
CVPR2021 | 基于语义感知的自然场景视频中文本检测和跟踪
点击下面卡片关注,”AI算法与图像处理”
最新CV成果,火速送达

一、研究背景
大多数现有的视频文本检测方法采用两阶段的形式,即首先采用检测器对每帧进行检测,之后采用跟踪器对检测结果进行跟踪。这样的做法忽略了视频中的时序信息,同时视频文本检测和跟踪是分开进行的,两个任务学习到的特征无法复用。最近一些方法将检测和跟踪统一在一个框架中,然而这些方法主要基于文本行的表观特征,这使得方法容易受到光线和视角变化的影响。相较于表观特征,语义特征能够提升文本检测和跟踪的鲁棒性。如Fig. 1(a)所示,由于巨大的视角变化,跟踪器错误地匹配了大多数文本行的关系。然而,不同视角下相同文本行的字符类别和位置关系是相似的。当引入语义信息之后,如Fig. 1(b)所示,之前错误的匹配结果可以得到纠正。
尽管文本行中的字符位置和类别可以提供语义信息,然而不幸的是,真实数据集的字符级标注需要消耗大量的成本。为了在真实数据集上自动生成字符级标注,一些方法采用基于弱监督的形式。这类方法首先在合成文本数据集上对字符检测器进行预训练,之后利用预训练的模型在真实数据集上检测字符。这类方法的缺陷有两个方面:一方面,合成数据集和真实数据集之间有较大的领域差距,这使得在合成数据集上预训练的模型在真实数据集上的表现并不令人满意。另一方面,广泛使用的合成数据集主要关注英文,因此这些方法难以迁移到不具有合成数据的语种上面。

二、原理简述
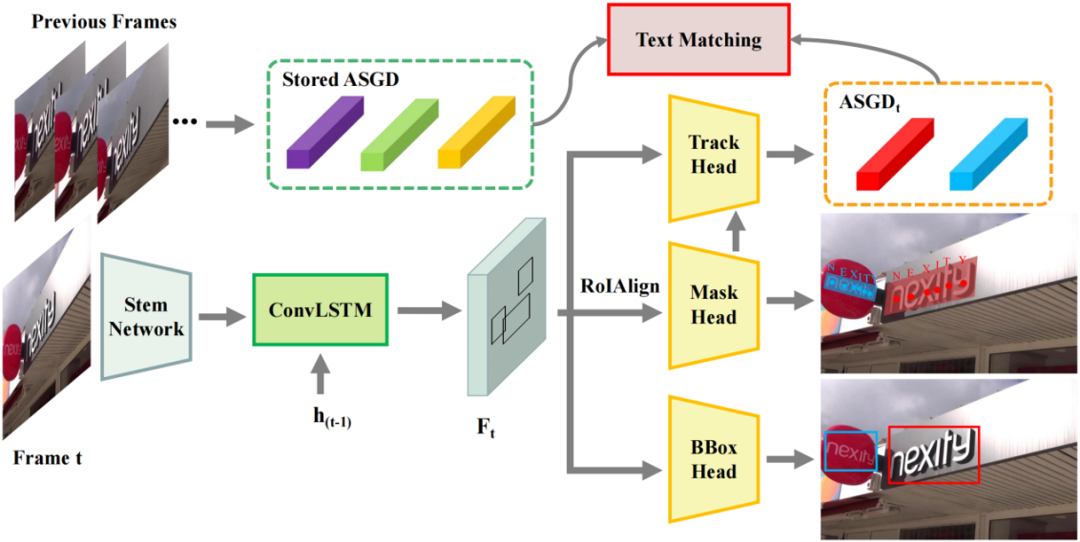 Figure 2 Overall Architecture
Figure 2 Overall Architecture
