
机器学习之特征工程
转自文章:
https://blog.csdn.net/Dream_angel_Z/article/details/49388733
关于特征工程(Feature Engineering),已经是很古老很常见的话题了,坊间常说:“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已”。由此可见,特征工程在机器学习中占有相当重要的地位。在实际应用当中,可以说特征工程是机器学习成功的关键。纵观Kaggle、KDD等国内外大大小小的比赛,每个竞赛的冠军其实并没有用到很高深的算法,大多数都是在特征工程这个环节做出了出色的工作,然后使用一些常见的算法,比如LR,就能得到出色的性能。遗憾的是,在很多的书籍中并没有直接提到Feature Engineering,更多的是Feature selection。这也并不,很多ML书籍都是以讲解算法为主,他们的目的是从理论到实践来理解算法,所以用到的数据要么是使用代码生成的,要么是已经处理好的数据,并没有提到特征工程。在这篇文章,我打算自我总结下特征工程,让自己对特征工程有个全面的认识。在这我要说明一下,我并不是说那些书写的不好,其实都很有不错,主要是因为它们的目的是理解算法,所以直接给出数据相对而言对于学习和理解算法效果更佳。
这篇文章主要从以下三个问题出发来理解特征工程:
特征工程是什么?
为什么要做特征工程?
应该如何做特征工程?
对于第一个问题,我会通过特征工程的目的来解释什么是特征工程。对于第二个问题,主要从特征工程的重要性来阐述。对于第三个问题,我会从特征工程的子问题以及简单的处理方法来进一步说明。下面来看看详细内容!
1、特征工程是什么
首先来解释下什么是特征工程?
当你想要你的预测模型性能达到最佳时,你要做的不仅是要选取最好的算法,还要尽可能的从原始数据中获取更多的信息。那么问题来了,你应该如何为你的预测模型得到更好的数据呢?
想必到了这里你也应该猜到了,是的,这就是特征工程要做的事,它的目的就是获取更好的训练数据。
关于特征工程的定义,Wikipedia上是这样说的:
Feature engineering is the process of using domain knowledge of the data to create features that make machine learning algorithms work.
我的理解:
特征工程是利用数据领域的相关知识来创建能够使机器学习算法达到最佳性能的特征的过程。
简而言之,特征工程就是一个把原始数据转变成特征的过程,这些特征可以很好的描述这些数据,并且利用它们建立的模型在未知数据上的表现性能可以达到最优(或者接近最佳性能)。从数学的角度来看,特征工程就是人工地去设计输入变量X。
特征工程更是一门艺术,跟编程一样。导致许多机器学习项目成功和失败的主要因素就是使用了不同的特征。说了这么多,想必你也大概知道了为什么要做特征工程,下面来说说特征工程的重要性。
2、特征工程的重要性
OK!知道了特征工程是什么,那么我们必须要来了解下特征工程的重要性,为什么在实际工作中都要有特征工程这个过程,下面不同的角度来分析一下。
首先,我们大家都知道,数据特征会直接影响我们模型的预测性能。你可以这么说:“选择的特征越好,最终得到的性能也就越好”。这句话说得没错,但也会给我们造成误解。事实上,你得到的实验结果取决于你选择的模型、获取的数据以及使用的特征,甚至你问题的形式和你用来评估精度的客观方法也扮演了一部分。此外,你的实验结果还受到许多相互依赖的属性的影响,你需要的是能够很好地描述你数据内部结构的好特征。
