
思考NLP和CV中的Local和Global建模
【写在前面】
CNN的感受野受卷积核大小的限制,导致了CNN实际上是一种Local的信息建模;而Self-Attention(SA)是将每个位置和所有位置计算attention weight,考虑了每个点之间的联系,因此SA是一种Global的建模。
起初,CNN大多用在CV领域中,而SA大多用在NLP领域中。但是随着SA和CNN各自优缺点的显现(如下表所示),越来越多的文章对这两个结构进行了混合的应用,使得模型不仅能够捕获全局的信息,还能建模局部信息来建模更加细粒度的信息。本文将结合两篇NLP和CV的文章,对全局信息建模(SA)和局部信息建模(CNN)进行进一步的分析。
CNN和SA的优缺点分析:

1)Conv的卷积核是静态的,是与输入的特征无关的;Self-Attention的权重是根据QKV动态计算得到的,所以Self-Attention的动态自适应加权的。
2)对卷积来说,它只关心每个位置周围的特征,因此卷积具有平移不变性。但是Self-Attention不具备这个性质。
3)Conv的感知范围受卷积核大小的限制,而大范围的感知能力有利于模型获得更多的上下文信息。Self-Attention是对特征进行全局感知。
1.CNN和SA在NLP中的联合应用
1.1. 论文地址和代码
MUSE:Parallel Multi-Scale Attention for Sequence to Sequence Learning
论文地址:https://arxiv.org/abs/1911.09483
代码地址:https://github.com/lancopku/MUSE
核心代码:https://github.com/xmu-xiaoma666/External-Attention-pytorch/blob/master/attention/MUSEAttention.py
1.2. Motivation
Transformer在NLP领域曾经掀起了热潮,原因是SA对句子序列的建模能力非常强,性能上远超RNN等结构,对RNN-based NLP时代进行了革新。
