
广告行业中那些趣事系列7:实战腾讯开源的文本分类项目NeuralClassifier

摘要:本篇主要分享腾讯开源的文本分类项目NeuralClassifier。虽然实际项目中使用BERT进行文本分类,但是在不同的场景下我们可能还需要使用其他的文本分类算法,比如TextCNN、RCNN等等。通过NeuralClassifier开源项目我们可以方便快捷的使用这些模型。本篇并不会重点剖析某个算法,而是从整体的角度使用NeuralClassifier开源工程,更多的是以算法库的方式根据不同的业务场景为我们灵活的提供文本分类算法。
目录
01 不仅仅是BERT
02 腾讯开源文本分类项目NeuralClassifier
03 第一步先跑通它
04 改造成我们的基于中文的多分类任务
总结
01 不仅仅是BERT
之前说过BERT是NLP领域中具有里程碑意义的成果,具有效果好和应用范围广的优点。虽然实际项目中我们主要使用BERT来做文本分类任务,但是在不同的场景下我们可能还需要使用其他的文本分类算法。除此之外,我们不能仅仅只会用BERT,还需要掌握一些BERT出现之前的文本分类算法,能更好的帮助我们了解文本分类任务背景下模型的发展历史。
BERT之前主要用于文本分类的模型有TextCNN、RCNN、FastText等,这些模型也拥有各自的优点。充分了解这些模型各自的优缺点,才能在不同的场景下更好的使用这些模型。
之前看到腾讯开源了一个文本分类开源项目NeuralClassifier,里面集成了很多算法,其中就包括上面说的TextCNN、RCNN、FastText等。所以想基于该开源项目进行二次开发以便后续用于实际项目中。
02 腾讯开源文本分类项目NeuralClassifier
本篇的重点是讲解NeuralClassifier开源项目, 项目的github地址如下:
https://github.com/Tencent/NeuralNLP-NeuralClassifier
1. 项目整体架构
项目整体架构如下图所示:
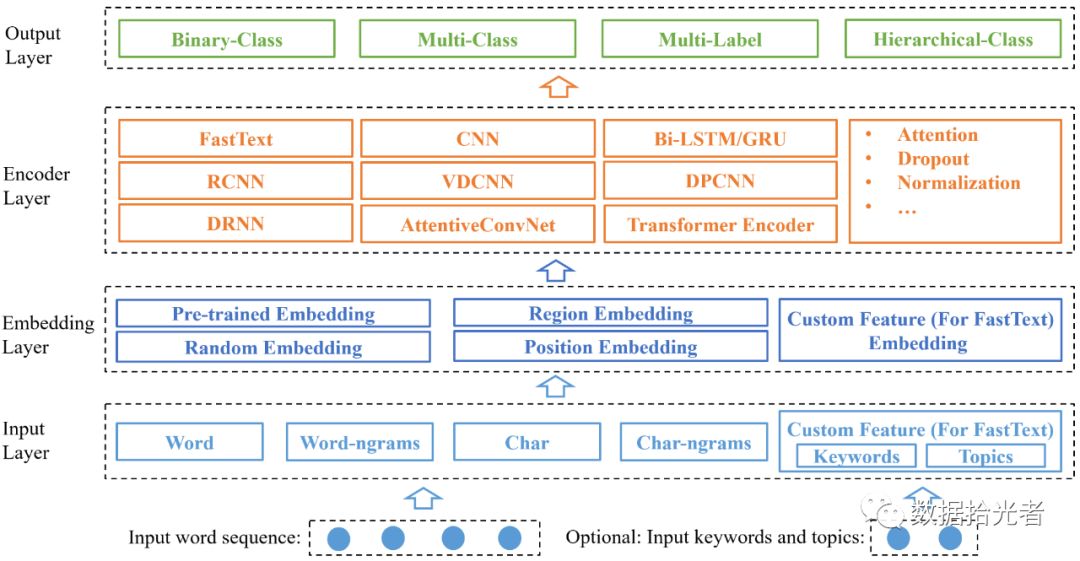
图1 项目整体架构图
从下往上依次查看,最下面是输入的语句,因为原始项目中主要是针对英文分类,所以输入的句子序列是一系列词,这是主要识别的文本,所以是必须要有的。可选的输入是文本是否有关键词或者主题;
然后是Input Layer,这里可能是词、词的组合、字符和字符的组合等。如果有关键词或者主题也会作为特征进入模型;
接着是Embedding Layer,这里可以使用不同的Embedding方式,包括预训练编码、随机编码、位置编码等等;
然后是Encoder Layer,这里主要使用不同的算法,比如FastText、CNN、RCNN、Transformer等等;
最后就是Output Layer,根据不同的任务类型输出不同的结果。
2. 项目支持的任务类型
项目支持的任务类型主要有:
Binary-class text classifcation:二分类任务
Multi-class text classification:多分类任务
Multi-label text classification:多标签任务
Hiearchical (multi-label) text classification (HMC):多层多标签任务