(1)特征越好,灵活性越强
只要特征选得好,即使是一般的模型(或算法)也能获得很好的性能,因为大多数模型(或算法)在好的数据特征下表现的性能都还不错。好特征的灵活性在于它允许你选择不复杂的模型,同时运行速度也更快,也更容易理解和维护。
(2)特征越好,构建的模型越简单
有了好的特征,即便你的参数不是最优的,你的模型性能也能仍然会表现的很nice,所以你就不需要花太多的时间去寻找最有参数,这大大的降低了模型的复杂度,使模型趋于简单。
(3)特征越好,模型的性能越出色
显然,这一点是毫无争议的,我们进行特征工程的最终目的就是提升模型的性能。
下面从特征的子问题来分析下特征工程。
3、特征工程子问题
大家通常会把特征工程看做是一个问题。事实上,在特征工程下面,还有许多的子问题,主要包括:Feature Selection(特征选择)、Feature Extraction(特征提取)和Feature construction(特征构造).下面从这三个子问题来详细介绍。
3.1 特征选择Feature Selection
首先,从特征开始说起,假设你现在有一个标准的Excel表格数据,它的每一行表示的是一个观测样本数据,表格数据中的每一列就是一个特征。在这些特征中,有的特征携带的信息量丰富,有的(或许很少)则属于无关数据(irrelevant data),我们可以通过特征项和类别项之间的相关性(特征重要性)来衡量。比如,在实际应用中,常用的方法就是使用一些评价指标单独地计算出单个特征跟类别变量之间的关系。如Pearson相关系数,Gini-index(基尼指数),IG(信息增益)等,下面举Pearson指数为例,它的计算方式如下:
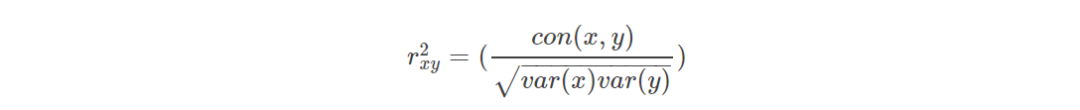
其中,x属于X,X表一个特征的多个观测值,y表示这个特征观测值对应的类别列表。
Pearson相关系数的取值在0到1之间,如果你使用这个评价指标来计算所有特征和类别标号的相关性,那么得到这些相关性之后,你可以将它们从高到低进行排名,然后选择一个子集作为特征子集(比如top 10%),接着用这些特征进行训练,看看性能如何。此外,你还可以画出不同子集的一个精度图,根据绘制的图形来找出性能最好的一组特征。
这就是特征工程的子问题之一——特征选择,它的目的是从特征集合中挑选一组最具统计意义的特征子集,从而达到降维的效果。
做特征选择的原因是因为这些特征对于目标类别的作用并不是相等的,一些无关的数据需要删掉。做特征选择的方法有多种,上面提到的这种特征子集选择的方法属于filter(刷选器)方法,它主要侧重于单个特征跟目标变量的相关性。优点是计算时间上较高效,对于过拟合问题也具有较高的鲁棒性。缺点就是倾向于选择冗余的特征,因为他们不考虑特征之间的相关性,有可能某一个特征的分类能力很差,但是它和某些其它特征组合起来会得到不错的效果。另外做特征子集选取的方法还有wrapper(封装器)和Embeded(集成方法)。wrapper方法实质上是一个分类器,封装器用选取的特征子集对样本集进行分类,分类的精度作为衡量特征子集好坏的标准,经过比较选出最好的特征子集。常用的有逐步回归(Stepwise regression)、向前选择(Forward selection)和向后选择(Backward selection)。它的优点是考虑了特征与特征之间的关联性,缺点是:当观测数据较少时容易过拟合,而当特征数量较多时,计算时间又会增长。对于Embeded集成方法,它是学习器自身自主选择特征,如使用Regularization做特征选择,或者使用决策树思想,细节这里就不做介绍了。这里还提一下,在做实验的时候,我们有时候会用Random Forest和Gradient boosting做特征选择,本质上都是基于决策树来做的特征选择,只是细节上有些区别。