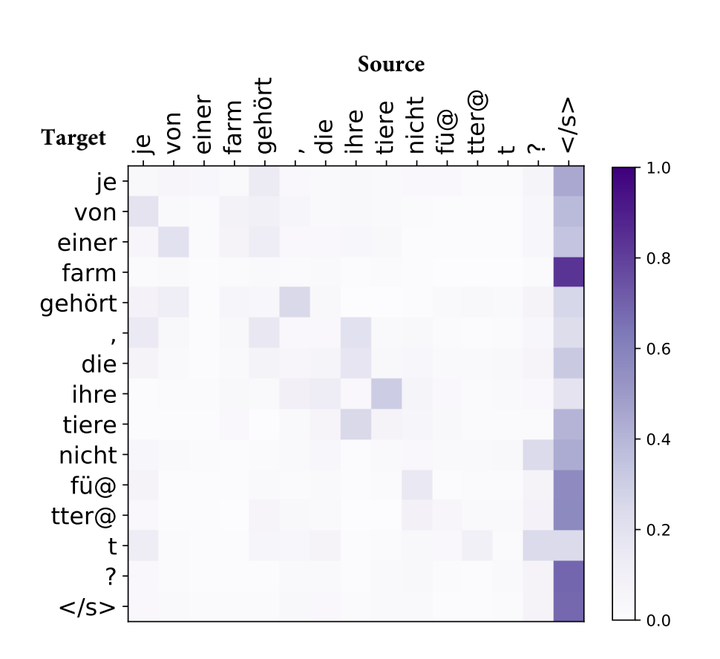
但是一些研究表明,SA对于短句子的建模非常有效,对于长句子的建模能力就会减弱。原因是SA建模时注意力会过度集中或过度分散,如下图所示,有的区域几乎没有attention,有的区域会有特别大的attention weight,另外大部分区域的attention weight都比较小,只有很少一部分的区域的attention weight比较大。
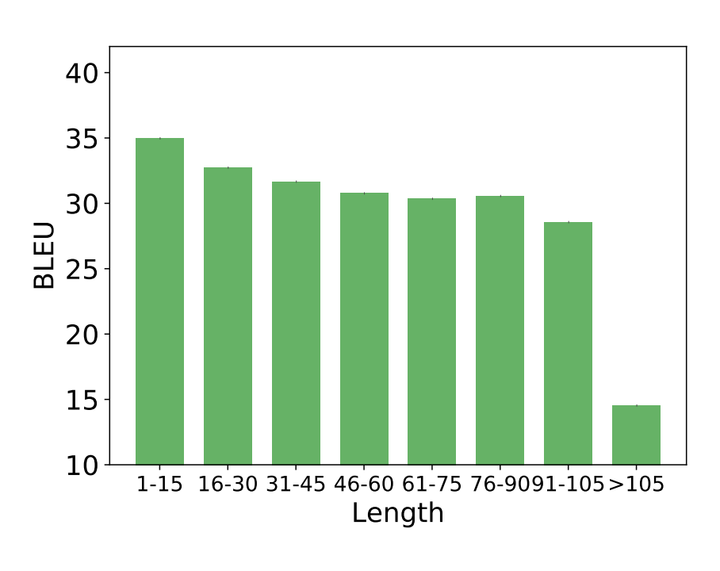
除此之外,如下图所示,SA在短句子上的效果非常好,在长句子的效果极具下降,也在一定程度上显示了SA对于长句子序列建模能力的不足。(这一点我倒是不太赞同,因为,可能是因为本身长句子包含的信息更加丰富(或者信息更加冗余),所以对于模型来说,长句子序列的学习本身就比短句子要难,所以也会导致性能的下降。因此,是否是因为SA对长句子序列建模能力的不足导致的性能下降,还需要做进一步的实验)
基于以上的发现,作者提出了通过引入多尺度的CNN,在不同尺度上进行局部信息的感知,由此来提升SA全局建模能力的不足。
1.3. 方法
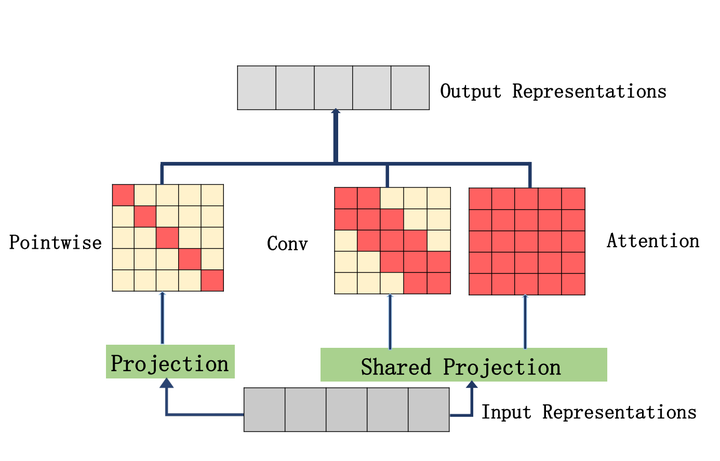
模型结构如上图所示,作者将原来只能对特征进行全局建模的SA换成能够进行多尺度建模的CNN与SA的结合(Multi-Scale Attention)。
在卷积方面作者用的是深度可分离卷积:
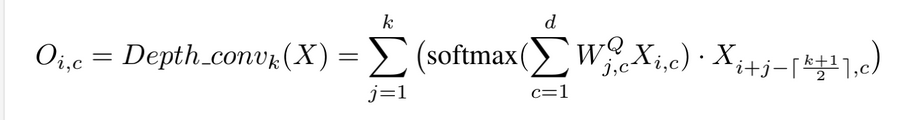
此外,除了感受野为1的特征,其他尺度的Attention在进行特征映射的时候都采用了与SA参数共享的映射矩阵。
为了能够动态选择不同感受野处理之后的特征,作者还对各个卷积核处理之后的结果进行了动态加权:
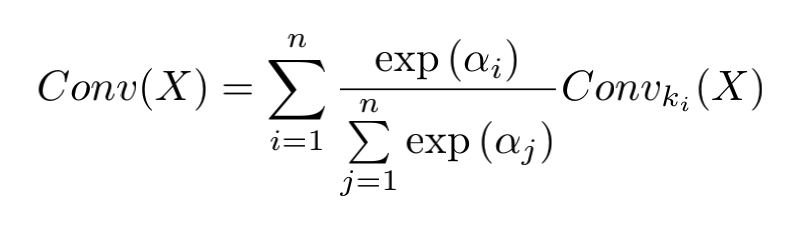
1.4. 实验
