
面试官:“简述Xception中的深度可分离卷积”

极市导读
本文详细介绍了Xception网络的相关结构及特点。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
Xception 网络
在 2017 年谷歌也是在 Inception- 的基础上推出 Xception,在性能上超越了原有的 Inception-V3。下面我们带大家见识一下 Xception 的庐山真面目吧!
简介
在 ception 中作者主要提出了以下一些亮点:
作者从 Inception- 的假设出发,解塊通道相关性和空间相关性,进行简化网络,推导出深度可分离卷积。 提出了一个新的 Xception 网络。
相信小伙伴们看到这里一定会发出惊呼,纳尼,深度可分离卷积不是在 中提出的么? 在这里需要注意的是,在 ception 中提出的深度可分离卷积和 MobileNet 中是有差异的, 具体我们会在下文中聊到閣。
Xception的进化之路
在前面我们说过 Xception 是 Google 继 Inception 后提出的对 Inception- 的另一种改进,作 者认为跨通道相关性和空间相关性应充分解塊(独立互不相关),因此最好不要将它们共同映射处理,应分而治之。具体是怎么做呢?
1、先使用 的卷积核,将特征图各个通道映射到一个新空间,学习通道间相关性。
2、再使用 或 卷积核,同时学习空间相关性和通道间相关性。
进化1
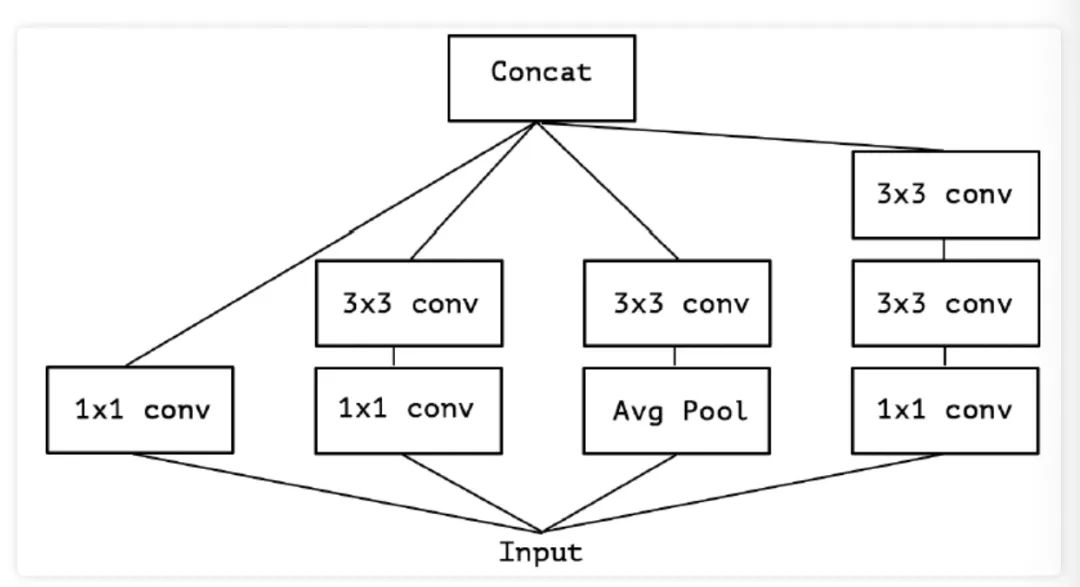
在Inception- 中使用了如下图 所示的多个这样的模块堆叠而成,能够用较小的参数学习到更丰富的信息。
进化2
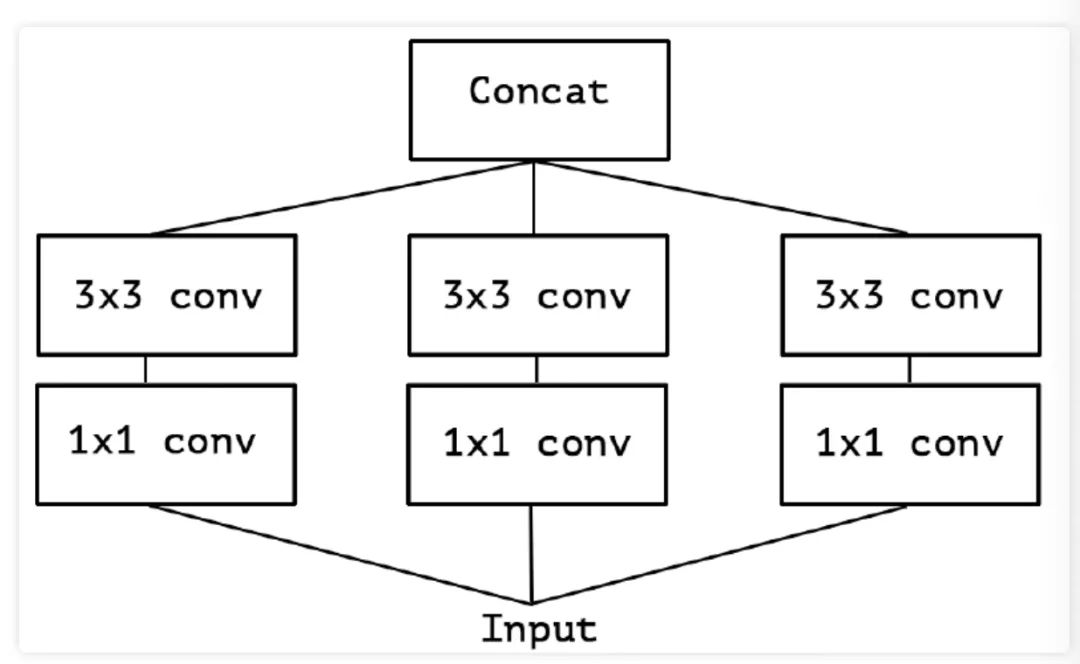
在原论文中作者对于图 1 中的模块进行了简化, 去除 Inception-v3 中的 Pool 后, 输入的下一步操作就都是 卷积,如下图 2 所示:
进化3
更进一步,作者对于简化后的 Inception- 模块中的所有 卷积进行合并,什么意思呢?就是将 Inception- 模块重新构造为 卷积,再进行空间卷积 是标准的那种多通道的卷 积),相当于把 卷积后的输出拼接起来为一个整体,然后进行分组卷积。如下图 3 所示:
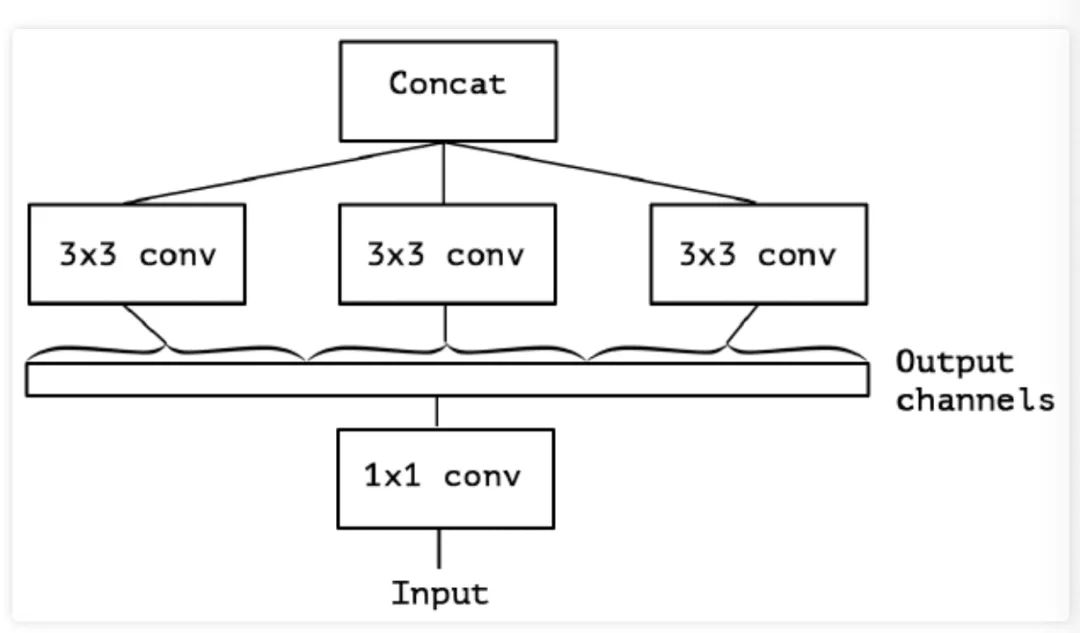
经过进化3这种操作后,自然会有以下问题:分组数及大小会产生什么影响?是否有更一般的假设?空间关系映射和通道关系映射是否能够完全解耦呢?
