = spark.createDataFrame([(0, "a"),(1, "b"),(2, "c"),(3, "a"),(4, "a"),(5, "c")], ["id", "category"])stringIndexer = StringIndexer(inputCol="category", outputCol="categoryIndex")model = stringIndexer.fit(df)indexed = model.transform(df)
随后,我们创建OneHotEncoder对象对处理后的DataFrame进行编码,可以看见,编码后的二进制特征呈稀疏向量形式,与StringIndexer编码的顺序相同,需注意的是最后一个Category(”b”)被编码为全0向量,若希望”b”也占有一个二进制特征,则可在创建OneHotEncoder时指定setDropLast(false)。
encoder = OneHotEncoder(inputCol="categoryIndex", outputCol="categoryVec")encoded = encoder.transform(indexed)encoded.show()
+---+--------+-------------+-------------+| id|category|categoryIndex| categoryVec|+---+--------+-------------+-------------+| 0| a| 0.0|(2,[0],[1.0])|| 1| b| 2.0| (2,[],[])|| 2| c| 1.0|(2,[1],[1.0])|| 3| a| 0.0|(2,[0],[1.0])|| 4| a| 0.0|(2,[0],[1.0])|| 5| c| 1.0|(2,[1],[1.0])|+---+--------+-------------+-------------+
4)、VectorIndexer
之前介绍的StringIndexer是针对单个类别型特征进行转换,倘若所有特征都已经被组织在一个向量中,又想对其中某些单个分量进行处理时,Spark ML提供了VectorIndexer类来解决向量数据集中的类别性特征转换。
通过为其提供maxCategories超参数,它可以自动识别哪些特征是类别型的,并且将原始值转换为类别索引。它基于不同特征值的数量来识别哪些特征需要被类别化,那些取值可能性最多不超过maxCategories的特征需要会被认为是类别型的。
在下面的例子中,我们读入一个数据集,然后使用VectorIndexer训练出模型,来决定哪些特征需要被作为类别特征,将类别特征转换为索引,这里设置maxCategories为10,即只有种类小10的特征才被认为是类别型特征,否则被认为是连续型特征:
from pyspark.ml.feature import VectorIndexerdata = spark.read.format('libsvm').load('../resources/sample_libsvm_data.txt')indexer = VectorIndexer(inputCol="features", outputCol="indexed", maxCategories=10)indexerModel = indexer.fit(data)categoricalFeatures = indexerModel.categoryMapsindexedData = indexerModel.transform(data)indexedData.show()
+-----+--------------------+--------------------+|label| features| indexed|+-----+--------------------+--------------------+| 0.0|(692,[127,128,129...|(692,[127,128,129...|| 1.0|(692,[158,159,160...|(692,[158,159,160...|| 1.0|(692,[124,125,126...|(692,[124,125,126...|| 1.0|(692,[152,153,154...|(692,[152,153,154...|| 1.0|(692,[151,152,153...|(692,[151,152,153...|| 0.0|(692,[129,130,131...|(692,[129,130,131...|| 1.0|(692,[158,159,160...|(692,[158,159,160...|| 1.0|(692,[99,100,101,...|(692,[99,100,101,...|| 0.0|(692,[154,155,156...|(692,[154,155,156...|| 0.0|(692,[127,128,129...|(692,[127,128,129...|| 1.0|(692,[154,155,156...|(692,[154,155,156...|| 0.0|(692,[153,154,155...|(692,[153,154,155...|| 0.0|(692,[151,152,153...|(692,[151,152,153...|| 1.0|(692,[129,130,131...|(692,[129,130,131...|| 0.0|(692,[154,155,156...|(692,[154,155,156...|| 1.0|(692,[150,151,152...|(692,[150,151,152...|| 0.0|(692,[124,125,126...|(692,[124,125,126...|| 0.0|(692,[152,153,154...|(692,[152,153,154...|| 1.0|(692,[97,98,99,12...|(692,[97,98,99,12...|| 1.0|(692,[124,125,126...|(692,[124,125,126...|+-----+--------------------+--------------------+
(4)、特征选取–卡方选择器(Python版) http://dblab.xmu.edu.cn/blog/1771-2/
特征选择(Feature Selection)指的是在特征向量中选择出那些“优秀”的特征,组成新的、更“精简”的特征向量的过程。它在高维数据分析中十分常用,可以剔除掉“冗余”和“无关”的特征,提升学习器的性能。
特征选择方法和分类方法一样,也主要分为有监督(Supervised)和无监督(Unsupervised)两种,卡方选择则是统计学上常用的一种有监督特征选择方法,它通过对特征和真实标签之间进行卡方检验,来判断该特征和真实标签的关联程度,进而确定是否对其进行选择。
和ML库中的大多数学习方法一样,ML中的卡方选择也是以estimator+transformer的形式出现的,其主要由ChiSqSelector和ChiSqSelectorModel两个类来实现。
在进行实验前,首先进行环境的设置。引入卡方选择器所需要使用的类:
from pyspark.ml.feature import ChiSqSelectorfrom pyspark.ml.linalg import Vectors# 默认名为spark的SparkSession已经创建。
df = spark.createDataFrame([(7, Vectors.dense([0.0, 0.0, 18.0, 1.0]), 1.0,),(8, Vectors.dense([0.0, 1.0, 12.0, 0.0]), 0.0,),(9, Vectors.dense([1.0, 0.0, 15.0, 0.1]), 0.0,)], ["id", "features", "clicked"])
selector = ChiSqSelector(numTopFeatures=1, featuresCol="features",outputCol="selectedFeatures", labelCol="clicked")
result = selector.fit(df).transform(df)result.show()
+---+------------------+-------+----------------+| id| features|clicked|selectedFeatures|+---+------------------+-------+----------------+| 7|[0.0,0.0,18.0,1.0]| 1.0| [18.0]|| 8|[0.0,1.0,12.0,0.0]| 0.0| [12.0]|| 9|[1.0,0.0,15.0,0.1]| 0.0| [15.0]|+---+------------------+-------+----------------+
for row in result.collect():id, features, clicked,selectedFeatures = rowfeatures = list(map(str,features))print("Id:{%s} => \nFeatures: [%s] => \n Clicked: %s => \n SelectedFeatures: %s\n" % (str(id),", ".join(features), str(clicked), str(selectedFeatures[0])))
Id:{7} =>Features: [0.0, 0.0, 18.0, 1.0] =>Clicked: 1.0 =>SelectedFeatures: 18.0Id:{8} =>Features: [0.0, 1.0, 12.0, 0.0] =>Clicked: 0.0 =>SelectedFeatures: 12.0Id:{9} =>Features: [1.0, 0.0, 15.0, 0.1] =>Clicked: 0.0 =>SelectedFeatures: 15.0