
从NIPS'22的3篇文章看Vision Transformer最新研究进展
资料获取:添加小编 nvshenj125, 备注CVPR2022, 获取 CVPR2022 全部论文
NIPS 2022不乏Vision Transformer相关的文章,今天从其中选择3篇典型的文章分享给大家。这三篇文章是对Vision Transformer三个不同方向的改进:模型结构的改进、数据层面的改进、训练方式上的改进。通过这三篇文章、三个方面的文章,了解目前Vision Transformer的业内最新进展。
模型结构上的改进重点介绍Inception Transformer(NIPS 2022)这篇文章。ViT等视觉Transformer模型采取的主体结构是attention,对全图像的token进行全局attention,因此具有比较强的全局信息提取能力。然而,对于高频信号的局部信息的提取(如轮廓的边缘等),ViT的能力是比较弱的。虽然全局信息对于图像分类等任务非常重要,局部信息也是不可缺少的部分,并且可以完善全局信息的提取。针对现有ViT的问题,这篇文章改进了ViT的结构,提出Inception Transformer。
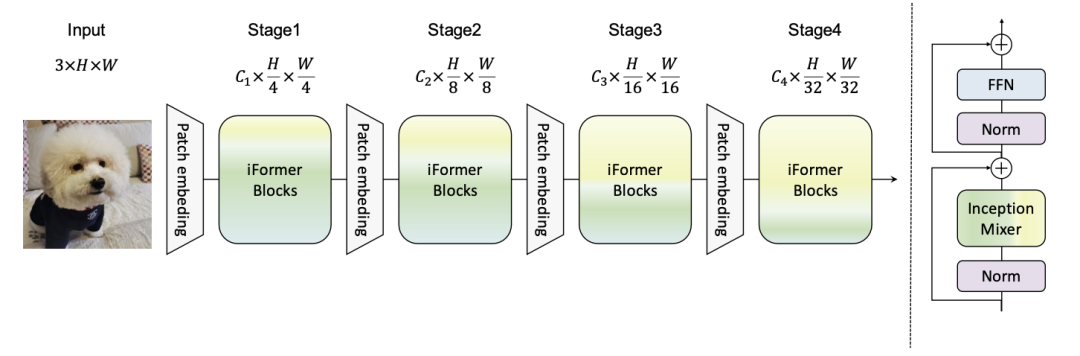
Inception Transformer的核心是两个部分,一个是inception mixer,另一个是frequency ramp structure。Inception mixer主要实现的是将每层的输入在channel维度拆解成两大部分,一部分用来提取局部信息,另一部分用来提取全局信息。局部信息部分将输入进一步切分,一部分输入maxpooling+linear模块,另一部分输入linear+depth-wise卷积模块。全局信息部门仍然采用一般的attention模块提取。最后再将局部信息和全局信息进行融合。
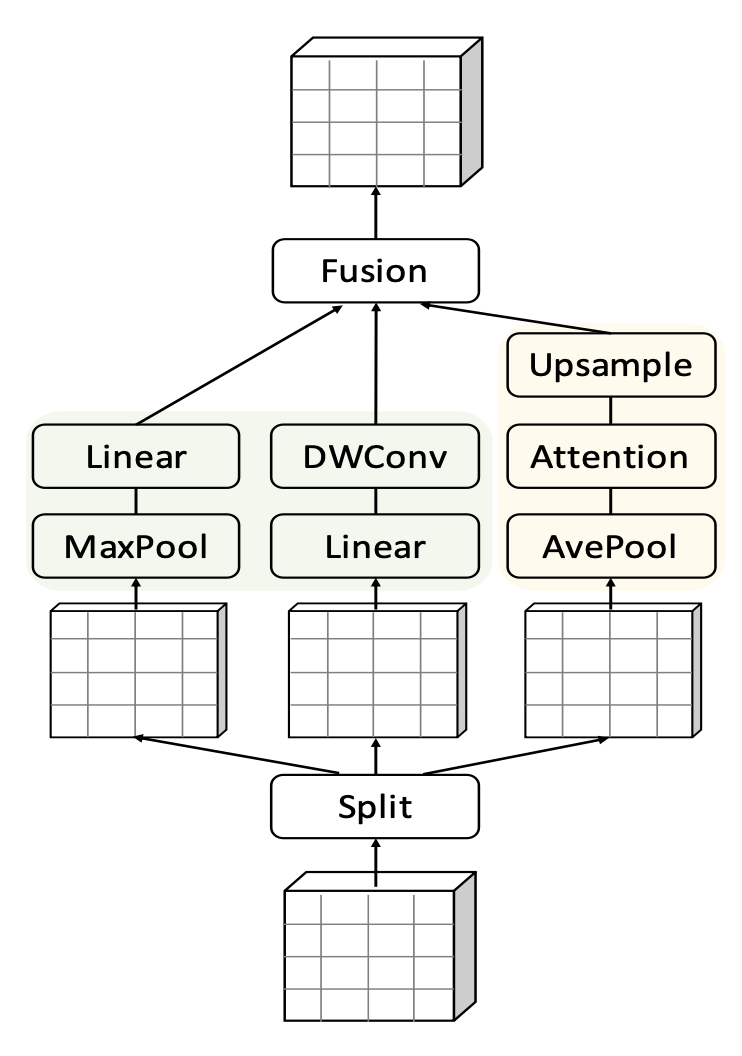
第二个核心是文中提出的全局和局部channel的动态比例。在视觉模型中,一般模型都倾向于在浅层学习局部信息,在深层学习全局信息。基于这个考虑,文中在决定每一层使用多少个channel提取局部信息、多少个channel提取全局信息时,采用了根据模型层数动态设定的方法。随着网络层数的加深,用于全局信息提取的channel逐渐增加,用于局部信息提取的channel逐渐减少。
在数据层面的改进,主要介绍这篇:Understanding and Improving Robustness of Vision Transformers through Patch-based Negative Augmentation(NIPS 2022),通过数据增强提升Vision Transformer模型的鲁棒性。这篇文章提出,ViT等使用多头注意力机制进行图像信息提取的Vision Transformer模型,在训练过程中学习到的特征是非常不鲁邦的。比如下面的例子中,最左侧一列是原始的正常图像,其他列是对原始图像的patch进行随机打乱、旋转等处理。经过这些处理后,图像已经变得让人也无法识别了,但是神奇的是ViT模型的分类置信度仍然很高!这种奇怪的现象表明,ViT等利用Transformer模块构造的图像分类模型,学到的用于分类的特征并不是人类识别图像所使用的特征。换句话说,ViT进行图像分类所依据的特征和人类不一样!