综上所述,特征选择过程一般包括产生过程,评价函数,停止准则,验证过程,这4个部分。如下图所示:
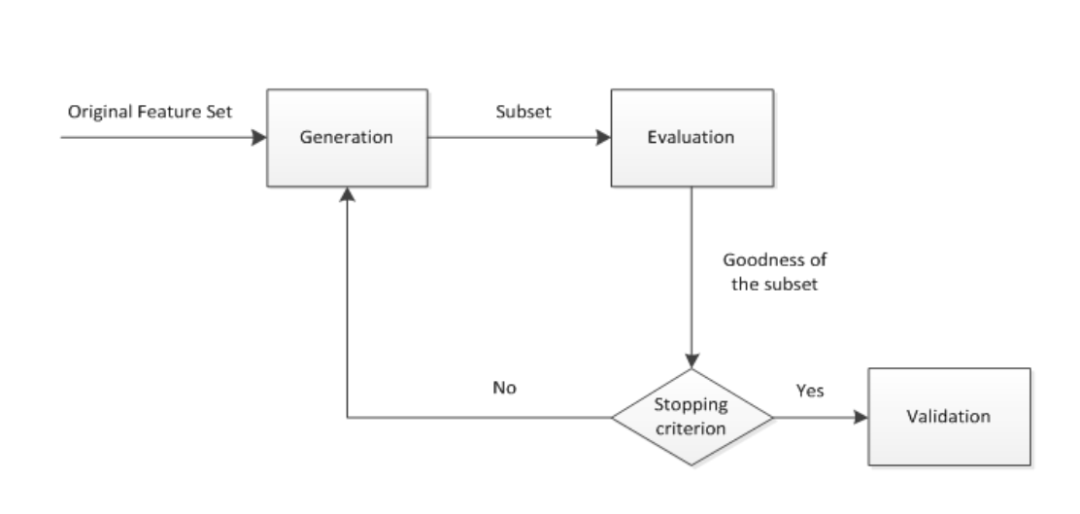
(1) 产生过程( Generation Procedure ):产生过程是搜索特征子集的过程,负责为评价函数提供特征子集。搜索特征子集的过程有多种,将在2.2小节展开介绍。
(2) 评价函数( Evaluation Function ):评价函数是评价一个特征子集好坏程度的一个准则。评价函数将在2.3小节展开介绍。
(3) 停止准则( Stopping Criterion ):停止准则是与评价函数相关的,一般是一个阈值,当评价函数值达到这个阈值后就可停止搜索。
(4) 验证过程( Validation Procedure ) :在验证数据集上验证选出来的特征子集的有效性。
3.2 特征提取
特征提取的子问题之二——特征提取。
原则上来讲,特征提取应该在特征选择之前。特征提取的对象是原始数据(raw data),它的目的是自动地构建新的特征,将原始特征转换为一组具有明显物理意义(Gabor、几何特征[角点、不变量]、纹理[LBP HOG])或者统计意义或核的特征。比如通过变换特征取值来减少原始数据中某个特征的取值个数等。对于表格数据,你可以在你设计的特征矩阵上使用主要成分分析(Principal Component Analysis,PCA)来进行特征提取从而创建新的特征。对于图像数据,可能还包括了线或边缘检测。
常用的方法有:
PCA (Principal component analysis,主成分分析)
ICA (Independent component analysis,独立成分分析)
LDA (Linear Discriminant Analysis,线性判别分析)
对于图像识别中,还有SIFT方法。
3.3 特征构建 Feature Construction
特征提取的子问题之二——特征构建。
在上面的特征选择部分,我们提到了对特征重要性进行排名。那么,这些特征是如何得到的呢?在实际应用中,显然是不可能凭空而来的,需要我们手工去构建特征。关于特征构建的定义,可以这么说:特征构建指的是从原始数据中人工的构建新的特征。我们需要人工的创建它们。这需要我们花大量的时间去研究真实的数据样本,思考问题的潜在形式和数据结构,同时能够更好地应用到预测模型中。
特征构建需要很强的洞察力和分析能力,要求我们能够从原始数据中找出一些具有物理意义的特征。假设原始数据是表格数据,一般你可以使用混合属性或者组合属性来创建新的特征,或是分解或切分原有的特征来创建新的特征。
4、特征工程处理过程
那么问题来了,特征工程具体是在哪个步骤做呢?
具体的机器学习过程是这样的一个过程:
1.(Task before here)
2.选择数据(Select Data): 整合数据,将数据规范化成一个数据集,收集起来.
3.数据预处理(Preprocess Data): 数据格式化,数据清理,采样等.
4.数据转换(Transform Data): 这个阶段做特征工程.
5.数据建模(Model Data): 建立模型,评估模型并逐步优化.