进化4
基于进化 3 中提出的问题, 作者提出了"extreme"版本的 Inception 模块,如下图 4 所示。从图4 中我们可以看出,所谓的" 版本其实就是首先使用 卷积来映射跨通道相关性,然后分别映射每个输出通道的空间相关性,即对每个通道分别做 卷积。
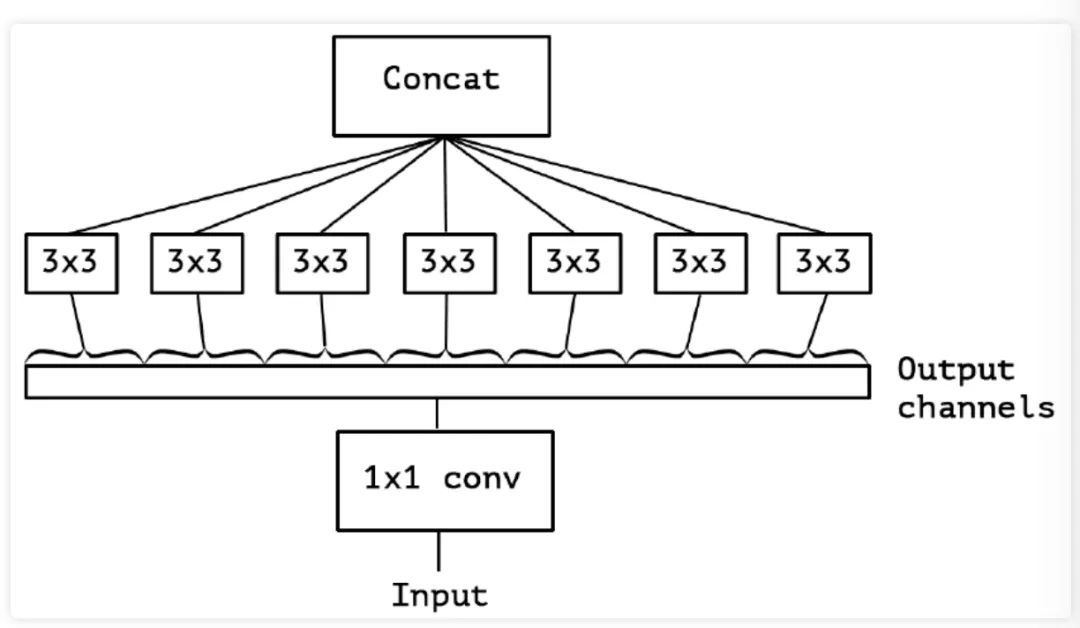
在此作者也说明了这种 Inception 模块的"extreme"版本几乎与深度可分离卷积相同,但是依然是存在以下区别的:
1、通常实现的深度可分离卷积(如 MobileNet 中) 首先执行通道空间卷积 卷积),然后执行 卷积,而 ception 首先执行 卷积。
2、第一次操作后是否加 , Inception 中 2 个操作后都加入 。其中"extreme"版本的Inception 模块为:
而普通的深度可分离卷积结构为:
而作者认为第一个区别不大,因为这些操作都是堆叠在一起的; 但第二个影响很大,他发现在"extreme"版本的 Inception 中 与 之间不用 收敘更快、准确率更高,这个作者是做了实验得到的结论,后面我们会介绍。
Xception网络结构
在提出了上面新的模块结构后,认识卷积神经网络的特征图中跨通道相关性和空间相关性的映射是可以完全解塊的。因为结构是由 Inception 体系结构得到的"extreme"版本,所以将这种新的模块结构命名为 Xception, 表示"Extreme Inception"。并且作者还结合了 ResNet 的残差思想,给出了如下图 5 所示的基于 Xception 的网络结构:
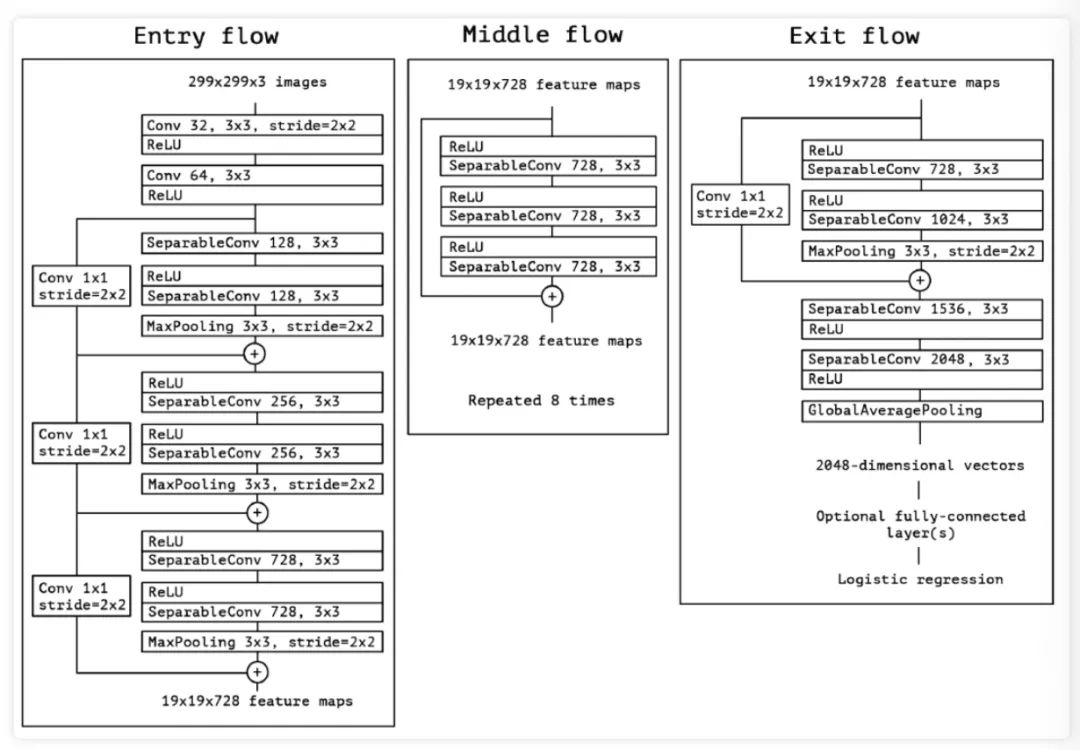
实验评估
在训练验证阶段,作者使用了 ImageNet 和 这两个数据集做验证。精度和参数量对比如下图所示,从图中可以看到,在精度上 Xception 在 ImageNet领先较小,但在 上领先很多; 在参数量和推理速度上,Xception 参数量少于 Inception, 但速度更快。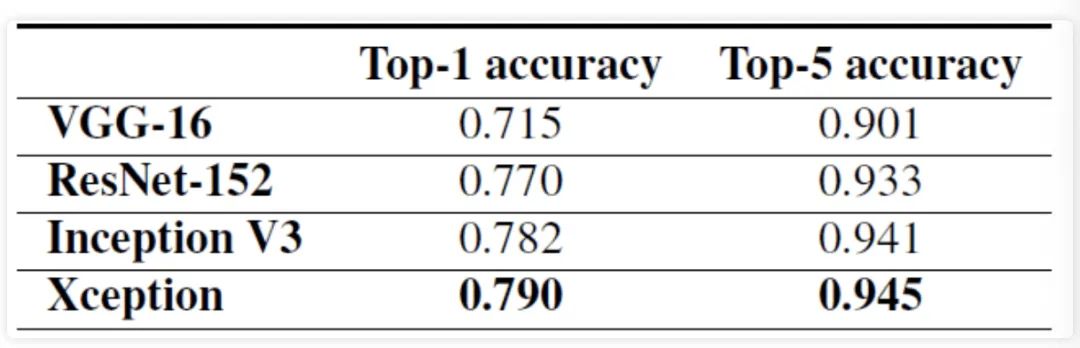 图6 ImageNet数据集上精度对比
图6 ImageNet数据集上精度对比
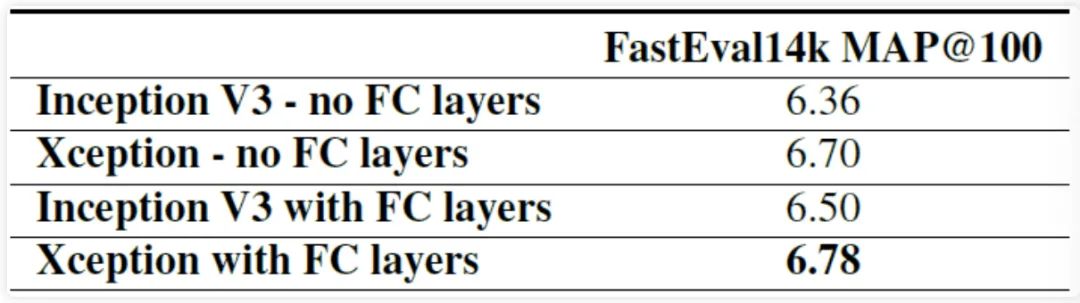
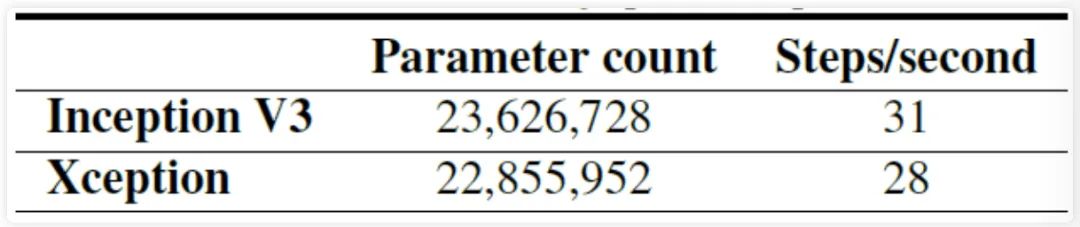
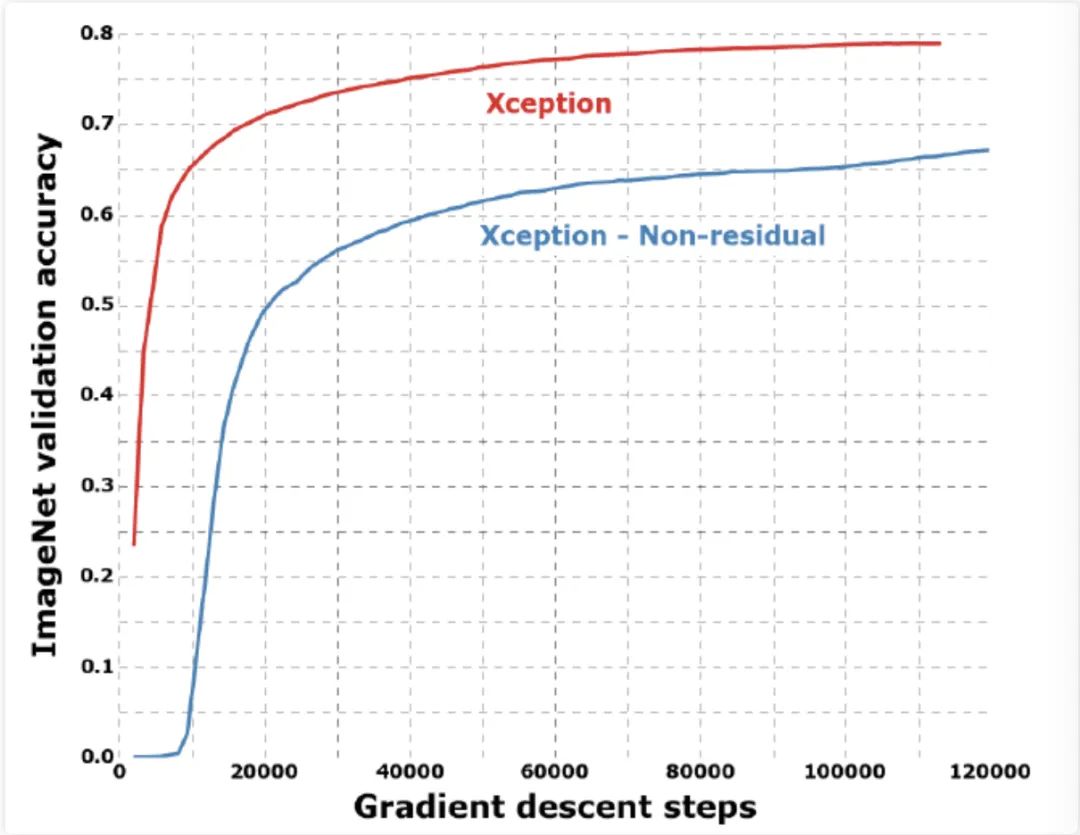
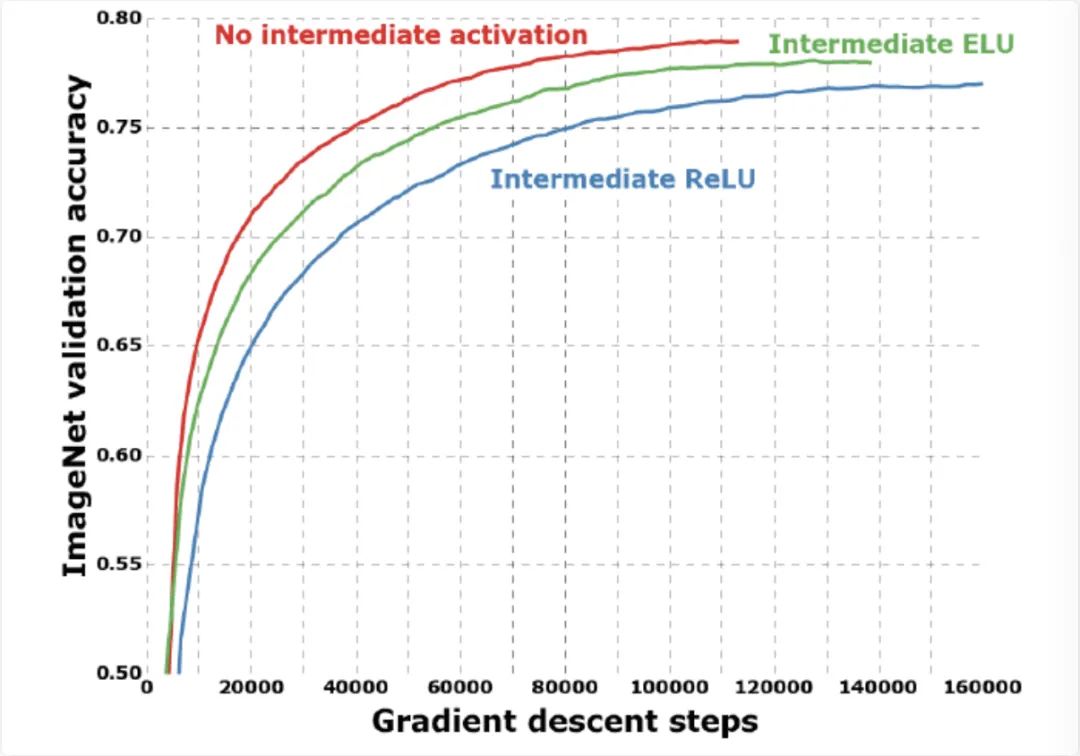