文中进一步分析了这个现象,发现ViT模型提取的这些特征确实是很有用的,但是鲁棒性很差。在分布相同的图像分类任务中,ViT可以取得比较好的效果,但是在其他图像分类数据集上效果很差。这表明ViT学习到的这种特征一方面对于模型的拟合很有帮助,另一方面其鲁棒性并不强。本文解决的问题在于,能不能让ViT别提取这种鲁棒性差的特征,同时又不损害ViT的拟合能力。
基于以上考虑,本文设计了数据负向增强方法。在图像领域,数据增强一般都是保持图像的含义相同,对图像进行翻转、旋转、裁剪等处理扩充正样本。而本文提出了负向的数据增强,通过对一个图像中patch的随机扰动,生成和原始图像语义差别非常大的负增强图像(例如上图中右侧的那些扰动图像),让模型不要把这种扰动后的图像正确分类,以此缓解模型学习鲁棒性差的特征。
文中具体提出了3种类型的负向数据增强方法,都是对图像中的patch进行扰动:
Patch-based Shuffle——对图像的patch进行随机打乱;
Patch-based Rotate——对图像的patch进行{0 ◦ , 90◦ , 180◦ , 270◦}的随机旋转;
Patch-based Infill——以一定概率将图像中心区域的patch随机替换成边缘区域的patch。
通过上述3种类型的数据增强,可以得到一些人类无法识别的图像,将其作为负样本输入到模型中,需要单独引入一个负向的loss,公式如下:
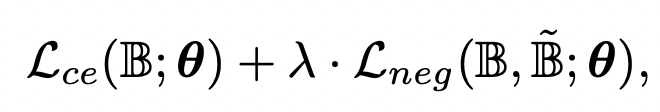
第一个loss是正常样本的交叉熵损失,第二个loss是针对负向增强样本的loss。对于负向增强样本loss的设计,文中提出了3个可行的实现方法。
第一种方法在Label space中实现,因为负增强样本人类识别不出来,那就让这些样本的真实label是均匀分布的,公式可以表示为:
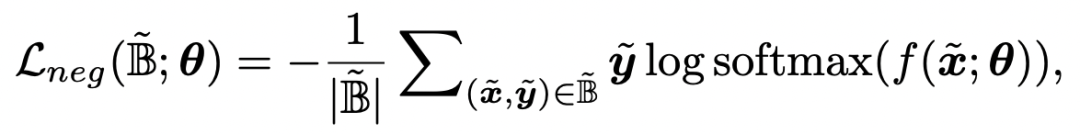
第二种方法在Logit space中实现,负增强的样本应该不能和原始样本预测为同一个类别,因此使用了一个L2正则约束原始样本和增强后样本的logits距离不能太近:

第三种方法在Representation space中实现,这种方法基于对比学习对的思路,对于一个样本,在同batch中找到其他和他属于同一类别的样本作为正样本,不属于同一类别的,以及根据该样本负向数据增强的样本作为负样本,使用对比学习的方法求loss,让正样本之间离得近,负样本之间离得远:
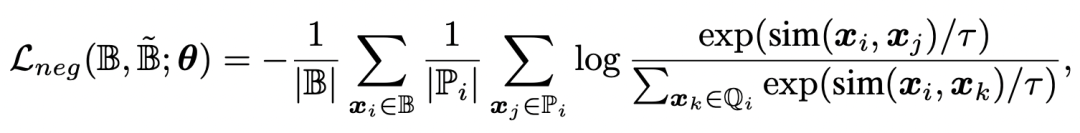