Fig. 2是作者提出的文本检测和跟踪器的整体结构。经过主干网络提取特征之后,ConvLSTM模块用于提取时间和空间信息。之后,本文在掩码分支中增加了一个字符中心点分割任务来定位和识别字符,这个分支可以提取文本行内部的语义特征。最终,文本跟踪分支生成表观中语义中几何描述子,它可以和之前帧的检测结果进行匹配。此外,基于滑动窗的文本识别器被用于为字符分割分支提供真值,该识别器可以通过弱监督的形式定位字符。
关于检测器,本文采用采用ConvLSTM模块来集成长期的时间信息。在集成时域信息之后,本文采用Mask R-CNN方法来预测轴对齐的矩形框和对应的实例分割掩码。由于Mask R-CNN方法可以通过实例分割的方式检测任意形状文本行,因此本文对四边形文本行的掩码拟合一个最小外接旋转矩形。为了提升检测性能和为接下来的跟踪分支提取语义特征,本文在Mask R-CNN的基础上增加了一个字符中心点分割分支。这个分支包含两个卷积核为3×3的卷积层和一个步长为2的上采样层。之后特征图被用于生成通道数为S的分割图,S为字符类别数加上背景类别。对于每一个字符中心,本文将距离其小于r的像素都看作正样本。联合字符中心点分割分支,文本检测任务的损失函数可被写作:
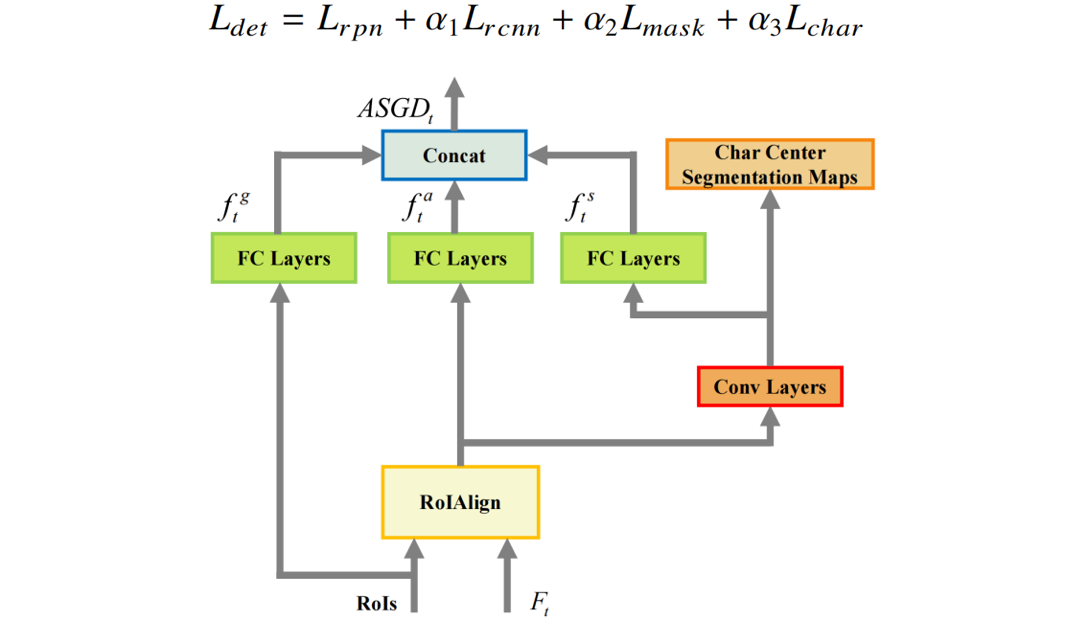
Figure 3 The Illustration Of ASGD
关于跟踪器,本文将字符的类别和位置编码为文本跟踪任务输入的一部分。为了鲁棒地表示文本行,本文提出了一种新颖的表观-语义-几何描述子(ASGD)。如Fig. 3所示,它由三部分组成。其中,语义特征通过字符中心点分割分支的第二个卷积层的输出特征映射得到。几何特征通过RoI的坐标映射得到。为了训练文本跟踪分支,本文使正样本间的距离尽可能的小,负样本间的距离尽可能的大。然而,由于运动造成的差异,正样本之间的距离很难接近0。因此,本文采用了一个平滑双阈值的对比损失来优化跟踪分支。为了端到端的训练文本检测和跟踪任务,整个框架的损失函数可被写作:
