
谷歌自锤Attention is all you need:纯注意力并没那么有用,Transformer组件很重要
来源:机器之心
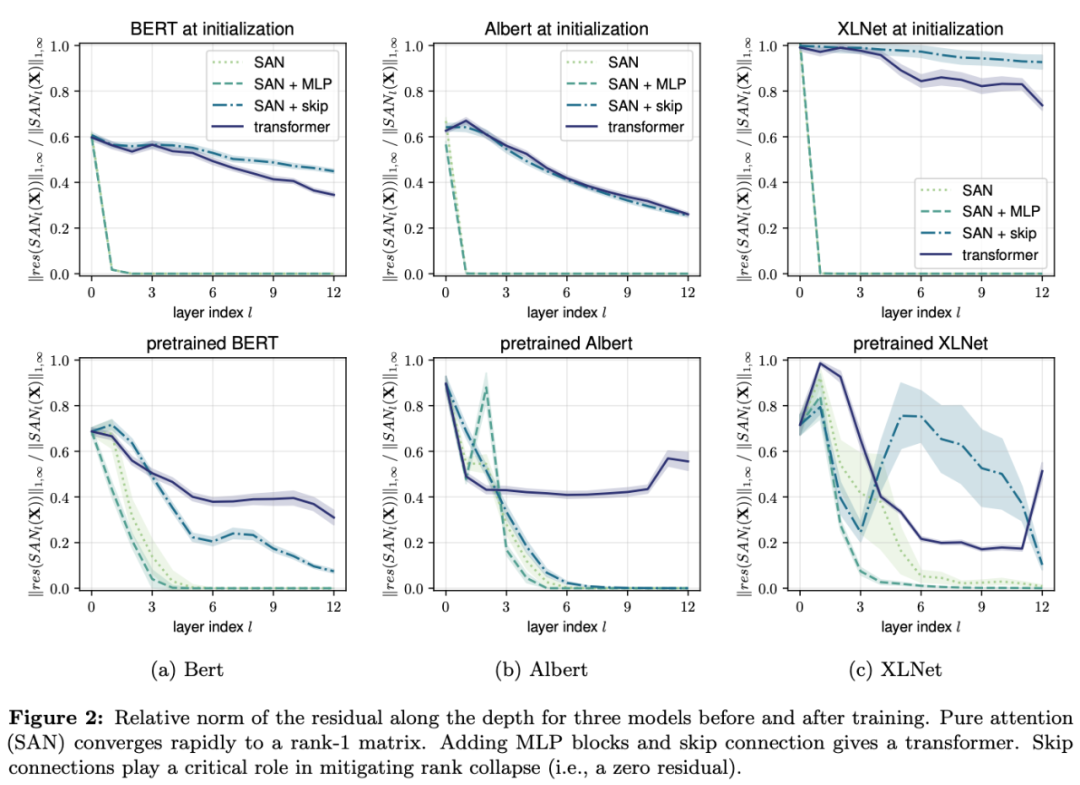
基于注意力的架构为什么那么有效?近期谷歌等一项研究认为注意力并没有那么有用,它会导致秩崩溃,而网络中的另两个组件则发挥了重要作用:「跳过连接」有效缓解秩崩溃,「多层感知器」能够降低收敛速度。此外,该研究还提出了一种理解自注意力网络的新方式——路径分解。

论文地址:https://arxiv.org/pdf/2103.03404v1.pdf
项目地址:https://github.com/twistedcubic/attention-rank-collapse
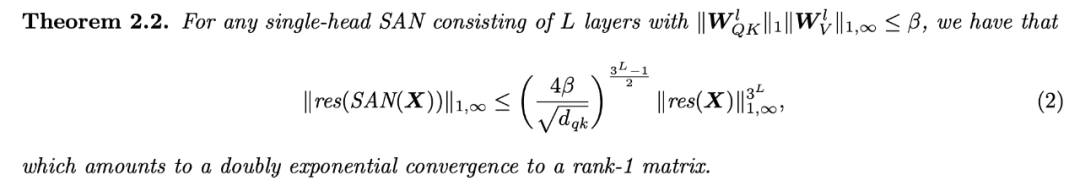
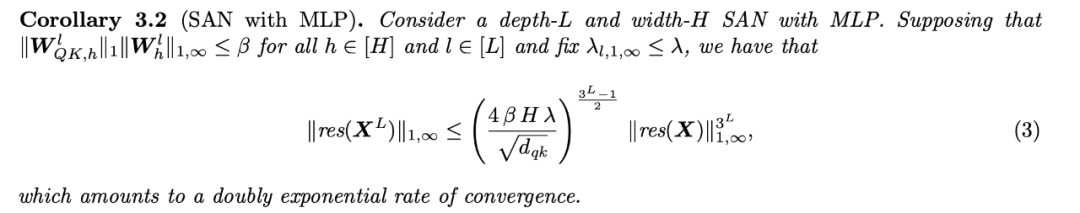