训练方式的改进上,主要介绍Parameter-efficient Fine-tuning for Vision Transformers(NIPS 2022)。这篇文章主要围绕的是如何提升Vision Transformer的finetune效率。文中的核心是基于Intrinsic Dimension的概念,得到模型的子空间,然后在这个参数量更少的子空间上进行finetune。
首先先介绍一下什么是Intrinsic Dimension。Intrinsic Dimension指的是为了达到某个效果目标,模型需要的最小参数维度。这个概念是在INTRINSIC DIMENSIONALITY EXPLAINS THE EFFECTIVENESS OF LANGUAGE MODEL FINE-TUNING(ACL 2021)这篇论文中提出的。这篇文章希望研究的是,NLP中预训练的参数量巨大的语言模型,为什么可以在几百几千样本来那个上finetune后,能够得到比较好的效果。核心结论是,大模型在小数据上finetune有效的原因是,模型在一个参数维度小得多的子空间finetune能够达到全量模型参数finetune相同的效果。文中采用的方法是,用下面的公式进行重参数化:
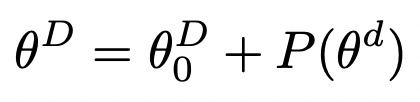
其中D代表原始模型的参数维度,d代表比D小的多的一个子空间,P是一个将d维参数映射到D维的函数,文中使用了一个随机矩阵进行映射。等号右侧第一项代表大模型的初始化参数。通过不断调整d,对比不同维度的子空间下模型能够达到的最优效果,确定模型的Intrinsic Dimension,确定多大的子空间finetune能够达到和全量参数finetune相近的效果。
文中的主要实验结果如下表,大模型使用比较少的参数量就能达到原始模型90%的效果。这表明对于大模型的参数,只在一个参数量更小的子空间优化,能够达到和全量参数finetune相近的效果。这也为Vision Transformer中的高效finetune一提供了一种解决思路。
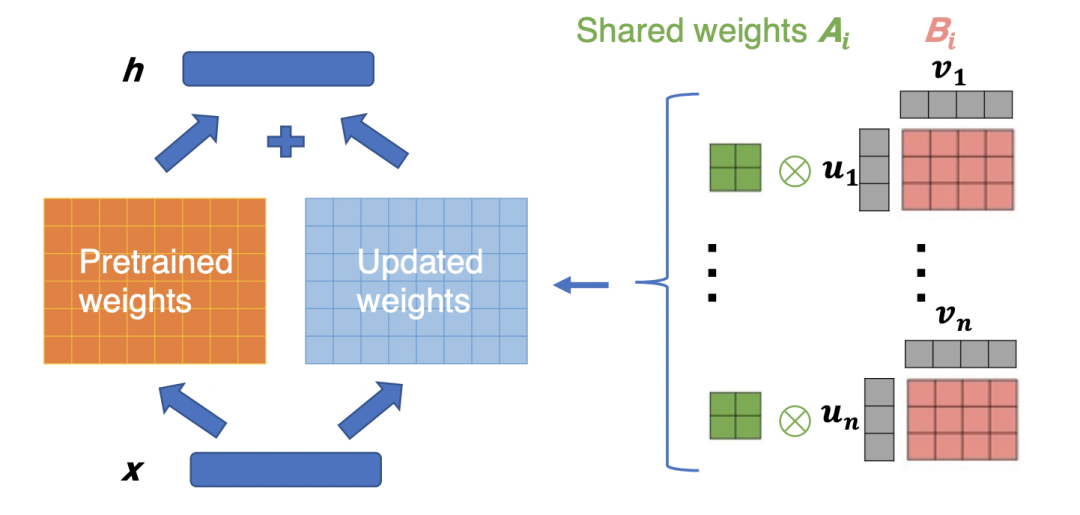
NIPS 2022的这篇ViT高效finetune的文章,就基于Intrinsic Dimension方法。首先通过上面的方法确定Intrinsic Dimension,进而得到模型的子空间,然后在子空间这个更少的参数量上进行finetune。对于子空间上的学习,文中采用了Kronecker Adaptation方法,将待更新的子空间矩阵拆解成多个子矩阵,进一步降低参数计算量。
本文总结了3篇NIPS 2022中Vision Transformer的工作,主要涉及模型结构的改进、数据层面的改进、训练方式上的改进三个方向。目前业内对于Vision Transformer的研究仍然比较火,基于ViT等方法的基础上,通过更深入问题本质的分析加上改进,不断提升Vision Transformer的效果和性能。


交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2022 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