如下图所示,除此之外,作者还比较了是否使用 Residual 残差结构、是否在 Xception 模块中两个操作 卷积和 卷积)之间加入 下的训练收玫速度和精度。从图中可以看出,在使 用了 Residual 残差结构和去掉 Xception 模块中两个操作之间的 激活函数下训练收玫的速度更快,精度更高。
总结
在 Xception 网络中作者解塊通道相关性和空间相关性,提出了"extreme"版本的 Inception 模块,结合 的残差思想设计了新的 ception 网络结构,相比于之前的 Inception-V3 获得更高的精度和使用了更少的参数量。
这里给出 Keras 代码实现:
from keras.models import Modelfrom keras import layersfrom keras.layers import Dense, Input, BatchNormalization, Activationfrom keras.layers import Conv2D, SeparableConv2D, MaxPooling2D, GlobalAveragePooling2D, GlobalMaxPooling2Dfrom keras.applications.imagenet_utils import _obtain_input_shapefrom keras.utils.data_utils import get_fileWEIGHTS_PATH = 'https://github.com/fchollet/deep-learning-models/releases/download/v0.4/xception_weights_tf_dim_ordering_tf_kernels.h5'def Xception():# Determine proper input shapeinput_shape = _obtain_input_shape(None, default_size=299, min_size=71, data_format='channels_last', include_top=False)img_input = Input(shape=input_shape)# Block 1x = Conv2D(32, (3, 3), strides=(2, 2), use_bias=False)(img_input)x = BatchNormalization()(x)x = Activation('relu')(x)x = Conv2D(64, (3, 