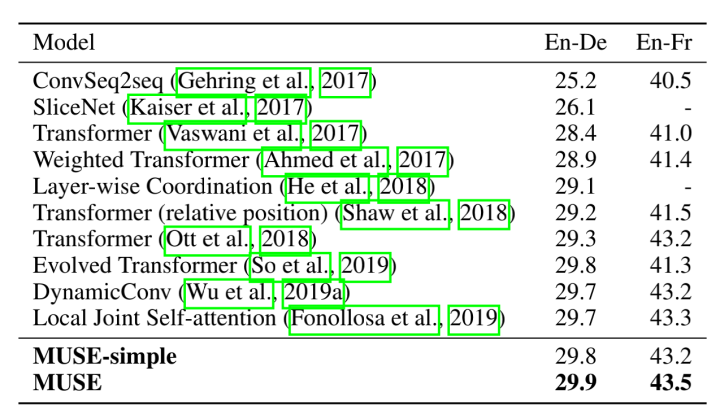
在翻译任务上,MUSE模型能够超过其他的所有模型。
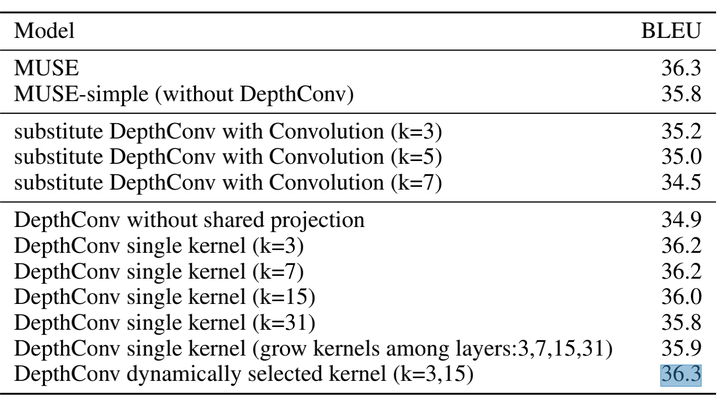
在感受野的选择方面,如果只采用一个卷积,那么k=3或7的时候效果比较好;采用多个卷积,比采用单个卷积的效果要更好一些。
2. CV中CNN和SA的联合应用
2.1. 论文地址代码
CoAtNet: Marrying Convolution and Attention for All Data Sizes
论文地址:https://arxiv.org/abs/2106.04803
官方代码:未开源
核心代码:https://github.com/xmu-xiaoma666/External-Attention-pytorch/blob/master/attention/CoAtNet.py
2.2. Motivation
在本文的【写在前面】,我们提到了CNN有一个特点,叫做平移不变性。这是CV任务中的一个假设偏置,对于提高模型在CV任务上的泛化能力是非常重要的。而SA对于捕获图片的全局信息是非常重要的,能够极大的提高模型的学习能力。因此,作者就想到了,将这两者都用到了CV任务中,让模型不仅拥有很强的泛化能力,也能拥有很强的学习能力。
2.3. 方法&实验
本文倒是没有提什么特别新颖的方法,不过CNN和SA的串联结构做了详细的实验。首先作者提出了四种结构,1)C-C-C-C;2)C-C-C-T;3)C-C-T-T ;4)C-T-T-T。其中C代表Convolution,T代表Transformer。
用这几个结构分别在ImageNet1K和JFT数据集上做了实验,训练的loss和准确率如下:
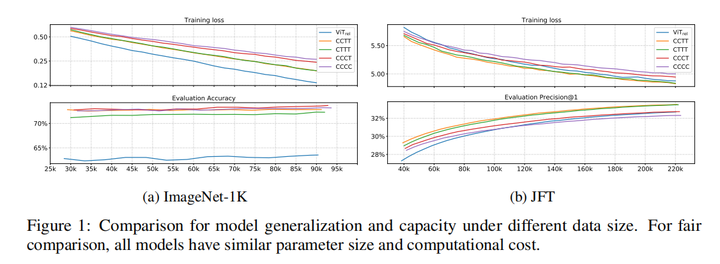
根据上面的结果,作者得出来以下的结论:
不同结构的泛化能力排序如下:
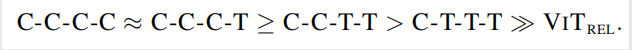
不同结构的学习能力排序如下:
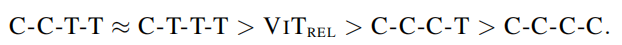
然后,作者为了探究C-C-T-T 和 C-T-T-T,哪一个比较好。作者在JFT上预训练后,在ImageNet-1K上再训练了30个epoch。结果如下:

可以看出C-C-T-T的效果比较好,因此作者选用了C-C-T-T作为CoAtNet的结构。
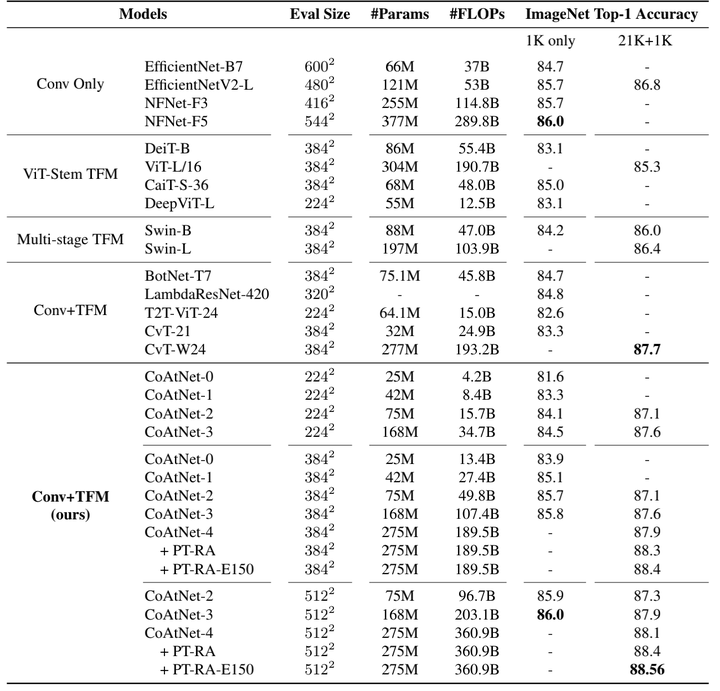
从上图中可以看出,CNN+SA的结构确实比单纯的CNN或者SA的结构性能要好。
【总结】
CNN和SA其实还是有一些相似,又有一些不同的。既然各有优缺点,将他们进行结合确实是不个不错的选择。但是,个人觉得,目前的方法将CNN和SA做结合都比较粗暴,所以会导致sub-optimal的问题。
个人觉得,如果能够将SA融入到CNN中,形成一种内容自适应的卷积;或者将CNN到SA中,形成一种具有平移不变性的SA,这样的结构,或许会比当前这样直接并列或者串联有意思的多。
除此之外,出了简单粗暴的将CNN和SA融合的到一起,最近还有一系列文章提出了局部的注意力(e.g., VOLO[1], Focal Self-Attention[2])来提高模型的能力。
【参考文献】
[1]. Yuan, Li, et al. "VOLO: Vision Outlooker for Visual Recognition." arXiv preprint arXiv:2106.13112 (2021).
[2]. Yang, J., Li, C., Zhang, P., Dai, X., Xiao, B., Yuan, L., & Gao, J. (2021). Focal Self-attention for Local-Global Interactions in Vision Transformers. arXiv preprint arXiv:2107.00641.
关于文章有任何问题,欢迎在评论区留言或者添加作者微信: xmu_xiaoma