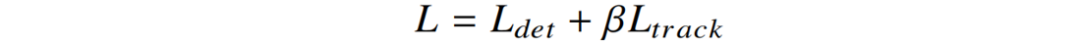
关于弱监督字符检测器,本文只需要词级别标注的真实数据。在训练集上生成字符级真值的流程如Fig. 4所示。首先,本文通过RoIRotate操作将文本行矫正成轴对齐的形式。之后,本文采用基于滑动窗的文本识别器对每个滑动窗口进行分类。当字符位于滑动窗口的中心时,文本识别器将以高置信度识别字符。当滑动窗口和字符的中心未对齐时,文本识别器将输出低置信度或者空白类别。最终,本文对滑动窗口进行非极大值抑制操作,并将选择到的窗口中心点逆变换到输入图片作为字符级别标签。

Figure 4 The Procedure Of Generating Character-level Labels
关于推理过程,本文采用在线的形式生成检测结果和匹配检测到的文本行。给定第t帧的图像,本文首先检测所有的文本行并获得对应的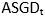 。之后,本文计算和之前存储的ASGD的相似矩阵,最后,本文使用阈值为
。之后,本文计算和之前存储的ASGD的相似矩阵,最后,本文使用阈值为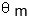 的匈牙利算法来生成匹配对。如果某个文本行找到了对应的匹配文本,本文就更新该跟踪序列和对应的ASGD。注意对于每一个跟踪序列,本文只保存最新的ASGD。对于没有匹配到的文本行,本文为它们构建新的跟踪序列,并将它们的ASGD存储。最终,本文所提出的方法可在ICDAR 2013视频文本数据集上达到9.6 fps。
的匈牙利算法来生成匹配对。如果某个文本行找到了对应的匹配文本,本文就更新该跟踪序列和对应的ASGD。注意对于每一个跟踪序列,本文只保存最新的ASGD。对于没有匹配到的文本行,本文为它们构建新的跟踪序列,并将它们的ASGD存储。最终,本文所提出的方法可在ICDAR 2013视频文本数据集上达到9.6 fps。