3), use_bias=False)(x)x = BatchNormalization()(x)x = Activation('relu')(x)residual = Conv2D(128, (1, 1), strides=(2, 2), padding='same', use_bias=False)(x)residual = BatchNormalization()(residual)# Block 2x = SeparableConv2D(128, (3, 3), padding='same', use_bias=False)(x)x = BatchNormalization()(x)x = Activation('relu')(x)x = SeparableConv2D(128, (3, 3), padding='same', use_bias=False)(x)x = BatchNormalization()(x)# Block 2 Poolx = MaxPooling2D((3, 3), strides=(2, 2), padding='same')(x)x = layers.add([x, residual])residual = Conv2D(256, (1, 1), strides=(2, 2), padding='same', use_bias=False)(x)residual = BatchNormalization()(residual)# Block 3x = Activation('relu')(x)x = SeparableConv2D(256, (3, 3), padding='same', use_bias=False)(x)x = BatchNormalization()(x)x = Activation('relu')(x)x = SeparableConv2D(256, (3, 3), padding='same', use_bias=False)(x)x = BatchNormalization()(x)# Block 3 Poolx = MaxPooling2D((3, 3), strides=(2, 2), padding='same')(x)x = layers.add([x, residual])residual = Conv2D(728, (1, 1), strides=(2, 2), padding='same', use_bias=False)(x)residual = BatchNormalization()(residual)# Block 