前面三个比较好理解,咱们重点讲下第四个多层多标签任务。
实际项目中我们已经不再是单纯的多分类了,而是拥有一个比较复杂的类目体系,这个类目体系一般是以树的形式展示。对应本项目就是data/rcv1.taxonomy文件。详细解读下这个文件,第一行表示存在四个一级类目,分别是CCAT、ECAT、GCAT、MCAT。第二行代表CCAT这个一级类目下拥有的二级类目。依次类推,第三行代表C15这个二级类目下还有两个三级类目,第四行代表C151这个三级类目下还有两个四级类目。下图展示类目体系文件并通过EXCEL的方式更好的展示下这个层级类目:
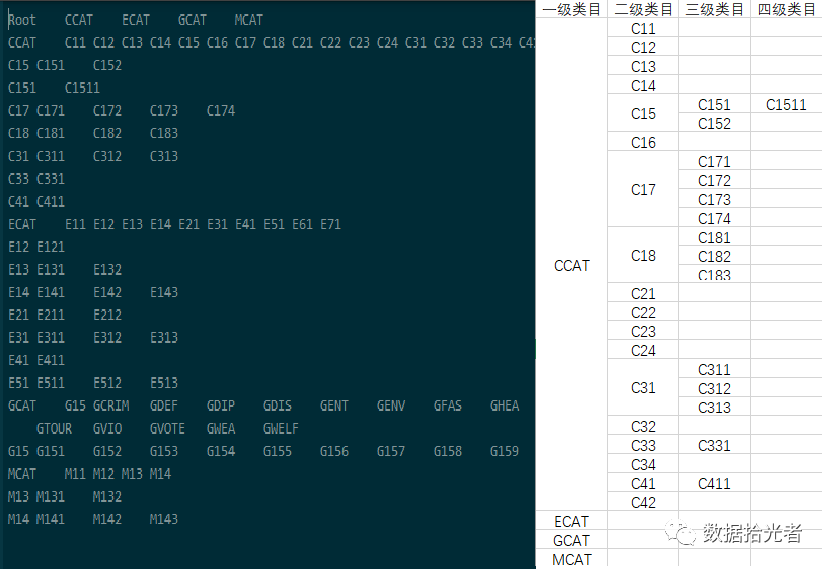
图2 类目体系文件和EXCEL展示类目体系
为了方便显示,上图EXCEL中只展示了rcv1.taxonomy文件前9行的类目结构。这样小伙伴们应该对这个类目体系有一定的了解。实际项目中一般是三到四级的类目体系,这个主要根据业务复杂程度来定。
这里咱们举一反三,如果现在需要做一个多分类任务的话,那么我们这个类目体系的配置文件只需要一行就够了:
Root label1 label2 label3…labelx
了解了类目体系,我们回过来说这个多层多标签任务。拿data目录下的训练集rcv1_train.json第一条数据对应到类目体系中,这条数据既属于CCAT一级类目,还属于C31二级类目,并且还属于C312三级类目。具体如下图所示:

图3 训练集数据抽样和类目对应展示
通俗的说,就是多层多标签任务会将这条文本数据的标签以及该标签的父级类目都加上。这点其实和我们在实际工作中的理解稍微有点不同。个人认为类目体系的层级结构一般是存在包含关系,比如C312是属于CCAT这个一级大类的,那么如果一条item打上了C312这个标签,那么应同时属于它的二级目录C31和一级目录CCAT。item打标一般是标注在最低的层级。这里的一个猜测是将标签的层级结构也添加到模型训练中可能有利于模型训练。
2. 项目支持的算法
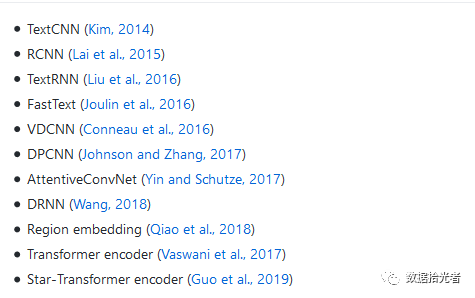
图4 项目支持的算法
3. 项目需要的开发环境
Python 3
PyTorch 0.4+
Numpy 1.14.3+
03 第一步先跑通它
复用一张前面讲ALBERT时用到的图片,以实用性为主的我一般都是先跑通项目。好处之前也说过,一方面可以增加自信心,另一方面也能快速应用到实际项目中。

通过github将项目下载到服务器下。模型训练通过以下命令:
python train.py conf/train.json
这里需要着重讲下train.json文件,这个文件是相关的任务配置信息,包括任务类型、使用算法、训练集目录、类目体系目录以及模型训练中的相关参数等。如果只是跑通样例代码,那么不用任何改动。原始配置中任务类型是多标签任务("label_type": "multi_label"),具有层级结构("hierarchical": true),使用TextCNN算法("model_name": "TextCNN"),并且在data目录下配置了训练集、验证集和测试集。这是模型训练流程最主要的几个参数,其他更多的是模型内部的参数,这里默认就好。
模型验证和预测流程通过以下命令:
python eval.py conf/train.json