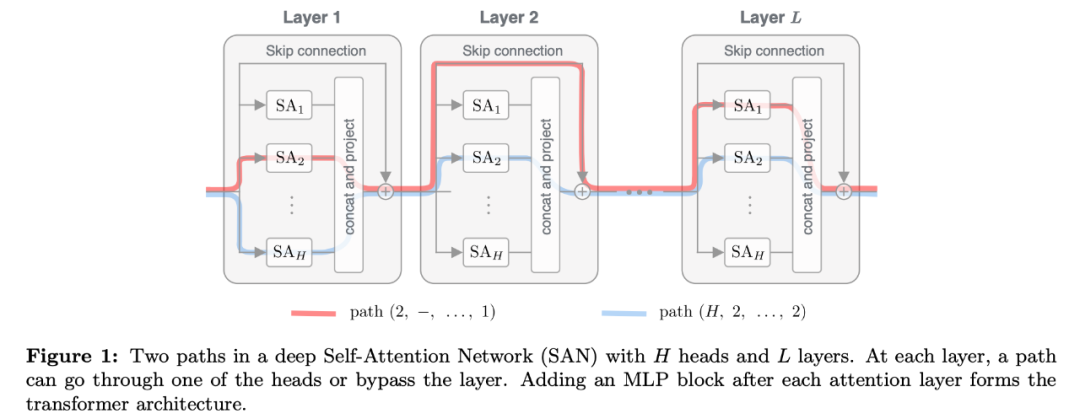
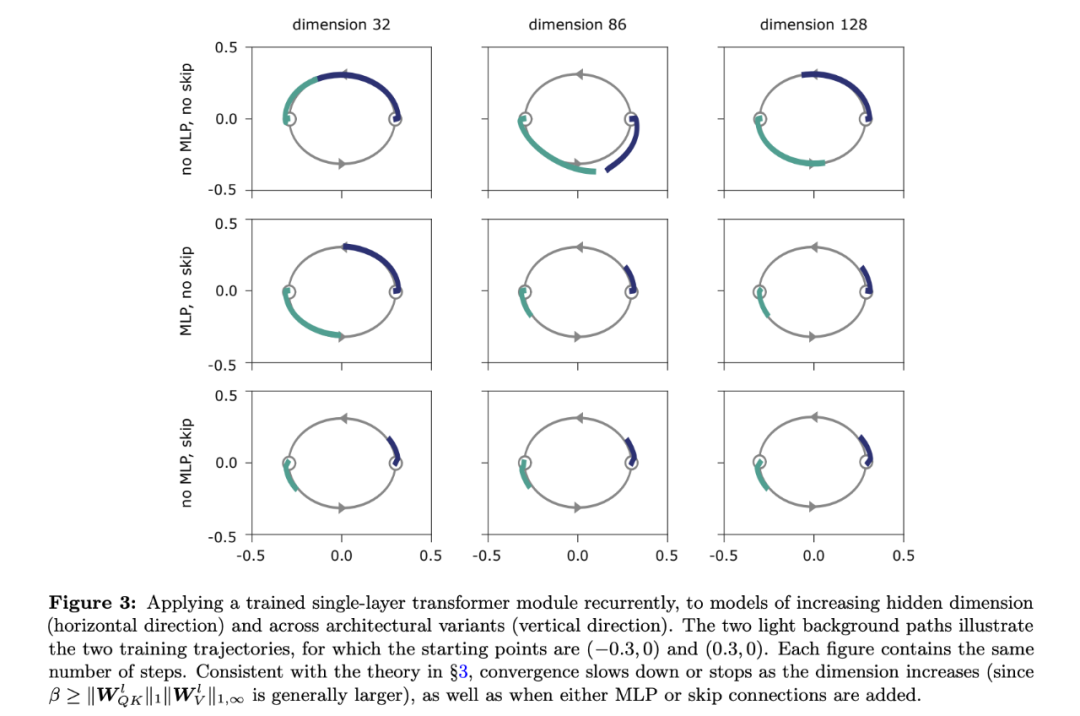
系统研究了 Transformer 的构造块,揭示自注意力与其反作用力(跳过连接和 MLP)之间的对抗影响。这揭示了跳过连接在促进优化之外的重要作用。
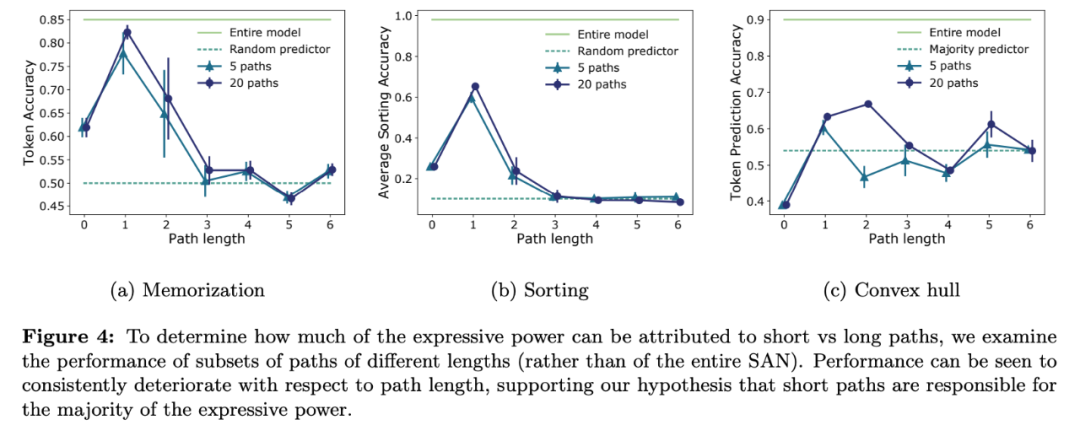
提出一种通过路径分解来分析 SAN 的新方法,发现 SAN 是多个浅层网络的集成。
在多个常见 Transformer 架构上进行实验,从而验证其理论。

评论