4x = Activation('relu')(x)x = SeparableConv2D(728, (3, 3), padding='same', use_bias=False)(x)x = BatchNormalization()(x)x = Activation('relu')(x)x = SeparableConv2D(728, (3, 3), padding='same', use_bias=False)(x)x = BatchNormalization()(x)x = MaxPooling2D((3, 3), strides=(2, 2), padding='same')(x)x = layers.add([x, residual])# Block 5 - 12for i in range(8):residual = xx = Activation('relu')(x)x = SeparableConv2D(728, (3, 3), padding='same', use_bias=False)(x)x = BatchNormalization()(x)x = Activation('relu')(x)x = SeparableConv2D(728, (3, 3), padding='same', use_bias=False)(x)x = BatchNormalization()(x)x = Activation('relu')(x)x = SeparableConv2D(728, (3, 3), padding='same', use_bias=False)(x)x = BatchNormalization()(x)x = layers.add([x, residual])residual = Conv2D(1024, (1, 1), strides=(2, 2), padding='same', use_bias=False)(x)residual = BatchNormalization()(residual)# Block 13x = Activation('relu')(x)x = SeparableConv2D(728, (3, 3), padding='same', use_bias=False)(x)x = BatchNormalization()(x)x = Activation('relu')(x)x = SeparableConv2D(1024, (3, 3), padding='same', use_bias=False)(x)x = BatchNormalization()(x)# Block 13 Poolx = MaxPooling2D((3, 3), strides=(2, 2), padding='same')(x)x = layers.add([x, residual])# Block 14x = SeparableConv2D(1536, (3, 3), padding='same', use_bias=False)(x)x = BatchNormalization()(x)x = Activation('relu')(x)# Block 14 part 2x = SeparableConv2D(2048, (3, 3), padding='same', use_bias=False)(x)x = BatchNormalization()(x)x = Activation('relu')(x)# Fully Connected Layerx = GlobalAveragePooling2D()(x)x = Dense(1000, activation='softmax')(x)inputs = img_input# Create modelmodel = Model(inputs, x, name='xception')# Download and cache the Xception weights fileweights_path = get_file('xception_weights.h5', WEIGHTS_PATH, cache_subdir='models')# load weightsmodel.load_weights(weights_path)return model
引用
https://arxiv.org/abs/1610.02357 https://zhuanlan.zhihu.com/p/127042277 https://blog.csdn.net/u014380165/article/details/75142710 https://blog.csdn.net/lk3030/article/details/84847879 https://blog.csdn.net/qq_38807688/article/details/84590459
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“目标检测竞赛”获取目标检测竞赛经验资源~

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