python predict.py conf/train.json data/predict.json
小结下,这节咱们主要是跑通项目提供的例子,例子中是多层多标签任务,使用TextCNN算法,包括模型训练、验证和预测流程。
04 改造成我们的基于中文的多分类任务
这里咱们通过一个实际项目改造,假如我们现在需要构建一个多分类模型。项目改造的github地址如下:https://github.com/wilsonlsm006/NeuralNLP-NeuralClassifier
原始项目中是英文的文本分类任务,对应到实际项目中主要是中文的文本分类,所以数据预处理方面要做两个改造:
改造1:我们之前的模型输入数据都是读取csv文件,字段为item,label。而本项目中的数据是从json文件读取,数据格式是:

图6 数据标准输入格式
其中doc_label和doc_token分别对应上面的label和item,都是必选项。doc_keyword和doc_topic可选,分别代表关键词和主题。
改造2:原始项目中使用英文,而实际项目中使用的中文,所以涉及到中文分词的问题。这里主要使用目前比较火的jieba分词和北大开源的pkuseg分词。
上面的两个改造代码都放在data_process.py文件中,其中包括使用jieba和pkuseg分词,还包括csv文件转换成模型标准输入json文件的的代码。代码有详细的注释,应该比较通俗易懂。如果小伙伴们遇到什么问题可以随时在公众号里滴滴我。
数据预处理改造完成后需要根据实际项目修改模型配置文件。这里因为我们是多分类任务,所以我们需要设置"label_type": "single_label"。因为不需要分层,所以设置"hierarchical": false。这里还构造了一个我们自己的类目体系,因为不存在分层,所以标签都在同一层级,类目体系只有一行,设置为Root 0 1。模型使用TextCNN算法,所以"model_name":"TextCNN"。相关的训练集、验证集和测试集都存放在data2目录下,这三个文件是我们通过上面的数据处理器将csv文件加工成json数据格式。
激动人心的时候到了,只需要通过以下命令就可以进行模型训练:
python train.py conf/train2.json
小结下:本节主要通过一个多分类模型入手对原项目进行二次开发,第一步是将csv文件抽取数据加工成模型标准的输入格式json文件。因为实际项目是对中文进行文本分类,而原项目主要是对英文,所以涉及到中文的分词,主要使用目前比较火的jieba分词和北大开源的pkuseg分词。这样咱们就完成了一个实际项目的改造。
总结
本篇主要分享腾讯开源的文本分类项目NeuralClassifier。虽然实际项目中使用BERT进行文本分类,但是在不同的场景下我们可能还需要使用其他的文本分类算法,比如TextCNN、RCNN等等。通过NeuralClassifier开源项目我们可以方便快捷的使用这些模型。然后从项目架构、支持的任务类型、支持的文本分类算法等方面重点讲解开源项目NeuralClassifier。接着,根据项目说明跑通了项目实例。最后,从实际需求出发,添加数据预处理功能,将项目改造成多分类模型。本篇并不会重点剖析某个算法,而是从整体的角度使用NeuralClassifier开源工程,更多的是以算法库的方式根据不同的业务场景为我们灵活的提供文本分类算法。