三、主要实验结果及可视化结果
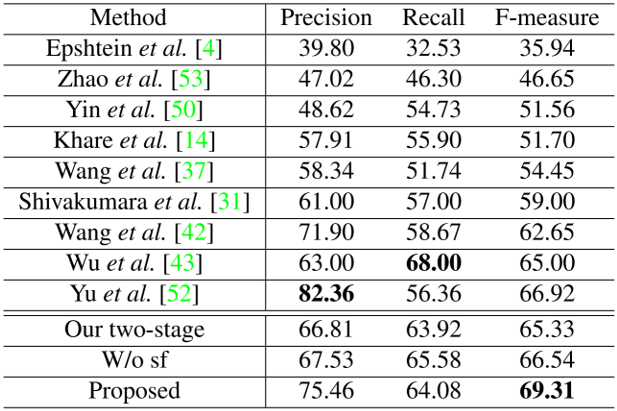
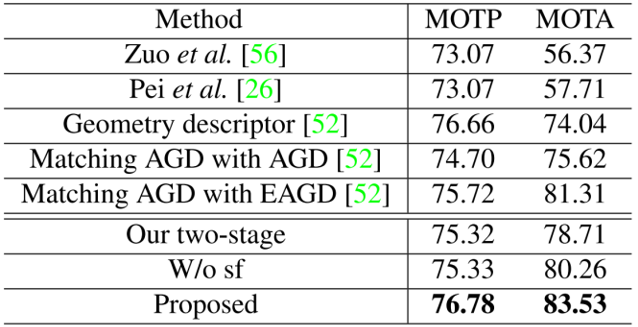
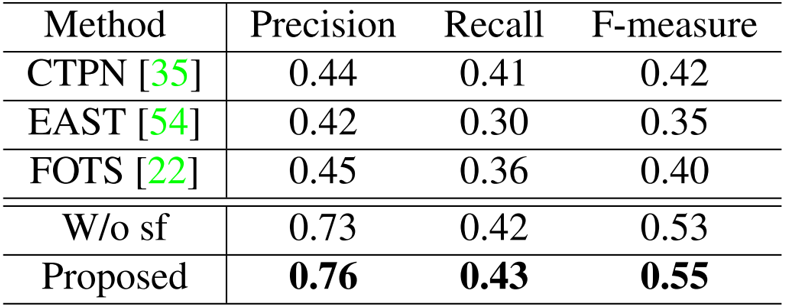
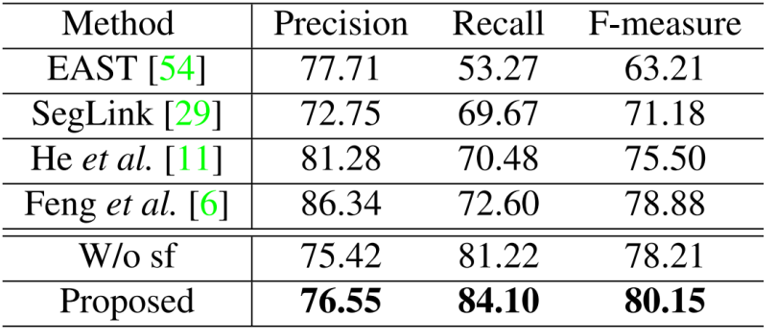
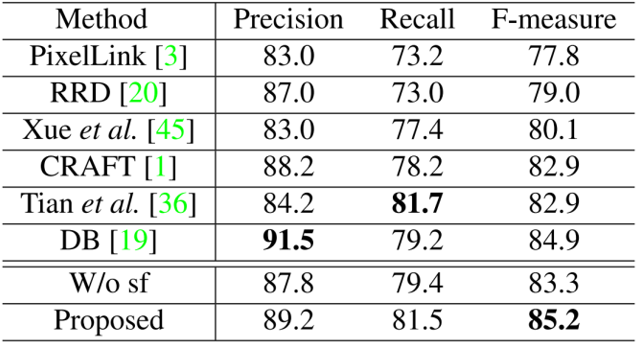

Figure 5 Examples Of Text Detection And Tracking Results
由Table 1、2和3可以看出,文中所提出的模型在视频文本数据集的检测和跟踪任务上取得了SOTA的结果,证明了该方法的优越性。同时在Table 4和5中,在两个中文场景文本数据集上也取得了SOTA的结果,证明方法可以应用于非英文的数据集上。值得注意的是,训练过程中使用的字符级别标注都是通过弱监督的形式获得的,因此具备更高的实用价值。为了验证语义特征的优势,本文评估了移除字符分割分支的性能。如表1、2、3、4和5所示,所提出的方法在文本检测和跟踪任务上都超过了不使用语义特征的方法。为了验证端到端训练的优势,本文评估了将检测和跟踪任务分离训练的性能。如表1、2和3所示,所提出的方法大幅领先双阶段的方法,这证明两个任务可以互相提供增益。Fig. 5展示了本文的部分检测和跟踪结果,可以看出文中提出的模型能够有效地检测和跟踪自然场景视频中的文本行。
免责声明:(1)本文仅代表撰稿者观点,撰稿者不一定是原文作者,其个人理解及总结不一定准确及全面,论文完整思想及论点应以原论文为准。(2)本文观点不代表本公众号立场。
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看