(Tasks after here…)
我们发现,特征工程和数据转换其实是等价的。事实上,特征工程是一个迭代过程,我们需要不断的设计特征、选择特征、建立模型、评估模型,然后才能得到最终的model。下面是特征工程的一个迭代过程:
1.头脑风暴式特征:意思就是进你可能的从原始数据中提取特征,暂时不考虑其重要性,对应于特征构建;
2.设计特征:根据你的问题,你可以使用自动地特征提取,或者是手工构造特征,或者两者混合使用;
3.选择特征:使用不同的特征重要性评分和特征选择方法进行特征选择;
4.评估模型:使用你选择的特征进行建模,同时使用未知的数据来评估你的模型精度。
By the way, 在做feature selection的时候,会涉及到特征学习(Feature Learning),这里说下特征学习的概念,一般而言,特征学习(Feature Learning)是指学习输入特征和一个训练实例真是类别之间的关系。
下面举个例子来简单了解下特征工程的处理。
首先是来说下特征提取,假设你的数据里现在有一个颜色类别的属性,比如是“item_Color”,它的取值有三个,分别是:red,blue,unknown。从特征提取的角度来看,你可以将其转化成一个二值特征“has_color”,取值为1或0。其中1表示有颜色,0表示没颜色。你还可以将其转换成三个二值属性:Is_Red, Is_Blue and Is_Unknown。这样构建特征之后,你就可以使用简单的线性模型进行训练了。
另外再举一个例子,假设你有一个日期时间 (i.e. 2014-09-20T20:45:40Z),这个该如何转换呢?
对于这种时间的数据,我们可以根据需求提取出多种属性。比如,如果你想知道某一天的时间段跟其它属性的关系,你可以创建一个数字特征“Hour_Of_Day”来帮你建立一个回归模型,或者你可以建立一个序数特征,“Part_Of_Day”,取值“Morning,Midday,Afternoon,Night”来关联你的数据。
此外,你还可以按星期或季度来构建属性,等等等等……
关于特征构建,主要是尽可能的从原始数据中构建特征,而特征选择,经过上面的分析,想必大家也知道了,其实就是达到一个降维的效果。
只要分析能力和实践能力够强,那么特征构建和特征提取对你而言就会显得相对比较简单,所以抓紧时间好好实践吧!
Conclusion
恩。说了这么多,大家可能对特征工程、特征选择、特征提取和特征构建有点混乱了,下面来简单的做个总结:
首先来说说这几个术语:
特征工程:利用数据领域的相关知识来创建能够使机器学习算法达到最佳性能的特征的过程。
特征构建:是原始数据中人工的构建新的特征。
特征提取:自动地构建新的特征,将原始特征转换为一组具有明显物理意义或者统计意义或核的特征。
特征选择:从特征集合中挑选一组最具统计意义的特征子集,从而达到降维的效果
了解这几个术语的意思后,我们来看看他们之间的关系。
在Quora中有人这么说:
Feature engineering is a super-set of activities which include feature extraction, feature construction and feature selection. Each of the three are important steps and none should be ignored. We could make a generalization of the importance though, from my experience the relative importance of the steps would be feature construction > feature extraction > feature selection.
用中文来说就是:特征工程是一个超集,它包括特征提取、特征构建和特征选择这三个子模块。在实践当中,每一个子模块都非常重要,忽略不得。根据答主的经验,他将这三个子模块的重要性进行了一个排名,即:特征构建>特征提取>特征选择。
事实上,真的是这样,如果特征构建做的不好,那么它会直接影响特征提取,进而影响了特征选择,最终影响模型的性能。
OK!关于特征工程就到此为止吧,如果有纰漏的地方,还望大家多多指导!作为一枚行走在ML界的程序员,就让我们快乐的建模,快乐的做特征工程吧^_^!Happy coding, happy modeling!
References
Neglected machine learning ideas
Q&A with Xavier Conort
https://www.quora.com/What-is-feature-engineering
Feature_engineering-wikipedia
An Introduction to Feature Selection
Discover Feature Engineering, How to Engineer Features and How to Get Good at It
How valuable do you think feature selection is in machine learning? Which do you think improves accuracy more, feature selection or feature engineering?